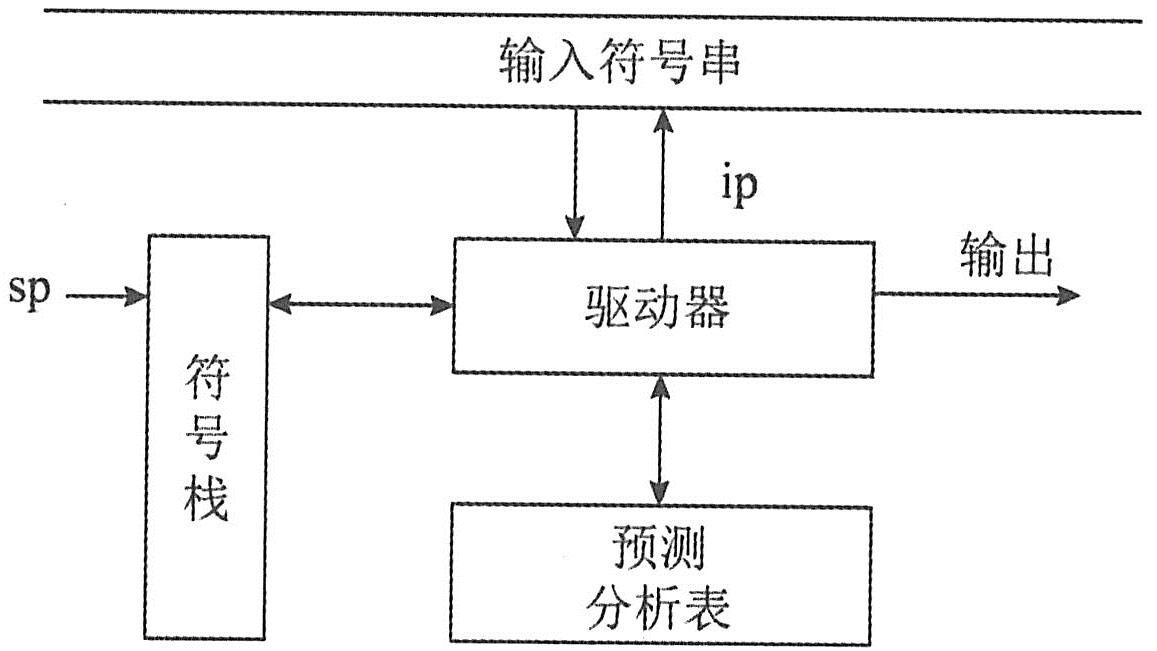
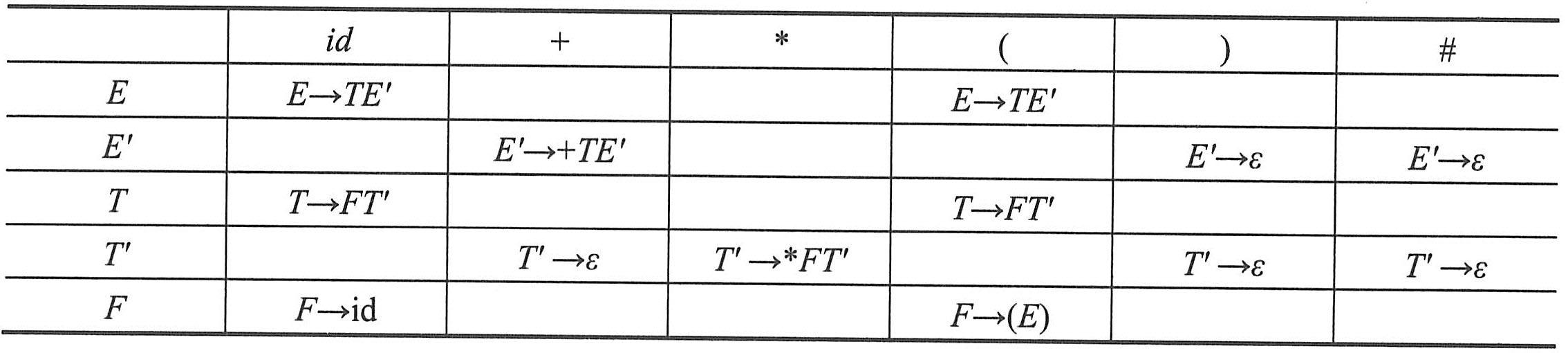
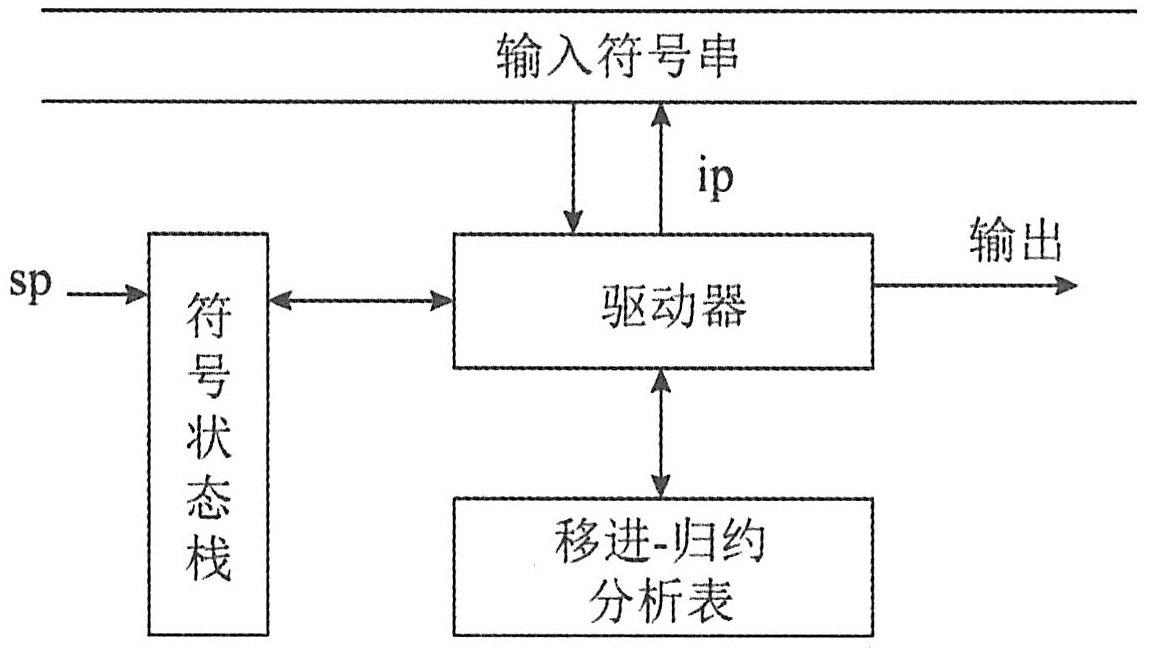
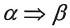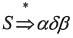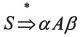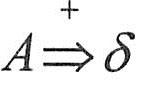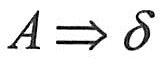|
|
|
嵌入式软件开发环境起初主要由专门开发工具的公司提供,这些公司根据不同操作系统和不同处理器版本进行专门定制,如美国Microtec公司的交叉开发工具曾经被VRTX、pSOS等定制采用。随着用户对开发工具套件的需求增加,一些著名的操作系统供应商开始发展本系列操作系统产品的开发工具套件,如WindRiver公司的Tornado、微软的Windows CE嵌入式开发工具包等。
|
|
|
|
在国际上,嵌入式软件开发环境的另一支研发队伍是GNU。GNU在因特网上提供免费的相关研究和开发成果,成为自主开发嵌入式软件开发环境的重要资源。一些公司已在GNU软件的基础上,经过集成、优化和测试,推出更加成熟、稳定的商业化嵌入式软件开发环境。
|
|
|
|
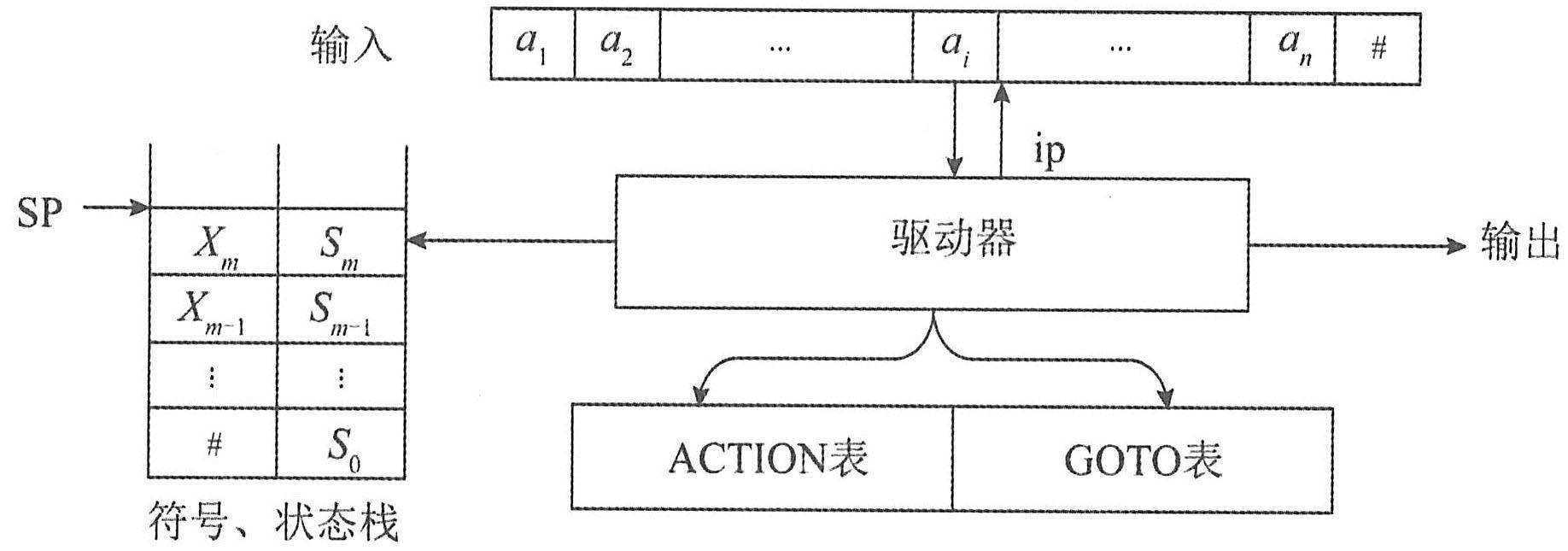
随着嵌入式系统的发展,嵌入式软件开发环境越来越重要,它直接影响到嵌入式软件的开发效率和质量。目前的开发环境已向开放性、集成化、可视化和智能化的方向发展,将各种类型且功能强大的软件工具,如编辑器、编译器、连接器、调试器、版本管理、用户界面等,有机地集成在一个统一的集成开发环境(Integrated Development Environment,IDE)中。
|
|
|
|
|
|
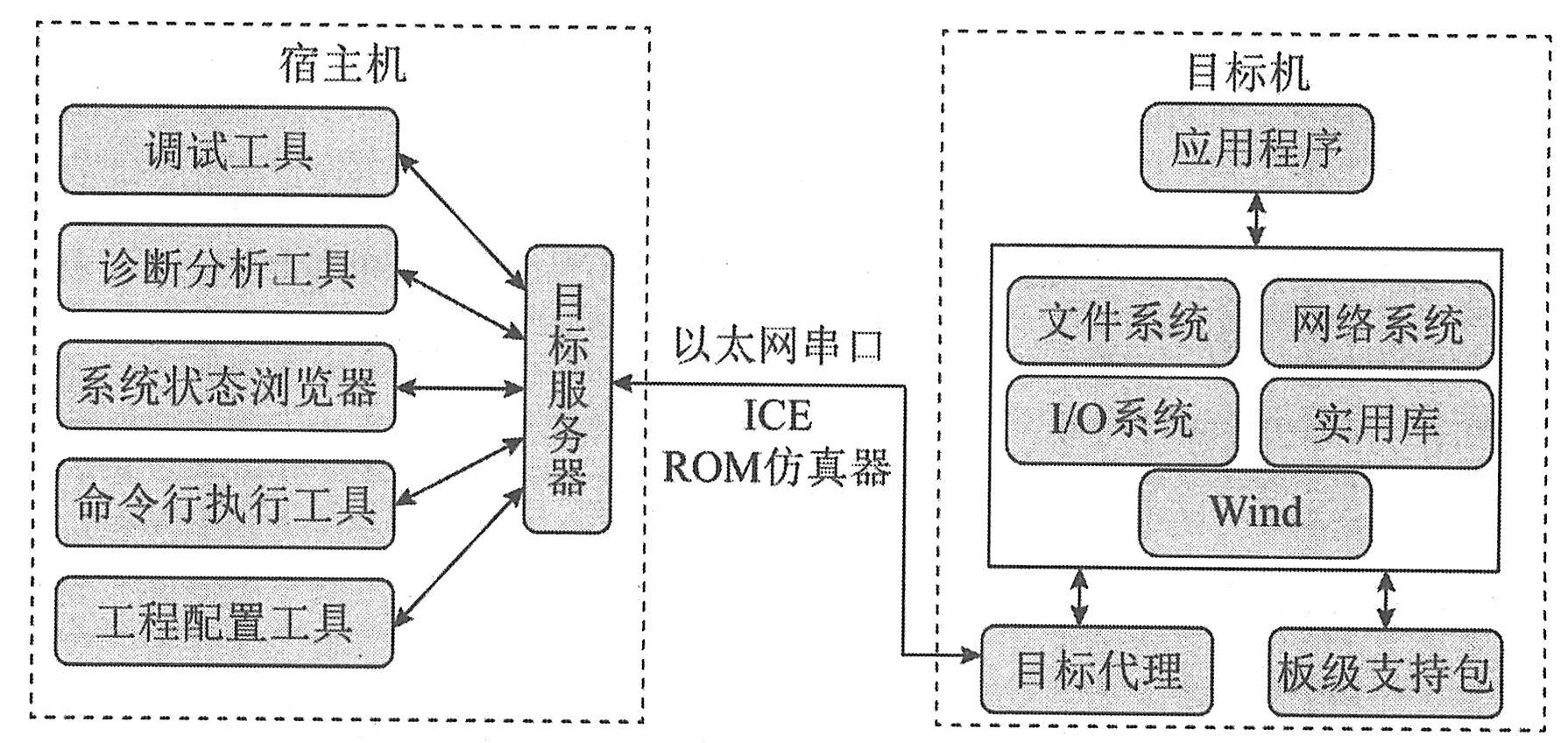
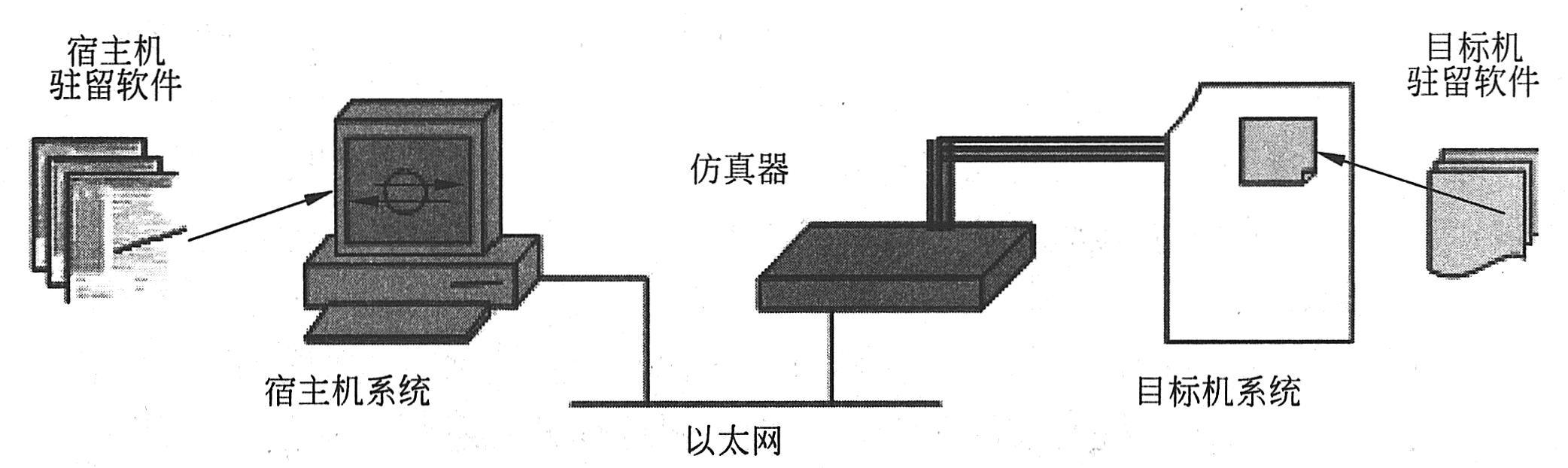
Tornado是WindRiver公司推出的一个集成开发环境。它由三个高度集成的部分组成:运行在宿主机和目标机上的交叉开发工具和实用程序;运行在目标机上的实时操作系统VxWorks;用来连接宿主机和目标机的各种通信介质,如以太网、串口、在线仿真器ICE或ROM仿真器等。
|
|
|
|
Tornado提供的交叉开发工具和实用工具主要有:源代码编辑工具、图形化的交叉调试工具、工程配置工具、集成仿真工具、诊断分析工具、C/C++编译工具、宿主机-目标机连接配置工具、目标机系统状态浏览工具、命令行执行工具、多语言浏览工具及图形化内核配置工具等。在Tornado中,宿主机上的工具与目标机之间的通信由目标服务器和目标代理共同完成。如下图所示,在形式上目标代理是VxWorks上的一个任务。调试命令通过宿主机上的目标服务器发送给目标代理。这些调试请求决定了目标代理应如何控制目标机上的其他任务。
|
|
|
|
|
|
|
|
.图形化的交叉调试器CrossWind/WDB:支持任务级和系统级两种调试方式,支持混合源代码和汇编代码显示,支持多目标同时调试,具有良好的图形用户界面。
|
|
|
|
.工程配置工具Project:用于对VxWorks操作系统及其组件进行自动配置,进行依赖性分析和代码容量计算,自动生成Makefile文件。
|
|
|
|
.集成仿真工具VxSim:提供与真实目标机完全一致的调试和仿真运行环境。
|
|
|
|
.诊断分析工具WindView:一个图形化的动态诊断和分析工具,主要是向开发者提供在目标机上运行的应用程序的许多详细情况。
|
|
|
|
.C/C++编译工具:Tornado提供以下支持C语言和C++语言的工具和类库:Diab C/C++编译器、GNU C/C++编译器及iostreams类库。
|
|
|
|
.宿主机-目标机连接配置工具Launcher:位于Tornado环境的最上层,开发者可以通过它来设置开发环境。
|
|
|
|
.目标机系统状态浏览工具Browser:一个图形化工具,能随时提供目标系统的全面状态信息。
|
|
|
|
.命令行执行工具WindSh:一个功能强大的命令行解释器,可以直接解释、执行C语言表达式,调用目标机上的C函数及访问已在系统符号表中定义的变量。
|
|
|
|
.多语言浏览工具WindNavigator:浏览源程序代码,用图形化的方式显示函数调用关系,从而实现快速的代码定位。
|
|
|
|
.图形化内核配置工具WindConfig:通过WindConfig提供的图形向导,用户可以方便地配置VxWorks内核及其组件的参数。
|
|
|
|
|
|
(1)友好的开发环境。Tornado可以运行在不同的系统中,支持UNIX、Windows NT、Windows 98/95等。
|
|
|
|
(2)适用于开发不同类型的目标机。针对不同的目标机,Tornado为开发者提供了一个一致的图形接口和人机界面。这样,当开发人员转向新的目标机时,不必再花费时间去学习或适应新的开发工具。事实上,Tornado的所有工具都驻留在开发平台上。
|
|
|
|
(3)工具齐备,具有丰富的交叉开发工具和实用工具。
|
|
|
|
(4)开放的、可扩展的开发环境。Tornado是一个完全开放的环境,开发人员或第三方厂商可以很容易地把自己的工具集成到Tornado框架下。
|
|
|
|
|
|
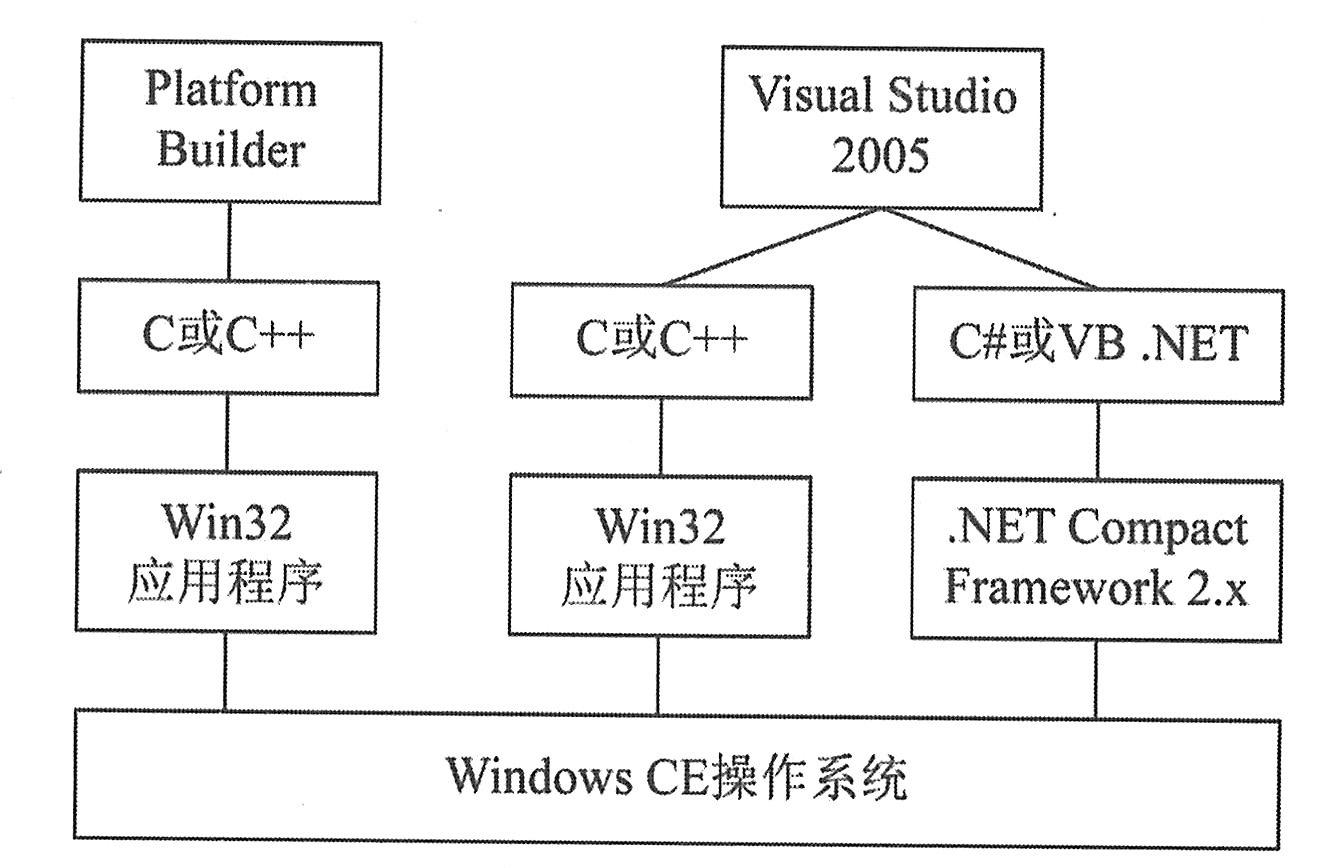
如下图所示,Windows CE应用程序开发工具包括:①Platform Builder;②eMbedded Visual Tools;③eMbedded Visual Basic;④eMbedded Visual C++。它们都是专门针对Windows CE操作系统的开发工具。
|
|
|
|
|
|
|
|
Microsoft Windows CE Platform Builder为开发商迅速创建一个嵌入式系统提供了全部相关工具。Platform Builder集成开发环境使开发者能够对新一代高度模块化的设计进行配置、创建与调试,以实现嵌入式系统的灵活性与可靠性,并与Windows和Web功能特性紧密结合。它的特点主要包括:
|
|
|
|
.通过使用改进的目标-宿主集成与连接特性来提高工作效率,节省嵌入式系统的创建时间。这些特性包括:集成化连接与下载、集成化目标控制、状态监视器、灵活的创建选择、简化操作系统配置等。
|
|
|
|
.通过使用先进的系统级调试功能来提高调试速度。Platform Builder的系统级调试器目前可为硬件辅助和系统级调试提供支持,从而大大扩展了调试功能的作用范围。具体包括:硬件辅助调试、源点级调试、新型的内核追踪器、远程系统信息、远程性能监视器、改进的调试器用户界面、调试区间等。
|
|
|
|
.提供了一个新型扩展模型,可以帮助开发商将各类特性集成到开发环境当中。包括:微处理器控制单元、嵌入式开发工具控制单元等。
|
|
|
|
Microsoft eMbedded Visual C++和eMbedded Visual Basic是开发下一代Windows CE通信、娱乐及信息访问等应用程序时的功能强大的工具。它们所提供的全面高速应用程序开发环境能够帮助开发者在各类不同设备上,迅速就相关的Windows CE应用程序进行创建、调试和部署,并且在不牺牲控制功能、性能表现及有关灵活性的前提下,提高Windows CE的开发效率。这两个产品的特点主要包括:
|
|
|
|
.开发工作效率比较高。这两个集成开发环境与传统的Windows应用开发环境非常相似,因此开发人员无需额外的培训即可熟练掌握它们的使用方法。而编程时的在线提示辅助功能(如语句完成、参数信息和语法错误检查等),能够大大提高程序员的工作效率。另外,通过创建可重复使用的ActiveX组件,可以将软件开发的复杂程度降至最低水平。
|
|
|
|
.开发过程与集成化调试得以简化。允许eMbedded Visual Tools在编译完成后,从移动设备或模拟器上的IDE中自动复制并启动相关的应用程序,从而实现应用程序的迅速测试和执行。在调试程序时,可以使用集成化调试器,当应用程序在Windows CE设备上(或模拟器内)运行的同时对其错误予以消除。另外,在测试时可以先在Windows CE设备模拟器上对应用程序进行测试,以避免高昂的硬件成本投资。
|
|
|
|
.针对Windows CE平台的全面访问。包括TCP/IP通信机制、COM组件模型、ActiveX控件、设备的API接口函数等。
|
|
|
|
.面向最新的Windows CE设备创建相应的解决方案。例如,Handheld PC Pro、Palm-size PC及Pocket PC等Windows CE设备。
|
|
|
|
.迅速、灵活的数据访问。数据存储可通过相关连接来实现与远程数据源之间的同步。
|
|
|
|
|
|
在Linux环境下也有一些很好的集成开发环境,如Kdevelop、Eclipse和Anjuta等。
|
|
|
|
|
|
Kdevelop是KDE小组开发的Linux/UNIX操作系统上的C/C++集成开发环境,为快速开发C/C++应用程序提供了强有力的开发工具。
|
|
|
|
Kdevelop的操作界面类似于微软的Visual Studio,提供编辑、编译、连接、除错、版本管理及计划管理等基本的IDE功能。此外它还内建了一个可以产生Qt图形界面的资源编辑程序。对于C++程序,它额外提供了类浏览器。此外其文件管理程序内建了所有有关KDE发展所需的文件,并提供搜寻的功能。
|
|
|
|
|
|
Eclipse是替代IBM Visual Age for Java(简称IVJ)的下一代IDE开发环境,但它未来的目标不仅仅是成为专门开发Java程序的IDE环境。根据Eclipse的体系结构,通过开发插件,它能扩展到任何语言的开发,甚至能成为图片绘制的工具。目前,Eclipse已经开始提供C语言开发的功能插件。而且它是一个开放源代码的项目,任何人都可以下载其源代码,并在此基础上开发自己的功能插件。
|
|
|
|
|
|
Anjuta是GNU/Linux平台下的C/C++集成开发环境,它主要是为了开发GTK/GNOME程序而设计的。Anjuta利用GLADE来生成优美的用户界面,加之以自己强大的源程序编辑功能,使之成为应用程序快速开发的集成开发环境。以前,人们使用GLADE做界面,用emacs或vi来编辑源程序,再用某种终端模拟器编辑开发项目。而现在使用Anjuta,所有这些繁杂零散的任务都可以在一个统一的、集成的、自然而然的环境下完成。
|
|
|