|
|
|
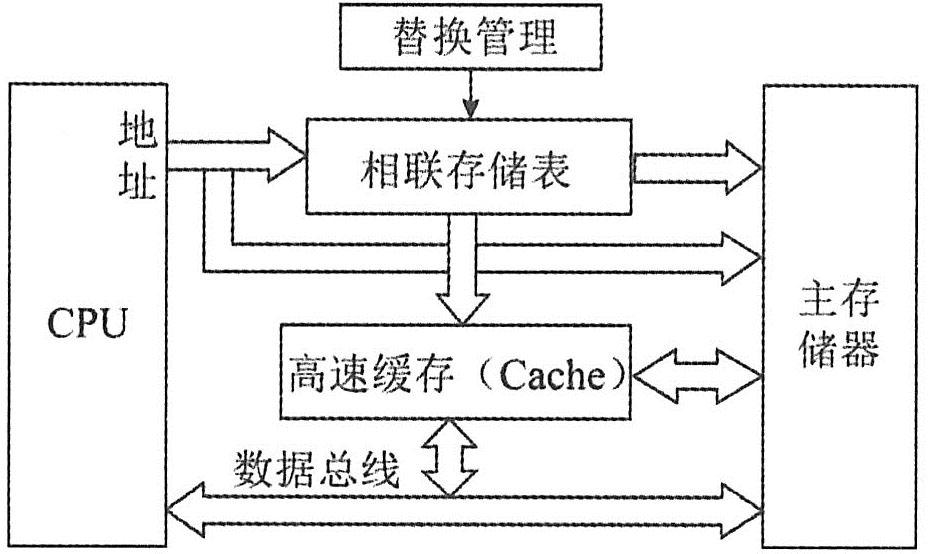
计算机中,用于存放程序或数据的存储部件有CPU内部寄存器、高速缓冲存储器(Cache)、主存储器(内存储器、内存)和辅存(外存储器、外存)。它们的存取速度不一样,从快到慢依次为寄存器→Cache→内存→辅存。一般来讲,速度越快,成本就会越高。因为成本高,所以容量就会越小。严格来说,CPU内部寄存器不算存储系统。因此,在计算机的存储系统体系中,Cache是访问速度最快的设备。
|
|
|
|
|
|
内存采用的是随机存取方式,因此简称为RAM。如果计算机断电,则RAM中的信息会丢失。内存需对每个数据块进行编码,即每个单元有一个地址,这就是所谓的内存编址问题。内存一般按照字节编址或按照字编址,通常采用的是十六进制表示。例如,假设某内存储器按字节编址,地址从A4000H到CBFFFH,则表示该存储器有(CBFFFA4000)+1个字节(28 000H字节),也就是163 840个字节(160KB)。
|
|
|
|
编址的基础可以是字节,也可以是字(字是由一个或多个字节组成的),要算地址位数,首先应计算要编址的字或字节数,然后对其求2的对数即可得到。例如,上述内存的容量为160KB,则需要18位地址来表示(217=131 072,218=262 144)。
|
|
|
|
内存这个知识点的另外一个问题就是求存储芯片的组成问题。实际的存储器总是由一片或多片存储器配以控制电路构成。其容量为W×B,W是存储单元的数量,B表示每个单元由多少位组成。如果某一芯片规格为w×b,则组成W×B的存储器需要用(W/w)×(B/b)块芯片。例如,上述例子中的存储器容量为160KB,若用存储容量为32K×8b的存储芯片构成,因为1B=8b(一个字节由8位组成),则至少需要(160K/32K)×(1B/8)=5块。
|
|
|
|
|
|
Cache的功能是提高CPU数据输入输出的速率,突破所谓的“冯·诺依曼瓶颈”,即CPU与存储系统间数据传送带宽限制。高速存储器能以极高的速率进行数据的访问,但因其价格高昂,如果计算机的内存完全由这种高速存储器组成,则会大大增加计算机的成本。因此通常在CPU和内存之间设置小容量的高速存储器Cache。Cache容量小但速度快,内存速度较低但容量大,通过优化调度算法,系统的性能会大大改善,就如同其存储系统容量与内存相当而访问速度近似于Cache。
|
|
|
|
使用Cache改善系统性能的依据是程序的局部性原理。依据局部性原理,把内存中访问概率高的内容存放在Cache中,当CPU需要读取数据时就首先在Cache中查找是否有所需内容。如果有,则直接从Cache中读取;若没有,再从内存中读取该数据,然后同时送往CPU和Cache。如果CPU需要访问的内容大多都能在Cache中找到(称为访问命中),则可以大大提高系统性能。
|
|
|
|
如果以h代表对Cache的访问命中率(“1-h”称为失效率,或者称为未命中率),t1表示Cache的周期时间,t2表示内存的周期时间,在读操作中使用“Cache+主存储器”的系统的平均周期为t3。则:
|
|
|
|
|
|
系统的平均存储周期与命中率有很密切的关系,命中率的提高即使很小也能导致性能上的较大改善。
|
|
|
|
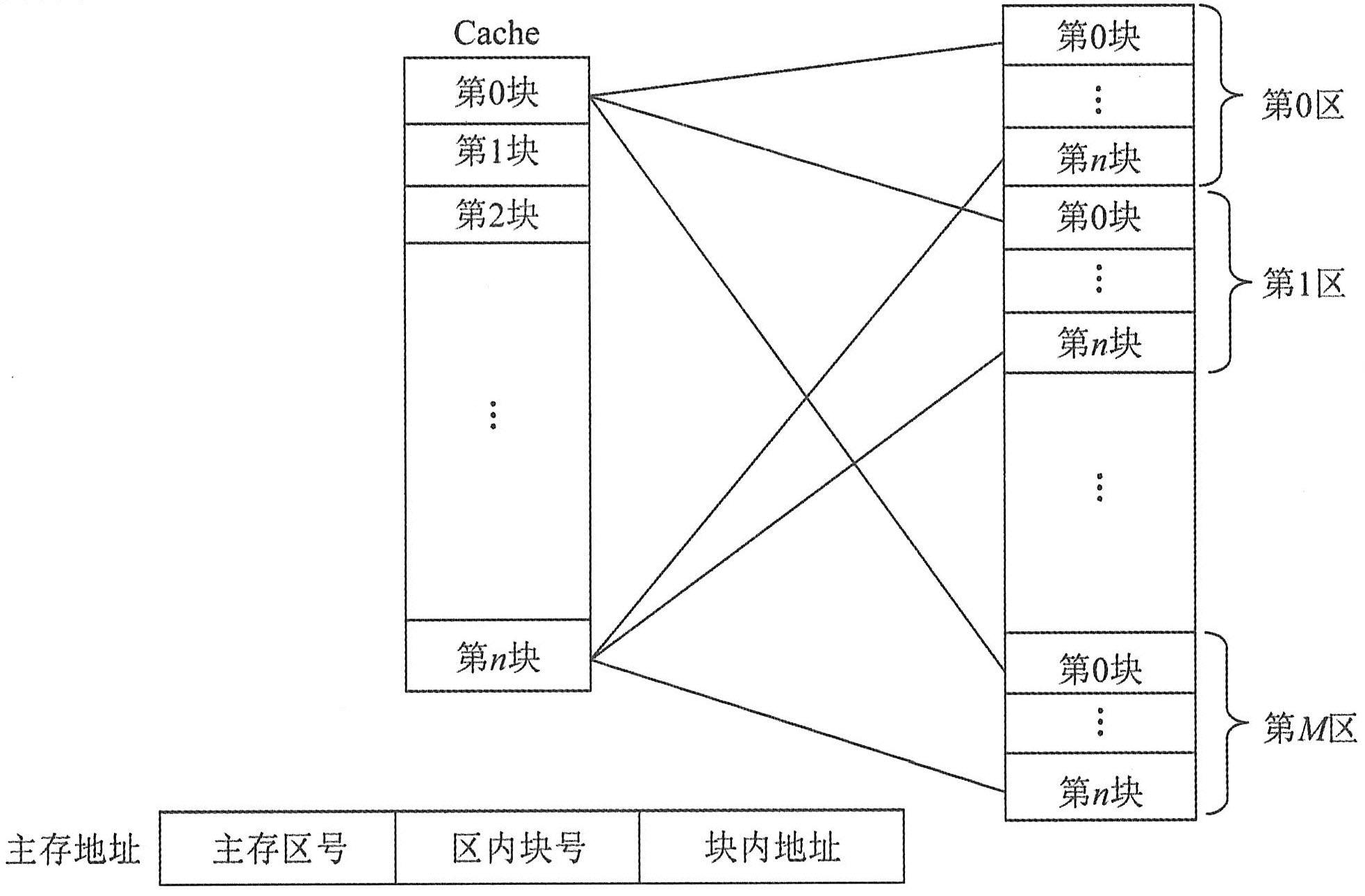
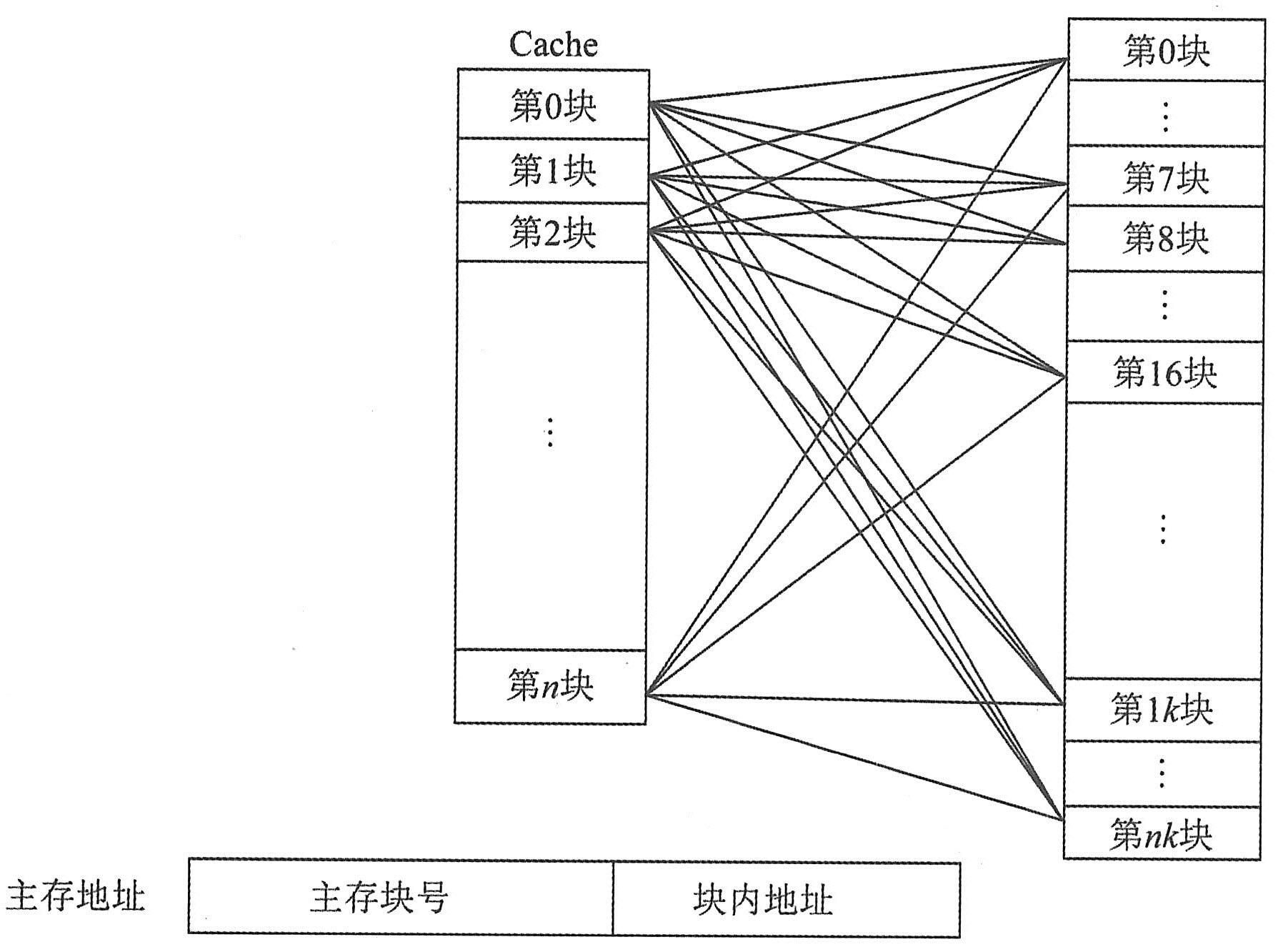
当CPU发出访存请求后,存储器地址先被送到Cache控制器以确定所需数据是否已在Cache中,若命中则直接对Cache进行访问。这个过程称为Cache的地址映射。常见的映射方法有直接映射、相联映射和组相联映射。
|
|
|
|
当Cache产生了一次访问未命中之后,相应的数据应同时读入CPU和Cache。但是当Cache已存满数据后,新数据必须淘汰Cache中的某些旧数据。最常用的淘汰算法有随机淘汰法、先进先出淘汰法(FIFO)和近期最少使用淘汰法(LRU)。
|
|
|
|
因为需要保证缓存在Cache中的数据与内存中的内容一致,相对于读操作而言,Cache的写操作比较复杂,常用的有以下几种方法。
|
|
|
|
(1)写直达(Write Through)。当要写Cache时,数据同时写回内存,有时也称为写通。
|
|
|
|
(2)写回(Write Back)。CPU修改Cache的某一行后,相应的数据并不立即写入内存单元,而是当该行从Cache中被淘汰时才把数据写回到内存中。
|
|
|
|
(3)标记法。对Cache中的每一个数据设置一个有效位,当数据进入Cache后,有效位置1;而当CPU要对该数据进行修改时,数据只需写入内存并同时将该有效位清0。当要从Cache中读取数据时需要测试其有效位:若为1则直接从Cache中取数,否则从内存中取数。
|
|
|
|
|
|
本知识点的要点是掌握与磁盘相关的最重要的概念与计算公式。
|
|
|
|
磁盘是最常见的一种外部存储器,它是由一至多个圆形磁盘组成的,其常见技术指标如下。
|
|
|
|
(1)磁道数=(外半径-内半径)×道密度×记录面数
|
|
|
|
说明:硬盘的第一面与最后一面是起保护作用的,一般不用于存储数据,所以在计算的时候要减掉。例如,6个双面的盘片的有效记录面数是6×2-2=10。
|
|
|
|
(2)非格式化容量=位密度×3.14×最内圈直径×总磁道数
|
|
|
|
说明:每个磁道的位密度是不相同的,但每个磁道的容量却是相同的。一般来说,0磁道是最外面的磁道,其位密度最小。
|
|
|
|
|
|
(4)平均数据传输速率=每道扇区数×扇区容量×盘片转速
|
|
|
|
|
|
|
|
说明:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。显然,寻道时间与磁盘的转速没有关系。
|
|
|
|
|
|
廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks,RAID)技术旨在缩小日益扩大的CPU速度和磁盘存储器速度之间的差距。其策略是用多个较小的磁盘驱动器替换单一的大容量磁盘驱动器,同时合理地在多个磁盘上分布存放数据以支持同时从多个磁盘进行读写,从而改善了系统的I/O性能。小容量驱动器阵列与大容量驱动器相比,具有成本低、功耗小和性能好等优势;低代价的编码容错方案在保持阵列的速度与容量优势的同时保证了极高的可靠性,同时也较容易扩展容量。但是由于允许多个磁头同时进行操作以提高I/O数据传输速度,因此不可避免地提高了出错的概率。为了补偿可靠性方面的损失,RAID使用存储的校验信息来从错误中恢复数据。最初,inexpensive一词主要针对当时另一种技术(Single Large Expensive Disk,SLED)而言,但随着技术的发展,SLED已是明日黄花,RAID和non-RAID皆采用了类似的磁盘技术。因此RAID现在代表独立磁盘冗余阵列(Redundant Array of Independent Disks),同时用independent来强调RAID技术所带来的性能改善和更高的可靠性。
|
|
|
|
RAID机制中共分8个级别,RAID应用的主要技术有分块技术、交叉技术和重聚技术。
|
|
|
|
(1)RAID 0级(无冗余和无校验的数据分块):具有最高的I/O性能和最高的磁盘空间利用率,易管理,但系统的故障率高,属于非冗余系统。它主要应用于那些关注性能、容量和价格而不是可靠性的应用程序。
|
|
|
|
(2)RAID 1级(磁盘镜像阵列):由磁盘对组成,每一个工作盘都有其对应的镜像盘,上面保存着与工作盘完全相同的数据拷贝,具有最高的安全性,但磁盘空间利用率只有50%。RAID 1主要用于存放系统软件、数据及其他重要文件。它提供了数据的实时备份,一旦发生故障,所有的关键数据即刻就可重新使用。
|
|
|
|
(3)RAID 2级(采用纠错海明码的磁盘阵列):采用了海明码纠错技术,用户需增加校验盘来提供单纠错和双验错功能。对数据的访问涉及阵列中的每一个盘。大量数据传输时I/O性能较高,但不利于小批量数据传输,因此实际应用中很少使用。
|
|
|
|
(4)RAID 3级和RAID 4级(采用奇偶校验码的磁盘阵列):把奇偶校验码存放在一个独立的校验盘上。如果有一个盘失效,其上的数据可以通过对其他盘上的数据进行异或运算得到。读数据很快,但因为写入数据时要计算校验位,因此速度较慢。
|
|
|
|
(5)RAID 5级(无独立校验盘的奇偶校验码磁盘阵列):与RAID 4类似,但没有独立的校验盘,校验信息分布在组内所有盘上,对于大批量和小批量数据的读写性能都很好。RAID4级和RAID 5级使用了独立存取技术,阵列中每一个磁盘都相互独立地操作,所以I/O请求可以并行处理。因此,该技术非常适合于I/O请求率高的应用,而不太适应于要求高数据传输率的应用。与其他方案类似,RAID 4级和RAID 5级也应用了数据分块技术,但块的尺寸相对大一些。
|
|
|
|
(6)RAID 6级(具有独立的数据硬盘与两个独立的分布式校验方案):在RAID 6级的阵列中设置了一个专用的、可快速访问的异步校验盘。该盘具有独立的数据访问通路,但其性能改进有限,价格却很昂贵。
|
|
|
|
(7)RAID 7级(具有最优化的异步高I/O速率和高数据传输率的磁盘阵列):是对RAID6级的改进。在这种阵列中的所有磁盘都具有较高的传输速度,有着优异的性能,是目前最高档次的磁盘阵列。
|
|
|
|
(8)RAID 10级(高可靠性与高性能的组合):由多个RAID等级组合而成,建立在RAID 0级和RAID 1级基础上。RAID 1级是一个冗余的备份阵列,而RAID 0级是负责数据读写的阵列,因此该等级又称为RAID 0+1级。由于利用了RAID 0极高的读写效率和RAID 1级较高的数据保护和恢复能力,使RAID 10级成为了一种性价比较高的等级,目前几乎所有的RAID控制卡都支持这一等级。
|
|
|