|
|
|
|
|
对于字母表∑,其上的正规表达式(也称正则表达式,简称正规式)及其表示的正规集可以递归定义如下。
|
|
|
|
(1)ε是一个正规式,它表示集合L(ε)={ε}。
|
|
|
|
(2)若a是∑上的字符,则a是一个正规式,它所表示的正规集为{a}。
|
|
|
|
(3)若正规式r和s分别表示正规集L(r)和L(s),则
|
|
|
|
|
|
|
|
|
|
|
|
仅由有限次地使用上述3个步骤定义的表达式才是∑上的正规式,其中运算符"|"".""*"分别称为"或""连接"和"闭包"。若两个正规式表示的正规集相同,则认为两者等价。
|
|
|
|
|
|
有限自动机是一种识别装置的抽象概念,它能够正确地识别正规集。
|
|
|
|
|
|
一个确定的有限自动机(DFA)是个五元组:(S,∑,f,s0,Z),其中:
|
|
|
|
|
|
②∑是一个有限字母表,其每个元素称为一个输入字符。
|
|
|
|
|
|
|
|
|
|
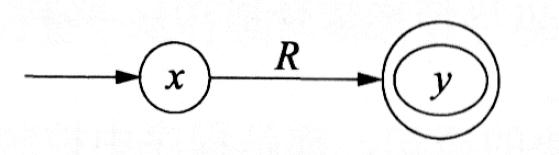
一个DFA可以用两种直观的方式表示,即状态转换图和状态转换矩阵。状态转换图简称为转换图,它是一个有向图。DFA中的每个状态对应转换图中的一个节点,DFA中的每个转换函数对应图中的一条有向弧,若转换函数为f(A,a)=Q,则该有向弧从节点A出发,进入节点Q,字符a是弧上的标记。状态转换矩阵可以用一个二维数组M表示,矩阵元素的行下标表示状态,列下标表示输入字符,M[A,a]的值是当前状态为A、输入为a时应转换到的下一状态。在转换矩阵中,一般以第一行的行下标所对应的状态作为初态,而终态则需要特别指出。
|
|
|
|
|
|
一个不确定的有限自动机(NFA)也是一个五元组,它与确定的有限自动机的区别如下。
|
|
|
|
①f是从S×∑→2S上的映像。对于S中的一个给定状态及输入符号,返回一个状态的集合。
|
|
|
|
|
|
|
|
实际上,对于每个NFAM,都存在一个DFAN,且L(M)=L(N)。
|
|
|
|
对于任何两个有限自动机M1和M2,如果L(M1)=L(M2),则称M1和M2是等价的。
|
|
|
|
|
|
设NFAN=(S,∑,f,s0,Z),与之等价的DFAM=(S',∑,f',q0,Z'),用子集法将非确定的有限自动机确定化的算法步骤如下。
|
|
|
|
(1)求出DFAM的初态q0,此时S'仅含初态q0,并且没有标记。
|
|
|
|
(2)对于S'中尚未标记的状态qi={si1,si2,…,sim}和sij∈(j=1,2,…,m)进行下述处理。
|
|
|
|
|
|
②对于每个a∈∑,令T=f(si1,si2,…,sim,a),qj=ε_CLOSURE(T)。
|
|
|
|
③若qi尚不在S'中,则将qj作为一个未加标记的新状态添加到S',并把状态转换函数f'(qi,a)=qj添加到DFAM。
|
|
|
|
(3)重复步骤(2),直到S'中不再有未标记的状态时为止。
|
|
|
|
|
|
注:若I是NFAN的状态集合的一个子集,其中ε_CLOSURE(I)的定义如下。
|
|
|
|
①状态集I的ε_CLOSURE(I)是一个状态集。
|
|
|
|
②状态集I的所有状态属于ε_CLOSURE(I)。
|
|
|
|
③若s在I中,那么从s出发经过任意条ε弧到达的状态s'都属于ε_CLOSURE(I)。
|
|
|
|
从NFA转换得到的DFA不一定是最简化的,可以通过等价变换将DFA进行最小化处理。
|
|
|
|
|
|
(1)对于∑上的NFAM,可以构造一个∑上的正规式R,使得L(R)=L(M)。
|
|
|
|
|
|
|
|
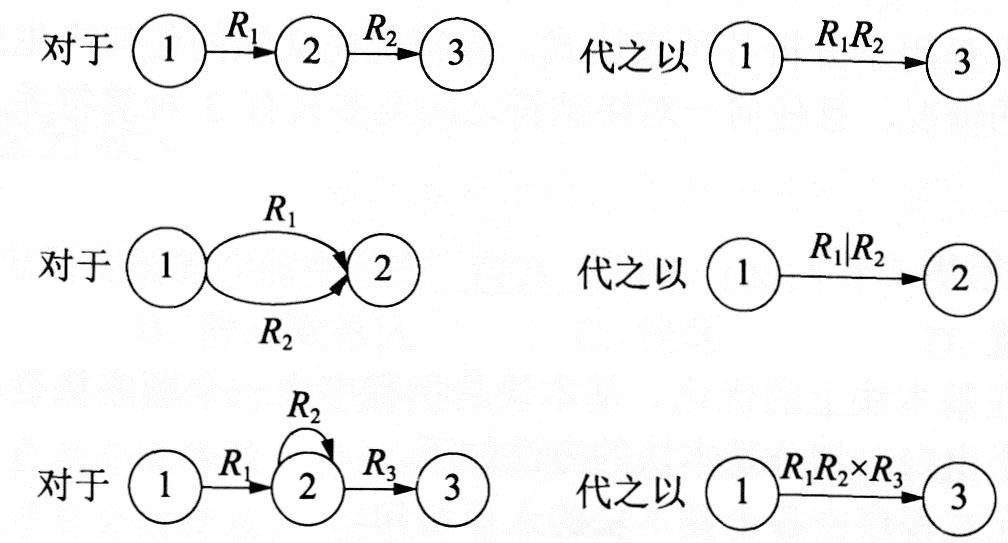
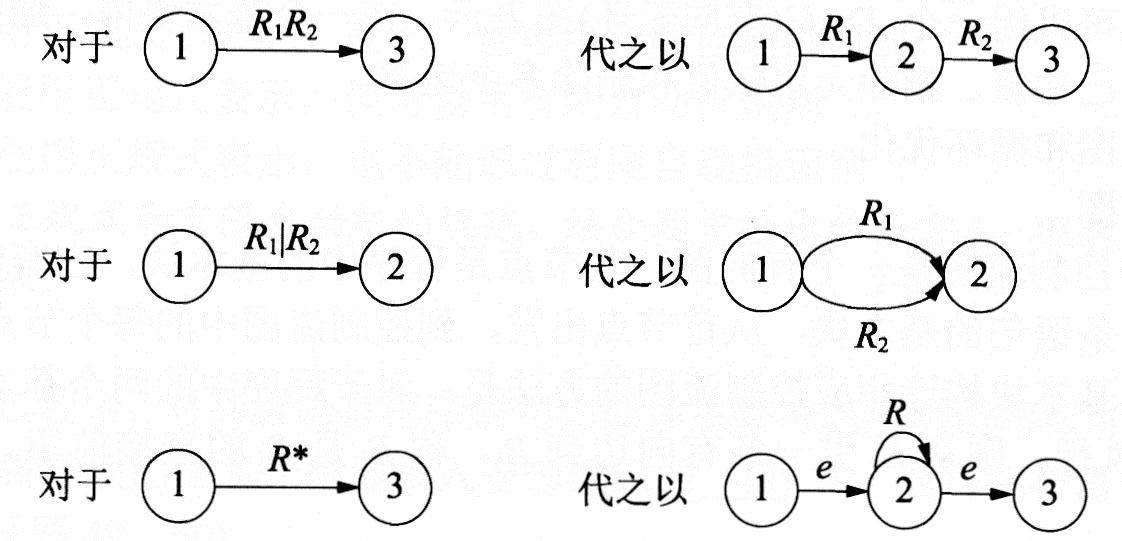
②按下图所示的方法逐步消去M中的除x和y的所有节点。
|
|
|
|
|
|
|
|
(2)对于∑上的每一个正规式R,可以构造一个∑上的NFAM,使得L(M)=L(R)。
|
|
|
|
|
|
|
|
|
|
|
|
②通过对正规式R进行分裂并加入新的节点,逐步把图转变成每条弧上的标记是∑上的一个字符或ε,转换规则如下图所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(2)为每个正规式构造一个NFA,用于识别正规式所表示的正规集。
|
|
|
|
|
|
|
|
|