|
|
|
|
|
编译程序的功能是把用高级语言书写的源程序翻译成与之等价的目标程序。编译过程划分成词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成6个阶段,实际的编译器可能会将其中的某些阶段结合在一起进行处理,比如说表格管理和出错处理与上述6个阶段都有联系。
|
|
|
|
|
|
词法分析阶段的任务是对源程序从前到后(从左到右)逐个字符进行扫描,从中识别出一个个"单词"符号。"单词"符号是程序设计语言的基本语法单位,如关键词、标识符等。词法分析程序输出的"单词"常常采用二元组的方式,即单词类别和单词自身的值。
|
|
|
|
|
|
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如"表达式""语句"和"程序"等。
|
|
|
|
词法分析和语法分析本质上都是对源程序的结构进行分析。
|
|
|
|
|
|
语义分析阶段主要是审查源程序是否存在语义错误,并收集类型信息供后面的代码生成阶段使用,只有语法和语义都正确的源程序才能翻译成正确的目标代码。语义分析的一个主要工作是进行类型分析和检查。
|
|
|
|
|
|
中间代码是一种结构简单且含义明确的记号系统,可以有多种形式。中间代码的设计原则主要有两点:一是容易生成;二是容易被翻译成目标代码。中间代码生成阶段的工作就是根据语义分析的输出生成中间代码。
|
|
|
|
|
|
|
|
代码优化阶段的任务是对前阶段产生的中间代码进行变换或进行改造,目的是使生成的目标代码更为高效,即省时间和省空间。优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。
|
|
|
|
|
|
目标代码生成阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。这是编译的最后阶段,它的工作与具体的机器密切相关。
|
|
|
|
|
|
符号表管理阶段的任务是在符号表中记录源程序中各个符号的必要信息,以辅助语义的正确性检查和代码生成。符号表的建立可以始于词法分析阶段,也可以放到语法分析阶段,但符号表的使用有时会延续到目标代码的运行阶段。
|
|
|
|
|
|
用户编写的源程序中的错误大致可分为静态错误和动态错误。动态错误也称为动态语义错误,指程序中包含的逻辑错误。静态错误是指编译阶段发现的程序错误,可分为语法错误和静态语义错误。出错处理程序的任务包括检查错误、报告出错信息、排错、恢复编译工作。
|
|
|
|
|
|
|
|
描述语言语法结构的形式规则称为文法。文法G是一个四元组,可表示为G=(VN,VT,P,S),其中VT是一个非空有限集,其中的每个元素称为一个终结符;VN是一个非空有限集,其每个元素称为非终结符。VN∩VT=?。P是产生式的有限集合,每个产生式是形如α→β的规则,其中α称为产生式的左部,β称为产生式的右部。S∈VN,称为开始符号,它至少要在一条产生式中作为左部出现。
|
|
|
|
|
|
乔姆斯基把文法分成4种类型,即0型、1型、2型和3型。
|
|
|
|
|
|
(1)1型文法也称为上下文有关文法,这种文法意味着对非终结符的替换必须考虑上下文,并且一般不允许替换成ε串,此文法对应于线性有界自动机。
|
|
|
|
(2)2型文法是上下文无关文法,对非终结符的替换无须考虑上下文,它对应于下推自动机。
|
|
|
|
(3)3型文法等价于正规式,因此也称为正规文法或线性文法,它对应于有限状态自动机。
|
|
|
|
|
|
|
|
(1)推导和直接推导。从文法的开始符号S出发,反复使用产生式,将产生式左部的非终结符替换为右部的文法符号序列,直至产生一个终结符的序列时为止。若有产生式α→β∈P,γ,δ∈V*,则γαδ?γβδ称为文法G中的一个直接推导。
|
|
|
(2)直接归约和归约。若文法G中有一个直接推导α?β,则称α是β的一个直接归约;若文法G中有一个推导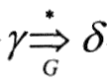 ,则称γ是δ的一个归约。 ,则称γ是δ的一个归约。
|
|
|
(3)句型和句子。若文法G的开始符号为S,那么,从开始符号S能推导出的符号串称为文法的一个句型,即α是文法G的一个句型,当且仅当有以下推导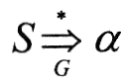 ,α∈V*,若X是文法G的一个句型,且X∈V*T,则称X是文法G的一个句子。 ,α∈V*,若X是文法G的一个句型,且X∈V*T,则称X是文法G的一个句子。
|
|
|
|
(4)语言。从文法G的开始符号出发,所能推导出的句子的全体称为文法G产生的语言,记为L(G)。
|
|
|
|
(5)文法的等价。若文法G,与文法G2产生的语言相同,即L(G1)=L(G2),则称这两个文法是等价的。
|
|
|
|
|
|
|
|
对于字母表∑,其上的正规表达式(也称正则表达式,简称正规式)及其表示的正规集可以递归定义如下。
|
|
|
|
(1)ε是一个正规式,它表示集合L(ε)={ε}。
|
|
|
|
(2)若a是∑上的字符,则a是一个正规式,它所表示的正规集为{a}。
|
|
|
|
(3)若正规式r和s分别表示正规集L(r)和L(s),则
|
|
|
|
|
|
|
|
|
|
|
|
仅由有限次地使用上述3个步骤定义的表达式才是∑上的正规式,其中运算符"|"".""*"分别称为"或""连接"和"闭包"。若两个正规式表示的正规集相同,则认为两者等价。
|
|
|
|
|
|
有限自动机是一种识别装置的抽象概念,它能够正确地识别正规集。
|
|
|
|
|
|
一个确定的有限自动机(DFA)是个五元组:(S,∑,f,s0,Z),其中:
|
|
|
|
|
|
②∑是一个有限字母表,其每个元素称为一个输入字符。
|
|
|
|
|
|
|
|
|
|
一个DFA可以用两种直观的方式表示,即状态转换图和状态转换矩阵。状态转换图简称为转换图,它是一个有向图。DFA中的每个状态对应转换图中的一个节点,DFA中的每个转换函数对应图中的一条有向弧,若转换函数为f(A,a)=Q,则该有向弧从节点A出发,进入节点Q,字符a是弧上的标记。状态转换矩阵可以用一个二维数组M表示,矩阵元素的行下标表示状态,列下标表示输入字符,M[A,a]的值是当前状态为A、输入为a时应转换到的下一状态。在转换矩阵中,一般以第一行的行下标所对应的状态作为初态,而终态则需要特别指出。
|
|
|
|
|
|
一个不确定的有限自动机(NFA)也是一个五元组,它与确定的有限自动机的区别如下。
|
|
|
|
①f是从S×∑→2S上的映像。对于S中的一个给定状态及输入符号,返回一个状态的集合。
|
|
|
|
|
|
|
|
实际上,对于每个NFAM,都存在一个DFAN,且L(M)=L(N)。
|
|
|
|
对于任何两个有限自动机M1和M2,如果L(M1)=L(M2),则称M1和M2是等价的。
|
|
|
|
|
|
设NFAN=(S,∑,f,s0,Z),与之等价的DFAM=(S',∑,f',q0,Z'),用子集法将非确定的有限自动机确定化的算法步骤如下。
|
|
|
|
(1)求出DFAM的初态q0,此时S'仅含初态q0,并且没有标记。
|
|
|
|
(2)对于S'中尚未标记的状态qi={si1,si2,…,sim}和sij∈(j=1,2,…,m)进行下述处理。
|
|
|
|
|
|
②对于每个a∈∑,令T=f(si1,si2,…,sim,a),qj=ε_CLOSURE(T)。
|
|
|
|
③若qi尚不在S'中,则将qj作为一个未加标记的新状态添加到S',并把状态转换函数f'(qi,a)=qj添加到DFAM。
|
|
|
|
(3)重复步骤(2),直到S'中不再有未标记的状态时为止。
|
|
|
|
|
|
注:若I是NFAN的状态集合的一个子集,其中ε_CLOSURE(I)的定义如下。
|
|
|
|
①状态集I的ε_CLOSURE(I)是一个状态集。
|
|
|
|
②状态集I的所有状态属于ε_CLOSURE(I)。
|
|
|
|
③若s在I中,那么从s出发经过任意条ε弧到达的状态s'都属于ε_CLOSURE(I)。
|
|
|
|
从NFA转换得到的DFA不一定是最简化的,可以通过等价变换将DFA进行最小化处理。
|
|
|
|
|
|
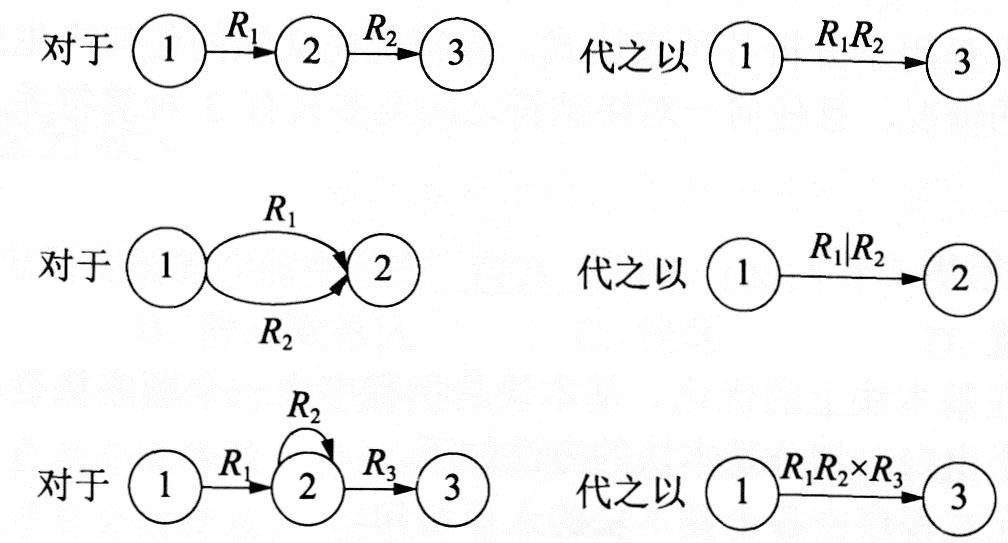
(1)对于∑上的NFAM,可以构造一个∑上的正规式R,使得L(R)=L(M)。
|
|
|
|
|
|
|
|
②按下图所示的方法逐步消去M中的除x和y的所有节点。
|
|
|
|
|
|
|
|
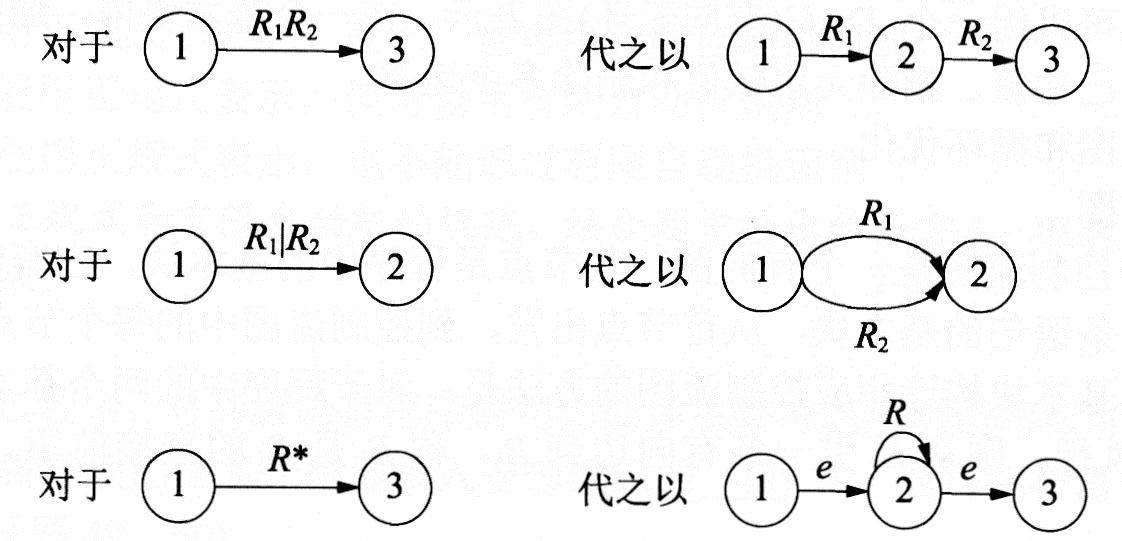
(2)对于∑上的每一个正规式R,可以构造一个∑上的NFAM,使得L(M)=L(R)。
|
|
|
|
|
|
|
|
|
|
|
|
②通过对正规式R进行分裂并加入新的节点,逐步把图转变成每条弧上的标记是∑上的一个字符或ε,转换规则如下图所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(2)为每个正规式构造一个NFA,用于识别正规式所表示的正规集。
|
|
|
|
|
|
|
|
|
|
|
|
语法分析的任务是根据语言的语法规则,分析单词串是否构成短语和句子,同时检查和处理程序中的语法错误。根据产生语法树的方向,语法分析可分为自底向上和自顶向下两类。
|
|
|
|
自顶向下的分析是对给定的符号串,试图自顶向下地为其构造一棵语法树,或者说从文法的开始符号出发,为其构造一个最佳推导。
|
|
|
|
自底向上的分析是对给定的符号串,试图自底向上地为其构造一棵语法树,或者说从给定的符号串本身出发,试图将其归约为文法的开始符号。
|
|
|
|
算符优先文法属于自底向上的分析法,它利用各个算符间的优先关系和结合规则来进行语法分析,特别是用于分析各种表达式。算符优先文法的任何产生式的右部都会出现两个非终结符相邻的情况,且任何一对终结符之间至多只有3种算符关系,即">""<"和"="之一成立。
|
|
|
|
|
|
|
|
局部优化是在基本块上的优化。基本块是指程序中一个顺序执行的语句序列,其中只有一个入口和一个出口。划分基本块的方法如下。
|
|
|
|
|
|
(2)对每一入口语句,构造其所属的基本块。它是由该语句到下一入口语句(不包括下一入口语句),或到一条转移语句(包括该转移语句),或到一条停语句(包括该停语句)之间的语句序列组成的。
|
|
|
|
(3)凡未被纳入某一基本块的语句,都是程序中控制流程无法到达的语句,因而也是不会被执行到的语句,因此可以把它们删除。
|
|
|
|
一个基本块可以用一个DAG(有向无环)图表示。在一个基本块内,通常可进行以下3种优化,即合并已知量、删除无用赋值和删除多余运算。
|
|
|
|
|
|
|
|
一个程序的控制流图是一个有向图,其节点是程序中的基本块,它有唯一的首节点,即包含程序第一条语句的基本块,从首节点出发,到控制流图中的每个节点都存在路径。
|
|
|
|
由程序的各基本块构造相应控制流图的方法是:对于程序中的两个基本块Bi和Bj,若Bj紧接着Bi被执行,则从Bi引一条有向边到Bj,称Bi是Bj的直接前驱,Bj是Bi的直接后继。
|
|
|
|
|
|
循环就是控制流图中具有唯一入口节点的强连通子图,从循环外进入循环时,必须首先经过循环的入口节点。
|
|
|
|
基于循环的优化处理有代码外提、强度削弱、删除归纳变量等。
|
|
|
|
|
|
代码生成器以经过语义分析或优化后的中间代码为输入,以特定的机器语言或汇编代码为输出。代码生成主要考虑以下问题,即中间代码形式、目标代码形式、寄存器的分配、计算次序的选择。
|
|
|