|
|
|
|
|
声音是通过空气传播的一种连续的波,称为声波。声波在时间和幅度上都是连续的模拟信号,通常称为模拟声音(音频)信号。
|
|
|
|
|
|
|
|
.音量(也称响度):声音的强弱程度取决于声音波形的幅度,即取决于振幅的大小和强弱。
|
|
|
|
.音调:人对声音频率的感觉表现为音调的高低,取决于声波的基频。基频越低,给人的感觉越低沉,频率高则声音尖锐。
|
|
|
|
.音色:人们能够分辨具有相同音高的不同乐器发出的声音,就是因为它们具有不同的音色。一个声波上的谐波越丰富,音色越好。
|
|
|
|
|
|
对声音信号的分析表明,声音信号由许多频率不同的信号组成,通常称为复合信号,而把单一频率的信号称为分量信号。声音信号的一个重要参数就是带宽(bandwidth),它用来描述组成声音信号的频率范围。PC处理的音频信号主要是人耳能听到的音频信号(audio),它的频率范围是20~20kHz。可听声包括如下内容。
|
|
|
|
.话音(也称语音):人的说话声,频率范围通常为300~3400Hz。
|
|
|
|
.音乐:由乐器演奏形成(规范的符号化声音),其带宽可达到20~20kHz。
|
|
|
|
.其他声音:如风声、雨声、鸟叫声、汽车鸣笛声等,它们起着效果声或噪声的作用,其带宽范围也是20Hz~20kHz。
|
|
|
|
|
|
声音信号的两个基本参数是幅度和频率。幅度是指声波的振幅,通常用动态范围表示,一般用分贝(dB)为单位来计量。频率是指声波每秒钟变化的次数,用Hz表示。
|
|
|
|
|
|
声音信号的数字化即用二进制数字的编码形式来表示声音。最基本的声音信号数字化方法是采样一量化法,可以分成以下3个步骤。
|
|
|
|
|
|
采样是把时间连续的模拟信号转换成时间离散、幅度连续的信号。在某些特定时刻获取的声音信号幅值叫作采样,由这些特定时刻采样得到的信号称为离散时间信号。一般是每隔相等的一小段时间采样一次,其时间间隔称为采样周期,它的倒数称为采样频率。为了不产生失真,采样频率不应低于声音信号最高频率的二分之一。因此,语音信号的采样频率一般为8kHz,音乐信号的采样频率则应在40kHz以上。采样频率越高,可恢复的声音信号分量越丰富,其声音的保真度越好。
|
|
|
|
|
|
量化处理是把在幅度上连续取值(模拟量)的每一个样本转换为离散值(数字量)表示,因此量化过程有时也称为A/D转换(模数转换)。量化后的样本是用二进制数来表示的,二进制数位数的多少反映了度量声音波形幅度的精度,称为量化精度,也称为量化分辨率。例如,每个声音样本若用16位(2B)表示,则声音样本的取值范围是0~65 536;精度是1/65 536;若只用8位(1B)表示,则样本的取值范围是0~255,精度是1/256。量化精度越高,声音的质量越好,需要的存储空间也越多;量化精度越低,声音的质量越差,而需要的存储空间越少。
|
|
|
|
|
|
为了便于计算机的存储、处理和传输,按照一定的要求对采样和量化处理后的声音信号进行数据压缩和编码,即选择某一种或者几种方法对它进行数据压缩,以减少数据量,再按照某种规定的格式将数据组织成为文件。
|
|
|
|
|
|
计算机中的数字声音有两种不同的表示方法:一种称为波形声音(也称为自然声音),通过对实际声音的波形信号进行数字化(采样和量化)而获得,能高保真地表示现实世界中任何客观存在的真实声音,波形声音的数据量比较大;另一种是合成声音,它使用符号(参数)对声音进行描述,然后通过合成的方法生成声音。
|
|
|
|
波形声音信息是一个用来表示声音振幅的数据序列,它是通过对模拟声音按一定间隔采样获得的幅度值,再经过量化和编码后得到的便于计算机存储和处理的数据格式。
|
|
|
|
|
|
数据传输率(b/s)=采样频率(Hz)×量化位数(bit)×声道数
|
|
|
|
数据传输率以每秒比特(b/s)为单位;采样频率以Hz为单位;量化以比特(b)为单位。
|
|
|
|
波形声音经过数字化后所需占用的存储空间可用如下公式计算:
|
|
|
|
|
|
|
|
(1)波形编码。波形编码是一种直接对取样量化后的波形进行压缩处理的方法。波形编码的特点是通用性强,不仅适用于数字语音的压缩,而且对所有使用波形表示的数字声音都有效,可获得高质量的语音,但很难达到高的压缩比。
|
|
|
|
(2)参数编码。参数编码(也称为模型编码)是一种基于声音生成模型的压缩方法,从语音波形信号中提取生成的话音参数,使用这些参数通过话音生成模型重构出话音。它的优点是能达到很高的压缩比,缺点是信号源必须已知,而且受声音生成模型的限制,质量不太理想。
|
|
|
|
(3)混合编码。波形编码虽然可提供高质量的语音,但数据率比较高,很难低于16kb/s;参数编码的数据率虽然可降低到3kb/s甚至更低,但它的音质根本不能与波形编码相比。混合编码是上述两种方法的结合,它既能达到高的压缩比,又能保证一定的质量。
|
|
|
|
数字语音压缩编码有多种国际标准,如G.711、G.721、G.726、G.727、G.722、G.728、G.729A、G.723.1、IS96(CDMA)等。
|
|
|
|
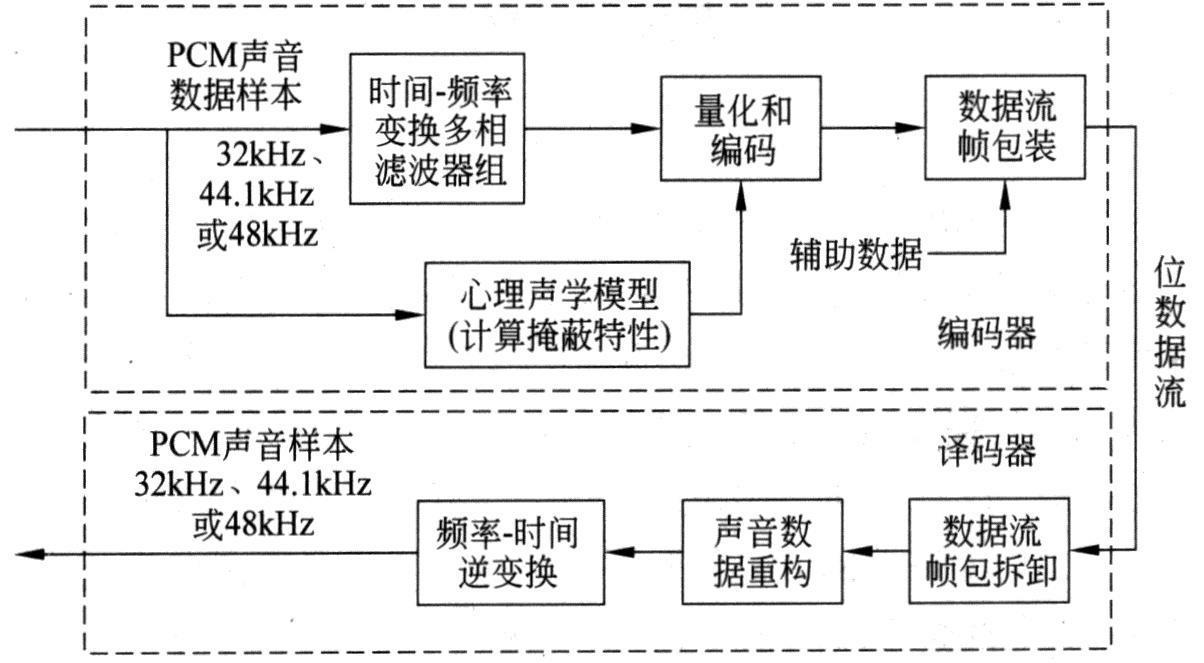
在国际标准MPEG中,先后为视频图像伴音的数字宽带声音制定了MPEG-1 Audio、MPEG-2 Audio、MPEG-2AAC、MPEG-4 Audio等多种数据压缩编码的标准。MPEG处理的是10~20 000Hz频率范围的声音信号,数据压缩的主要依据是人耳的听觉特性,特别是人耳存在着随声音频率变化的听觉域,以及人耳的听觉掩蔽特性。
|
|
|
|
|
|
|
|
|
|
语音合成目前主要指从文本到语音的合成,也称为文语转换。语音合成从合成采用的技术讲可分为发音参数合成、声道模型参数合成和波形编辑合成,从合成策略上讲可分为频谱逼近和波形逼近。
|
|
|
|
(1)发音参数合成。发音参数合成对人的发音过程进行直接模拟,它定义了唇、舌、声带的相关参数,如唇开口度、舌高度、舌位置、声带张力等。由这些发音参数估计声道截面积函数,进而计算声波。由于人发音生理过程的复杂性,理论计算与物理模拟之间的差异,语音合成的质量暂时还不理想。
|
|
|
|
(2)声道模型参数合成。声道模型参数合成基于声道截面积函数或声道谐振特性合成语音,如共振峰合成器、LPC合成器。国内外也有不少采用这种技术的语音合成系统。这类合成器的比特率低、音质适中。为改善音质,发展了混合编码技术,主要手段是改善激励,如码本激励、多脉冲激励、长时预测规则码激励等,这样,比特率有所增大,同时音质得到提高。作为压缩编码算法,该合成广泛用于通信系统和多媒体应用系统中。
|
|
|
|
(3)波形编辑语音合成。波形编辑语音合成技术是指直接把语音波形数据库中的波形级联起来,输出连续语流。这种语音合成技术用原始语音波形替代参数,而且这些语音波形取自自然语音的词或句子,它隐含了声调、重音、发音速度的影响,合成的语音清晰自然。该合成质量普遍高于参数合成。
|
|
|
|
|
|
音乐是用乐谱进行描述并由乐器演奏而成的。乐谱的基本组成单元是音符(notes),最基本的音符有7个,所有不同音调的音符少于128个。
|
|
|
|
音符代表的是音乐,音乐与噪声的区别主要在于它们是否有周期性。音乐的要素有音调、音色、响度和持续时间。
|
|
|
|
.音调指声波的基频,基频低,声音低沉;基频高,声音高昂。
|
|
|
|
|
|
.一首乐曲中每一个乐音的持续时间是变化的,从而形成旋律。
|
|
|
|
.音乐可以使用电子学原理合成出来(生成相应的波形),各种乐器的音色也可以进行模拟。
|
|
|
|
|
|
(1)演奏控制器。演奏控制器是一种输入和记录实时乐曲演奏信息的设备。它的作用是像传统乐器那样用于演奏,驱动音源发声,同时它也是计算机音乐系统的输入设备。其类型有键盘、气息(呼吸)控制器、弦乐演奏器等。
|
|
|
|
(2)音源。音源是具体产生声音波形的部分,即电子乐器的发声部分。它通过电子线路把演奏控制器送来的声音合成起来。最常用的音源有以下两类。
|
|
|
|
.数字调频合成器(FM):FM是使高频振荡波的频率按调制信号规律变化的一种调制方式。
|
|
|
|
.PCM波形合成器(波表合成法):这种方法是把真实乐器发出的声音以数字的形式记录下来,再将它们放在一个波形表中,合成音乐时以查表匹配方式获取真实乐器波形。
|
|
|
|
|
|
MIDI是音乐与计算机结合的产物。MIDI(Musical Instrument Digital Interface)是乐器数字接口的缩写,泛指数字音乐的国际标准。
|
|
|
|
MIDI消息实际上就是乐谱的数字表示。与波形声音相比,MIDI数据不是声音而是指令,因此它的数据量要比波形声音少得多。例如30分钟的立体声高品质音乐,用波形文件无压缩录制,约需300MB的存储空间;同样的MIDI数据,则只需200KB,两者相差1500倍之多。另外,对MIDI的编辑很灵活,可以自由地改变曲调、音色等属性,波形声音就很难做到这一点。波形声音与设备无关,MIDI数据是与设备有关的。
|
|
|
|
|
|
|
|
WAV是微软公司的音频文件格式,它来源于对声音模拟波形的采样。用不同的采样频率对声音的模拟波形进行采样可以得到一系列离散的采样点,以不同的量化位数(8位或16位)把这些采样点的值转换成二进制数,然后存入磁盘,这就产生了声音的WAV文件,即波形文件。利用该格式记录的声音文件能够和原声基本一致,质量非常高,但文件数据量却大。
|
|
|
|
|
|
MOD格式的文件里存放乐谱和乐曲使用的各种音色样本,具有回放效果优异、音色种类无限等优点。
|
|
|
|
|
|
MP3是现在最流行的声音文件格式,因其压缩率大,在网络可视电话通信方面应用广泛,但和CD唱片相比,音质不能令人非常满意。
|
|
|
|
|
|
RA格式具有强大的压缩量和较小的失真,它也是为了解决网络传输带宽资源而设计的,因此主要目标是压缩比和容错性,其次才是音质。
|
|
|
|
|
|
MID是目前较成熟的音乐格式,实际上已经成为一种产业标准,General MIDI就是最常见的通行标准。文件的长度非常小。RMI可以包括图片标记和文本。
|
|
|
|
|
|
Creative公司波形音频文件格式,也是声霸卡(Sound Blaster)使用的音频文件格式。每个VOC文件由文件头块(Header Block)和音频数据块(Data Block)组成。文件头包含一个标识版本号和一个指向数据块起始的指针。数据块分成各种类型的子块。
|
|
|
|
|
|
Sound文件是NeXT Computer公司推出的数字声音文件格式,支持压缩。
|
|
|
|
|
|
Audio文件是Sun Microsystems公司推出的一种经过压缩的数字声音文件格式,它是互联网上常用的声音文件格式。
|
|
|
|
|
|
AIF是Apple计算机的音频文件格式。利用Windows自带的工具可以把AIF格式的文件转换成Microsoft的WAV格式的文件。
|
|
|
|
|
|
CMF是Creative公司的专用音乐格式,与MIDI差不多,音色、效果上有些特色,专用于FM声卡,兼容性较差。
|
|
|