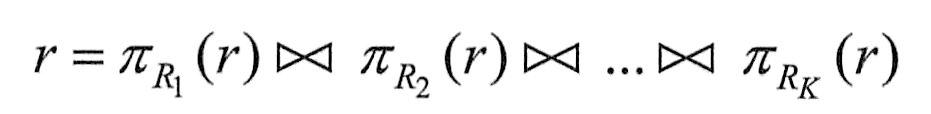|
|
|
|
知识路径: > 计算机软件与网络基础知识 > 数据库系统 > 数据模型 >
|
|
|
被考次数:16次
|
|
|
被考频率:
高频率
|
|
|
总体答错率:
45%
|
|
知识难度系数:
|
|
|
考试要求:
掌握
|
|
|
相关知识点:7个
|
|
|
|
|
设有一个关系模式R(SNAME,CNAME,TNAME TADDRESS),其属性分别表示学生姓名、选修的课程名、任课教师姓名和任课教师地址。仔细分析一下,我们就会发现这个模式存在下列存储异常的问题:
|
|
|
|
(1)数据冗余:如果某门课程有100个学生选修,那么在R的关系中就要出现100个元组,这门课程的任课教师姓名和地址也随之重复出现100次。
|
|
|
|
(2)修改异常:由于上述冗余问题,当需要修改这个教师的地址时,就要修改100个元组中的地址值,否则就会出现地址值不一致的现象。
|
|
|
|
(3)插入异常:如果不知道听课学生名单,这个教师的任课情况和家庭地址就无法进入数据库;否则就要在学生姓名处插入空值。
|
|
|
|
(4)删除异常:如果某门课程的任课教师要更改,那么原来任课教师的地址将随之丢失。
|
|
|
|
因此,关系模式R虽然只有4个属性,但却是性能很差的模式。如果把R分解成两个关系模式:R1(SNAME,CNAME)和R2(CNAME,TNAME,TADDRESS),则能消除上述的存储异常现象。
|
|
|
|
为什么会产生这些异常呢?与关系模式属性值之间的联系直接有关。在模式R中,学生与课程有直接联系,教师与课程有直接联系,而教师与学生无直接联系,这就产生了模式R的存储异常。因此,模式设计强调“每个联系单独表达”是一条重要的设计原则,把R分解成R1和R2是符合这条原则的。
|
|
|
|
|
|
设R(U)是属性U上的一个关系模式,X和Y是U的子集,r为R的任一关系,如果对于r中的任意两个元组u、v,只要有u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X,记为X→Y。
|
|
|
|
从函数依赖的定义可以看出,如果有X→U在关系模式R(U)上成立,并且不存在X的任一真子集X'使X'→U成立,那么称X是R的一个候选键。也就是X值唯一决定关系中的元组。由此可见,函数依赖是键概念的推广,键是一种特殊的函数依赖。
|
|
|
|
在R(U)中,如果X→Y,并且对于X的任何一个真子集X',都有X'→Y不成立,则称Y对X完全函数依赖。若X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。
|
|
|
|
在R(U)中,如果X→Y(Y不是X的真子集),且Y→X不成立,Y→Z,则称Z对X传递函数依赖。
|
|
|
|
设U是关系模式R的属性集,F是R上成立的只涉及U中属性的FD集,则有以下3条推理规则:
|
|
|
(1)自反性:若Y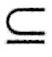 X X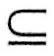 U,则X→Y在R上成立。 U,则X→Y在R上成立。
|
|
|
(2)增广性:若X→Y在R上成立,且Z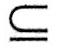 U,则XZ→YZ在R上成立。 U,则XZ→YZ在R上成立。
|
|
|
|
(3)传递性:若X→Y和Y→Z在R上成立,则X→Z在R上成立。
|
|
|
|
这里XZ,YZ等写法表示X∪Z,Y∪Z。上述三条推理规则是函数依赖的一个正确的和完备的推理系统。根据上述三条规则还可以推出其他三条常用的推理规则:
|
|
|
|
(1)并规则:若X→Y和X→Z在R上成立,则X→YZ在R上成立。
|
|
|
(2)分解规则:若X→Y在R上成立,且Z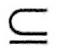 Y,则X→Z在R上成立。 Y,则X→Z在R上成立。
|
|
|
|
(3)伪传递规则:若X→Y和WY→Z在R上成立,则WX→Z在R上成立。
|
|
|
|
在关系模式R(U,F)中为F所逻辑蕴含的函数依赖全体叫做F的闭包,记作F+。
|
|
|
|
设F为属性集U上的一组函数依赖,X是U的子集,那么相对于F属性集X的闭包用X+表示,它是一个从F集使用推理规则推出的所有满足X→A的属性A的集合:
|
|
|
|
|
|
如果G+=F+,就说函数依赖集F覆盖G(F是G的覆盖,或G是F的覆盖),或F与G等价。
|
|
|
|
如果函数依赖集F满足下列条件,则称F为一个极小函数依赖集,也称为最小依赖集或最小覆盖。
|
|
|
|
|
|
(2)F中不存在这样的函数依赖X→A,使得F与F-{X→A}等价。
|
|
|
|
(3)F中不存在这样的函数依赖X→A,X有真子集Z使得F-{X→A}∪{Z→A}与F等价。
|
|
|
|
|
|
(1)第一范式(1NF):如果关系模式R的每个关系r的属性值都是不可分的原子值,那么称R是第一范式的模式,r是规范化的关系。关系数据库研究的关系都是规范化的关系。
|
|
|
|
(2)第二范式(2NF):若关系模式R是1NF,且每个非主属性完全函数依赖于候选键,那么称R是2NF模式。
|
|
|
|
(3)第三范式(3NF):如果关系模式R是1NF,且每个非主属性都不传递依赖于R的候选码,则称R是3NF。
|
|
|
|
(4)BC范式(BCNF):若关系模式R是1NF,且每个属性都不传递依赖于R的候选键,那么称R是BCNF模式。
|
|
|
上述4种范式之间有如下联系:1NF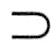 2NF 2NF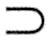 3NF 3NF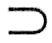 BCNF。 BCNF。
|
|
|
|
|
|
如果某关系模式存在存储异常问题,则可通过分解该关系模式来解决问题。把一个关系模式分解成几个子关系模式,需要考虑的是该分解是否保持函数依赖,是否是无损联接。
|
|
|
|
无损联接分解的形式定义如下:设R是一个关系模式,F是R上的一个函数依赖(FD)集。R分解成数据库模式δ={R1,…,RK}。如果对R中每一个满足F的关系r都有下式成立:
|
|
|
|
|
|
那么称分解δ相对于F是无损联接分解,否则称为损失联接分解。
|
|
|
|
|
|
设p={R1,R2}是R的一个分解,F是R上的FD集,那么分解p相对于F是无损分解的充分必要条件是:(R1∩R2)→(R1-R2)或(R1∩R2)→(R2-R1)。:这两个条件只要有任意一个条件成立就可以了。
|
|
|
|
设数据库模式δ={R1,…,RK}是关系模式R的一个分解,F是R上的FD集,δ中每个模式Ri上的FD集是Fi。如果{F1,F2,…,FK}与F是等价的(即相互逻辑蕴涵),那么我们称分解δ保持FD。如果分解不能保持FD,那么δ的实例上的值就可能有违反FD的现象。
|
|
|