|
|
|
|
|
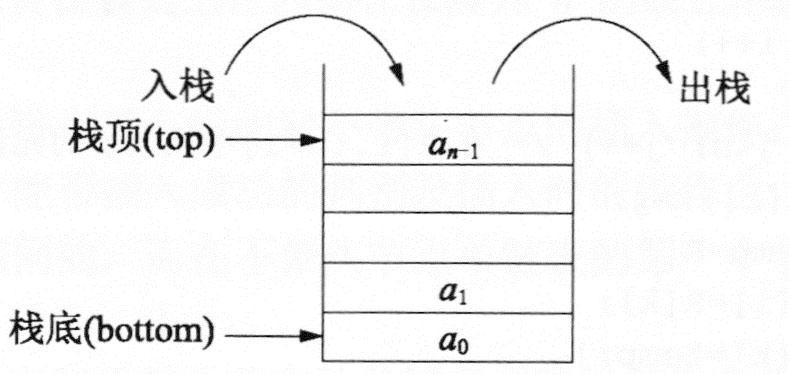
栈是只能在表的一端进行插入、删除的线性表。栈中允许插入、删除的一端称为栈顶,相反,栈中不允许插入、删除的一端称为栈底。处于栈顶位置的数据元素称为栈顶元素,不含任何数据元素的栈称为空栈。栈的特点为后进先出(Last In First Out, LIFO)。
|
|
|
|
下图是一个栈的示意图,通常用指针top指示栈顶的位置,用指针bottom指向桟底。栈顶指针top动态反映栈的当前位置。
|
|
|
|
|
|
|
|
|
|
|
|
.InitStack(&S):初始化操作,构造一个空栈S。
|
|
|
|
.StackEmpty(S):若栈S为空栈,返回1,否则返回0。
|
|
|
|
.Push(&S, e):插入元素e为新的栈顶元素。
|
|
|
|
.Pop(&S,&e):删除S的栈顶元素,并用e返回其值。
|
|
|
|
.GetTop(S,&e):用e返回S的栈顶元素。
|
|
|
|
|
|
|
|
栈的顺序存储用向量作为栈的存储结构,向量S表示栈,m表示栈的大小,用指针top指向栈顶位置,S[top]表示栈顶元素,当在栈中进行插入、删除操作时,都要移动栈指针;而当top=m-1时,则栈满,当top=-1时,表示栈空。同时为了避免浪费空间可以采用双栈机制,即向量的两端为栈底。
|
|
|
|
|
|
|
|
|
|
.由于C语言的数组下标的范围从0至StackSize-1,初始化设置sq.top=-1。
|
|
|
|
.栈空条件为sq.top=-1,栈满条件为sq.top=StackSize-1。
|
|
|
|
|
|
.元素压栈的规则为:在栈不满时,先改变栈顶指针(top=top+1),再压栈。出栈时,在桟非空时,先取栈顶元素的值,再修改栈顶指针(top=top-1)。
|
|
|
|
|
|
|
|
1)初始化InitStack(SqStack *S)
|
|
|
|
|
|
2)判空StackEmpty(SqStack S)
|
|
|
|
|
|
3)压栈Push(SqStack *S, ElemType e)
|
|
|
|
|
|
4)出栈Pop(SqStack *S, ElemType *e)
|
|
|
|
|
|
5)取栈顶GetTop(SqStack *S, ElemType*e)
|
|
|
|
|
|
6)清栈ClearStack(SqStack *S)
|
|
|
|
|
|
|
|
栈的链式存储也叫链栈,我们把插入和删除均在链表表头进行的链表称为链栈。链栈也分有头节点和无头节点两种。带头节点的链栈操作比较方便。
|
|
|
|
|
|
|
|
|
|
.栈以链表的形式出现,链表(不带头节点)首指针为S,即栈顶为S,链表尾节点为栈底。
|
|
|
|
.初始化时,S=NULL(不带头节点);S=(LStack *),malloc(sizeof(LStack)),S→next=NULL(带头节点)。
|
|
|
|
.栈顶指针的引用为S(不带头节点)或S→next(带头节点),栈顶元素的引用为S→data(不带头节点)或S→next→data(带头节点)。
|
|
|
|
.栈空条件为S==NULL(不带头节点)或S→next=NULL(带头节点)。
|
|
|
|
.进栈操作和出栈操作与单链表在开始节点的插入和删除操作一致。
|
|
|
|
|
|
1)初始化initstack(LStack *S)
|
|
|
|
|
|
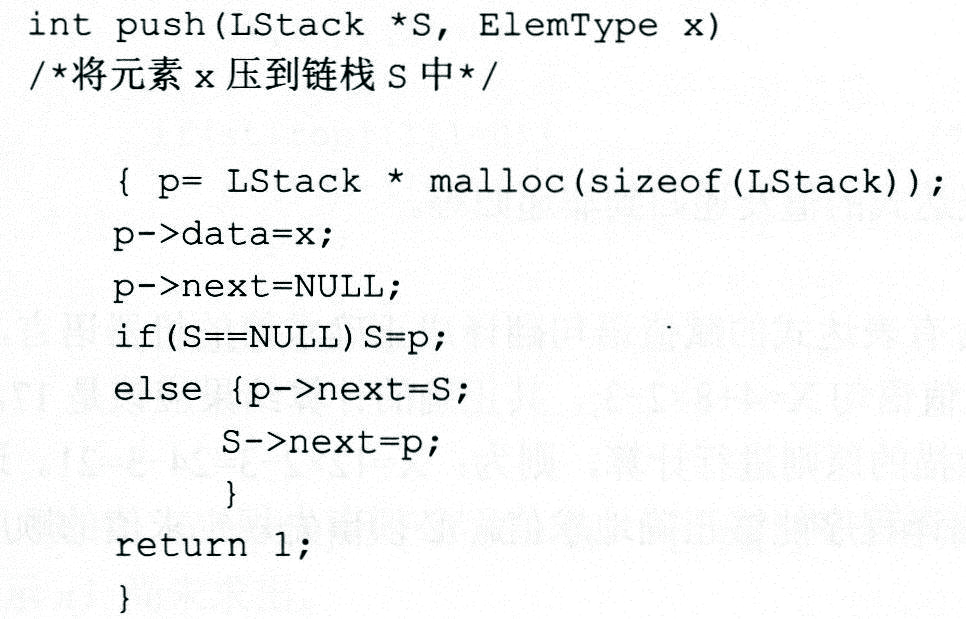
2)压栈(入栈)push(LStack *S, ElemType x)
|
|
|
|
|
|
3)退栈(出栈)pop(LStack *S, ElemType *x)
|
|
|
|
|
|
4)读栈顶元素gettop(LStack *S, ElemType *x)
|
|
|
|
|
|
|
|
|
|
|
|
栈具有广泛的应用,例如,求表达式的值及递归到非递归等。
|
|
|
|
|
|
在源程序编译中,若要把一个含有表达式的赋值语句翻译成正确求值的机器语言,首先应正确地解释表达式。例如,对赋值语句X=4+8×2-3;,其正确的计算结果应该是17,但若在编译程序中简单地按自左向右扫描的原则进行计算,则为:X=12×2-3=24-3=21。这个结果显然是错误的。因此,为了使编译程序能够正确地求值,必须事先规定求值的顺序和规则。通常采用运算符优先法。
|
|
|
|
|
|
将一个递归算法转换为功能等价的非递归算法有很多方法,可以使用栈保存中间结果。其一般形式如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其中,st[top][0]用于存放n值,st[top][1]用于存放n!值,在初始时,设置st[top][1]为0,表不n!尚未求出。
|
|
|