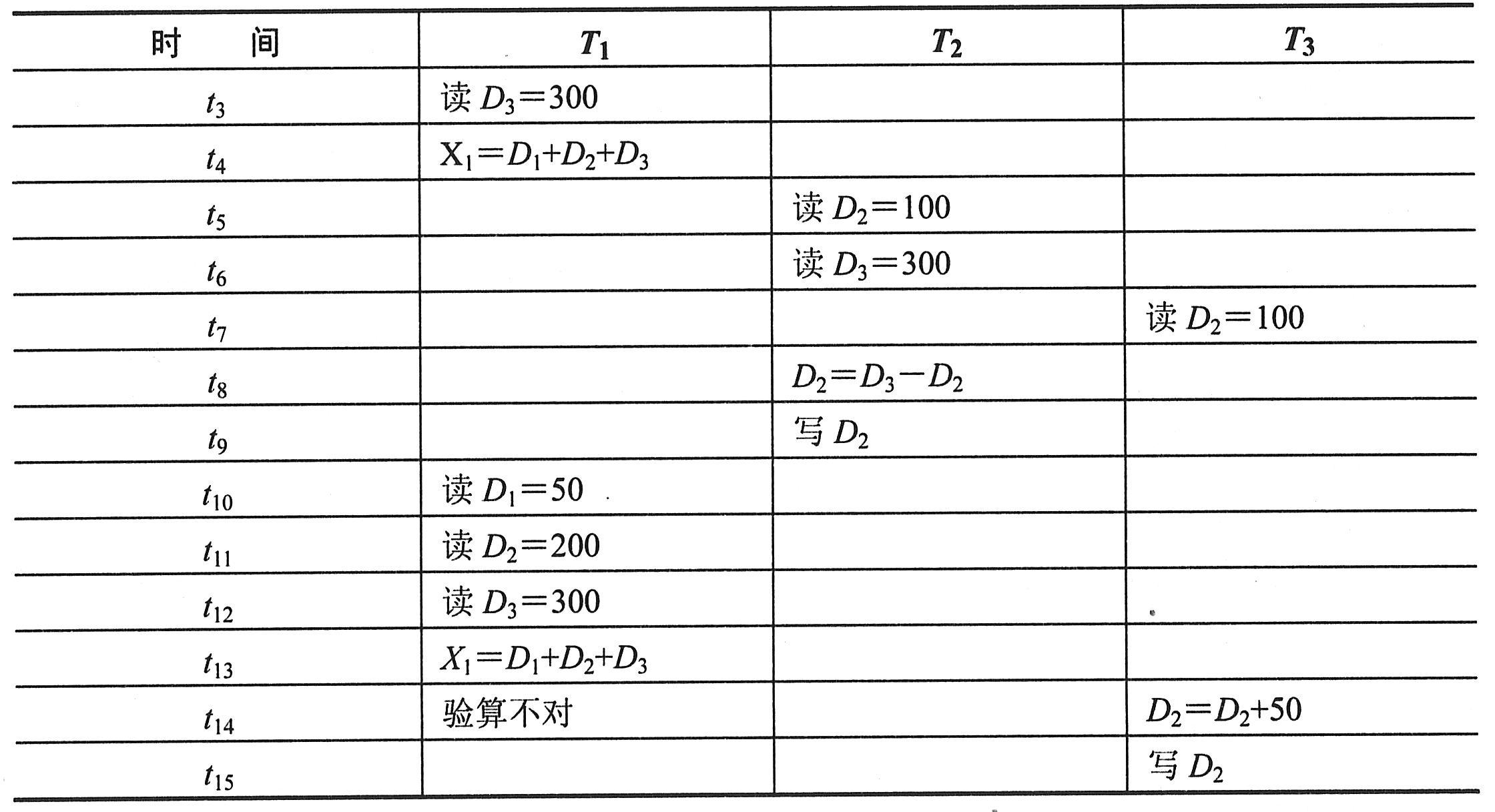
|
|
|
|
|
|
|
关系数据库应用数学方法来处理数据库中的数据。最早提出将这类方法用于数据处理的是1962年CODASYL发表的“信息代数”一文,之后有1968年David Child在7090机上实现的集合论数据结构,但系统而严格地提出关系模型的是美国IBM公司的E.F.Codd。
|
|
|
|
1970年E.F.Codd在美国计算机学会会刊Communication of the ACM上发表的题为“A Relational Model of Data for Shared Data Banks”的论文,开创了数据库系统的新纪元。以后,他连续发表了多篇论文,奠定了关系数据库的理论基础。
|
|
|
|
20世纪70年代末,关系方法的理论研究和软件系统的研制均取得了很大成果,IBM公司的San Jose实验室在IBM370系列机上研制的关系数据库实验系统System R获得成功。1981年IBM公司又宣布了具有System R全部特征的新的数据库软件产品SQL/DS问世。与System R同期,美国加州大学柏克利分校也研制了Ingres关系数据库实验系统,并由Inges公司发展成为Ingres数据库产品。
|
|
|
|
几十年来,关系数据库系统的研究取得了辉煌的成就。关系方法从实验室走向了社会,涌现出许多性能良好的商品化关系数据库管理系统(RDBMS)。如著名的IBM DB2、Oracle、Ingres、SYBASE、Informix等。数据库的应用领域迅速扩大。
|
|
|
|
|
|
(1)属性(Attribute):在现实世界中,要描述一个事务常常取若干特征来表示。这些特征称为属性。例如学生用学号、姓名、性别、系别、年龄、籍贯等属性来描述。
|
|
|
|
(2)域(Domain):每个属性的取值范围所对应一个值的集合,称为该属性的域。例如,学号的域是6位整型数;姓名的域是10位字符;性别的域为{男,女};……一般在关系数据模型中,对域还加了一个限制,所有的域都应是原子数据(atomic data)。例如,整数、字符串是原子数据,而集合、记录、数组是非原子数据。关系数据模型的这种限制称为第一范式(first normal form,简称1NF)条件。但也有些关系数据模型突破了1NF的限制,称为非1NF的。
|
|
|
|
(3)目或度(Degree):D1×D2×…×Dn的子集的称作在域D1,D2…,Dn上的关系,表示为R(D1,D2,…,Dn)。这里的R表示关系的名字,n是关系的目或度。
|
|
|
|
(4)候选码(Candidate Key):若关系中的某一属性或属性组的值能唯一标识一个元组,则称该属性或属性组为候选码。
|
|
|
|
(5)主码(Primary Key):或称主键,若一个关系有多个候选码,则选定其中一个为主码。
|
|
|
|
(6)主属性(Prime attribute):包含在任何候选码中的属性称为主属性。不包含在任何候选码中的属性称为非主属性(NonPrime attribute)。
|
|
|
|
(7)外码(Foreign key):如果关系模式R中的属性或属性组非该关系的码,但它是其他关系的码,那么该属性集对关系模式R而言是外码。
|
|
|
|
|
|
,loan-no),属性c-id是客户关系中的码,所以c-id是外码;属性loan-no是贷款关系中的码,所以loan-no也是外码。
|
|
|
|
(8)全码(All-key):关系模型的所有属性组是这个关系模式的候选码,称为全码。
|
|
|
|
例如,关系模式R(T,C,S),属性T表示教师,属性C表示课程,属性S表示学生。假设一个教师可以讲授多门课程,某门课程可以由多个教师讲授,学生可以听不同教师讲授的不同课程,那么,要想区分关系中的每一个元组,这个关系模式R的码应为全属性T、C和S,即All-key。
|
|
|
|
|
|
【定义7.1】设D1,D2,D3,…,Dn为任意集合,定义D1,D2,D3,…,Dn的笛卡儿积为:
|
|
|
|
D1×D2×D3×…×Dn={(d1,d2,d3,…,dn)|di∈Di,i=l,2,3,…,n}
|
|
|
其中集合中的每一个元素(d1,d2,d3,…,dn)叫作一个n元组(n-tuple,即n个属性的元组),元素中的每一个值di叫作元组一个分量。若Di(i=1,2,3,…,n)为有限集,其基数(Cardinal number,元组的个数)为mi(i=1,2,3,…,n),则D1×D2×D3×…×Dn的基数M为: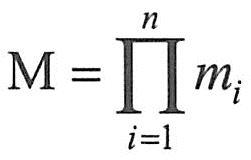 。 。
|
|
|
|
|
|
【定义7.2】D1×D2×D3×…×Dn的子集叫作在域D1,D2,D3,…,Dn上的关系,记为R(D1,D2,D3,…,Dn),称关系R为n元关系。
|
|
|
|
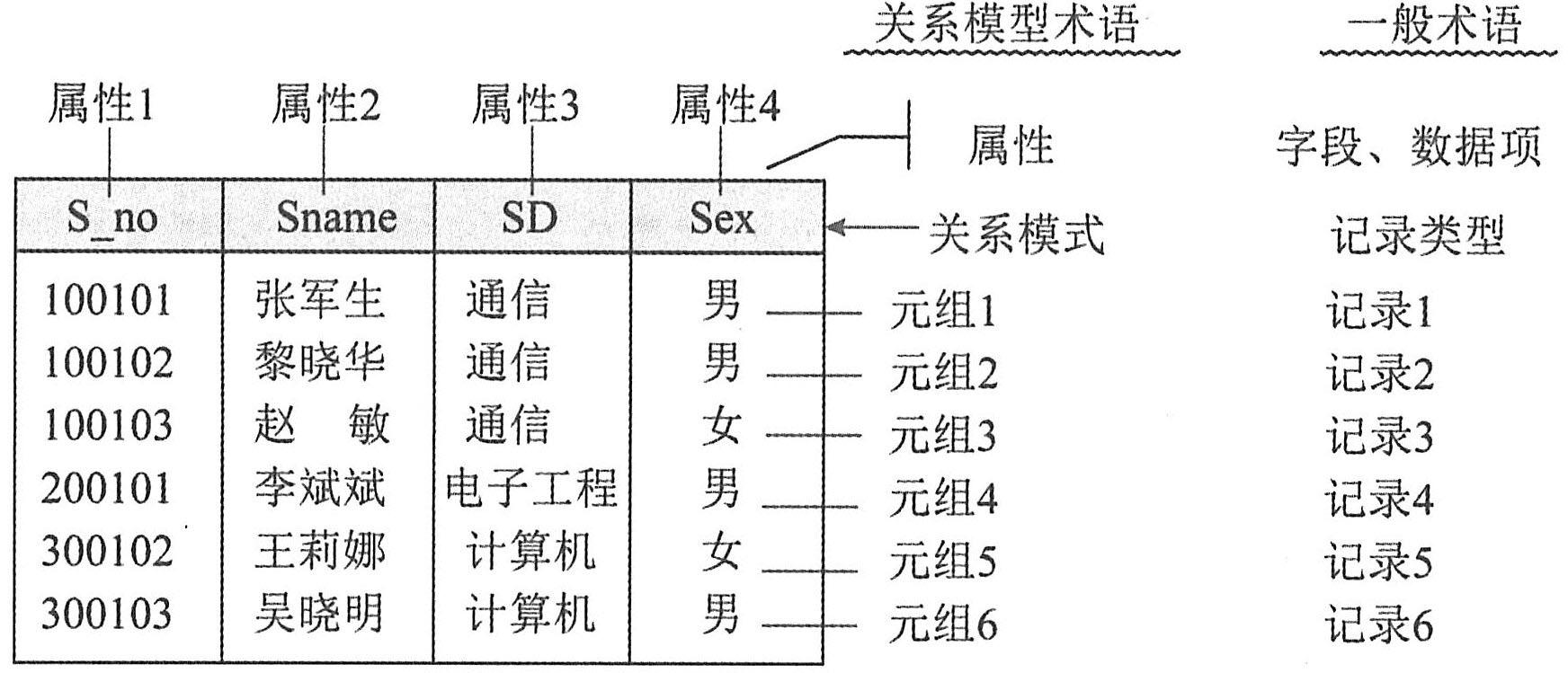
定义7.2可以得出一个关系,也可以用二维表来表示。关系中属性的个数称为“元数”,元组的个数称为“基数”。关系模型中的术语与一般术语的对应情况可以通过下图中的学生关系说明。
|
|
|
|
|
|
|
|
上图中属性S_no、Sname、SD和Sex分别表示学号、姓名、所在院系、性别。该学生关系模式可表示为:学生(
|
|
|
|
,Sname,SD,Sex);属性S_no加下画线表示该属性为主码;属性Sex的域为男、女,等等。从图中不难看出,该学生关系的元数为4,基数为6。
|
|
|
|
|
|
|
|
(1)基本关系(通常又称为基本表或基表):实际存在的表,它是实际存储数据的逻辑表示。
|
|
|
|
|
|
(3)视图表:是由基本表或其他视图表导出的表。由于它本身不独立存储在数据库中,数据库中只存放它的定义,所以常称为虚表。
|
|
|