|
|
|
|
知识路径: > 信息技术知识 > 新一代信息技术 > 大数据 >
|
|
|
被考次数:5次
|
|
|
被考频率:
中频率
|
|
|
总体答错率:
46%
|
|
知识难度系数:
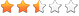
|
|
|
考试要求:
熟悉
|
|
|
相关知识点:17个
|
|
|
|
|
|
|
(1)大数据的概念。早在20世纪的1980年,著名未来学家阿尔文·托夫勒便在《第三次浪潮》一书中,将“大数据”热情地赞颂为“第三次浪潮的华彩乐章”。2008年9月《科学》(Science)杂志发表了一篇文章“BigData:Science in the Petabyte Era”。“大数据”这个词开始被广泛传播。目前国内外的专家学者对大数据只是在数据规模上达成共识:“超大规模”表示的是GB级别的数据,“海量”表示的是TB级的数据,而“大数据”则是PB级别及其以上的数据。
|
|
|
|
2011年5月,在“云计算相遇大数据”为主题的EMC World 2011会议中,EMC抛出了大数据(Big Data)概念。
|
|
|
|
大数据的来源包括网站浏览轨迹、各种文档和媒体、社交媒体信息、物联网传感信息、各种程序和App的日志文件等。大数据是指无法在一定时间内用传统数据库软件工具对其内容进行抓取、管理和处理的数据集合,其具有4V特性:体量大(Volume)、多样性(Variety)、价值密度低(Value)、快速化(Velocity)的显著特征。
|
|
|
|
.体量大(Volume)。体量大指数据量巨大,而且非结构化数据的超大规模和增长快速,非结构化数据占总数据量的80%~90%,其增长比结构化数据快10倍到50倍。大数据处理的数据量是传统数据仓库的10倍到50倍。
|
|
|
|
.多样性(Variety)。多样性指数据类型包括结构化数据、半结构化数据和非结构化数据,具有很多不同形式(文本、图像、视频、机器数据),这些数据无模式或者模式不明显,并且属于不连贯的语法或句义。
|
|
|
|
.价值密度低(Value)。价值密度低指类似沙里淘金,从海量的数据里面获得对自己有用的数据,要处理大量的不相关信息。大数据同时也意味深度复杂分析,比如机器学习和人工智能,甚至可以对未来趋势与模式进行预测分析。
|
|
|
|
.快速化(Velocity)。大数据处理的数据通常指实时获取需要的信息,进行实时分析而非批量式分析,数据处理通常立竿见影而非事后见效。
|
|
|
|
(2)大数据关键技术。大数据所涉及的技术很多,主要包括数据采集、数据存储、数据管理、数据分析与挖掘4个环节。在数据采集阶段主要使用的技术是数据抽取工具ETL。在数据存储环节主要有结构化数据、非结构化数据和半结构化数据的存储与访问。结构化数据一般存放在关系数据库,通过数据查询语言(SQL)来访问;非结构化(如图片、视频、doc文件等)和半结构化数据一般通过分布式文件系统的NoSQL(Not Only SQL)进行存储。大数据管理主要使用了分布式并行处理技术,比较常用的有MapReduce,借助MapReduce编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。数据分析与挖掘是根据业务需求对大数据进行关联、聚类、分类等钻取和分析,并利用图形、表格加以展示,与ETL一样,数据分析和挖掘是以前数据仓库的范畴,只是在大数据中得以更好的利用。
|
|
|
|
.HDFS。Hadoop分布式文件系统(HDFS)是适合运行在通用硬件上的分布式文件系统,是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
|
|
|
|
.HBase。 HBase是一个分布式的、面向列的开源数据库,该技术来源于论文“Bigtable:一个结构化数据的分布式存储系统”,HBase在Hadoop之上提供了类似于Bigtable的能力。利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是Hbase是基于列的而不是基于行的模式。
|
|
|
|
.MapReduce。 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归约)”,以及它们的主要思想,都是从函数式编程语言里借来的。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上,从而实现对HDFS和HBase上的海量数据分析。
|
|
|
|
.Chukwa。 Chukwa是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在hadoop的hdfs和map/reduce框架之上的,继承了hadoop的可伸缩性和鲁棒性。Chukwa还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
|
|
|
|
|
|
大数据受到越来越多行业巨头们的关注,使得大数据渗透到更广阔的领域,除了电商、电信、金融这些传统数据丰富、信息系统发达的行业之外,在政府、医疗、制造和零售行业都有其巨大的社会价值和产业空间。各行业在大数据应用上的契合度如下图所示。
|
|
|
|
|
|
|
|
(1)互联网和电子商务行业。应用最多的是用户行为分析,主要研究对象用户在互联网、移动互联网上的访问日志、用户主体信息和外景环境信息,从而挖掘潜在客户,进行精准广告或营销。例如某电商通过用户对产品浏览信息的分析,得到大约10%的用户会在浏览该产品一周后下单,从而在该城市的物流中心进行备货,大大提高发货速度,降低仓库成本。用户日志一般包括下列几类数据:
|
|
|
|
.网站日志:用户在访问某个目标网站时,网站记录的用户相关行为信息;
|
|
|
|
.搜索引擎日志:记录用户在该搜索引擎上的相关行为信息;
|
|
|
|
.用户浏览日志:通过特定的工具和途径记录用户所浏览过的所有页面的相关信息,如浏览器日志、代理日志等;
|
|
|
|
.用户主体数据:如用户群的年龄、受教育程度、兴趣爱好等;
|
|
|
|
.外界环境数据:如移动互联网流量、手机上网用户增长、自费套餐等。
|
|
|
|
(2)电信/金融。通过对用户的通信、流量、消费等信息进行分析,判断用户的消费习惯和信用能力,可以给用户设计更贴合的产品,提升产品竞争力。
|
|
|
|
(3)政府。首先政府通过对大数据的挖掘和实时分析,可有效提高政府决策的科学性和时效性,并且能帮助政府有效削减预算开支。其次借助大数据可以使政府变得更加开放、透明和智慧。大数据可以使政府更清楚地了解公民的意愿和想法,可以提升公民的价值,还可以通过引导社会的舆论,为社会公众提供更好的服务,树立更好的政府形象。
|
|
|
|
(4)医疗。例如,某互联网公司“流感趋势”项目深受相关研究人员的欢迎,它依据网民搜索内容分析全球范围内流感等病疫传播状况,与美国疾病控制和预防中心提供的报告进行比对,事实证明两者有很大关联。社交网络为许多患者提供临床症状交流和诊治经验分享的平台,医生借此可获得在医院通常得不到的临床效果统计数据。
|
|
|
|
(5)制造。从前的制造业通常以产品为导向,以降低生产成本来决定制造业的生存和发展。而如今如果继续以这种理念来维持企业的发展,必将导致制造业的暗淡。越来越多的制造业早已明白,个性化定制将是发展的趋势,所以制造业需要处理好大数据,通过对海量数据的获取,挖掘和分析,把握客户的需求,从而交付客户喜欢的产品。
|
|
|