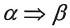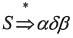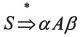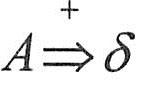|
|
|
词法分析过程的本质是对构成源程序的字符串进行分析,是一种对象为字符串的运算。语言中具有独立含义的最小语法单位是符号(单词),如标识符、无符号常数与界限符等。词法分析的任务是把构成源程序的字符串转换成单词符号序列。
|
|
|
|
|
|
(1)字母表∑:元素的非空有穷集合。例如,∑={a,b}。
|
|
|
|
(2)字符:字母表∑中的一个元素。例如,∑上的a或b。
|
|
|
|
(3)字符串:字母表∑中字符组成的有穷序列。例如,a、ab、aaa都是∑上的字符串。
|
|
|
|
(4)字符串的长度:字符串中的字符个数。例如,|aba|=3。
|
|
|
|
(5)空串ε:由0个字符组成的序列。例如,|ε|=0。
|
|
|
|
(6)连接:字符串S和T的连接是指将串T接续在串S之后,表示为S·T,连接符号“·”可省略。显然,对于字母表∑上的任意字符串S,S·ε=ε·S=S。
|
|
|
|
|
|
(8)∑*:指包括空串ε在内的∑上所有字符串的集合。例如,设∑={a,b},∑*={ε,a,b,aa,bb,ab,ba,aaa,…}。
|
|
|
|
(9)字符串的方幂:把字符串α自身连接n次得到的串,称为字符串α的n次方幂,记为αn。α0=ε,αn=ααn-1=αn-1α(n>0)。
|
|
|
|
(10)字符串集合的运算:设A、B代表字母表∑上的两个字符串集合。
|
|
|
|
|
|
|
|
.幂:An=A·An-1=An-1·A(n>0),并规定A0={ε}。
|
|
|
|
|
|
.闭包*:A*=A0∪A+。显然,∑*=∑0∪∑1∪∑2∪…
|
|
|
|
|
|
词法规则可用3型文法(正规文法)或正规表达式描述,它产生的集合是语言基本字符集∑(字母表)上的字符串的一个子集,称为正规集。
|
|
|
|
对于字母表∑,其上的正规式(正则表达式)及其表示的正规集可以递归定义如下。
|
|
|
|
(1)ε是一个正规式,它表示集合L(ε)={ε}。
|
|
|
|
(2)若a是∑上的字符,则a是一个正规式,它所表示的正规集为L(a)={a}。
|
|
|
|
(3)若正规式r和s分别表示正规集L(r)和L(s),则:
|
|
|
|
|
|
|
|
|
|
|
|
仅由有限次地使用上述三个步骤定义的表达式才是∑上的正规式。
|
|
|
|
运算符“|”“·”“*”分别称为“或”“连接”和“闭包”。在正规式的书写中,连接运算符“·”可省略。运算符的优先级从高到低顺序排列为“*”“·”“|”。
|
|
|
|
设∑={a,b},在下表中列出了∑上的一些正规式和相应的正规集。
|
|
|
|
|
|
|
|
若两个正规式表示的正规集相同,则认为二者等价。两个等价的正规式U和V记为U=V。例如,b(ab)*=(ba)*b,(a|b)*=(a*b*)*。
|
|
|
|
|
|
有限自动机是一种识别装置的抽象概念,它能准确地识别正规集。有限自动机分为两类:确定的有限自动机和不确定的有限自动机。
|
|
|
|
(1)确定的有限自动机(Deterministic Finite Automata,DFA)。一个确定的有限自动机是个五元组:(S,∑,f,s0,Z),其中:
|
|
|
|
|
|
②∑是一个有穷字母表,它的每个元素称为一个输入字符。
|
|
|
|
③f是S×∑→S上的单值部分映像。f(A,a)=Q表示当前状态为A、输入为a时,将转换到下一状态Q。称Q为A的一个后继状态。
|
|
|
|
|
⑤Z是非空的终止状态集合,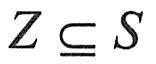
|
|
|
|
一个DFA可以用两种直观的方式表示:状态转换图和状态转换矩阵。状态转换图是一个有向图,简称为转换图。DFA中的每个状态对应转换图中的一个结点;DFA中的每个转换函数对应图中的一条有向弧,若转换函数为f(A,a)=Q,则该有向弧从结点A出发,进入结点Q,字符a是弧上的标记。
|
|
|
|
例如,DFAM1=({s0,s1,s2,s3},{a,b},f,s0,{s3}),其中f为:
|
|
|
|
f(s0,a)=s1,f(s0,b)=s2,f(s1,a)=s3,f(s1,b)=s2,f(s2,a)=s1,f(s2,b)=s3,f(s3,a)=s3
|
|
|
|
与DFAM1对应的状态转换图如下图(a)所示,其中,状态s3表示的结点是终态结点。状态转换矩阵可以用一个二维数组M表示,矩阵元素M[A,a]的行下标表示状态,列下标表示输入字符,M[A,a]的值是当前状态为A、输入字符为a时,应转换到的下一状态。与DFAM1对应的状态转换矩阵如下图(b)所示。在转换矩阵中,一般以第一行的行下标对应的状态作为初态,而终态则需要特别指出。
|
|
|
|
|
|
|
|
对于∑中的任何字符串ω,若存在一条从初态结点到某一终止状态结点的路径,且这条路径上所有弧的标记符连接成的字符串等于ω,则称ω可由DFAM识别(接受或读出)。若一个DFAM的初态结点同时又是终态结点,则空字ε可由该DFA识别(或接受)。DFAM所能识别的语言L(M)={ω|ω是从M的初态到终态的路径上的弧上标记所形成的串}。
|
|
|
|
例如,对于字符串"ababaa",在上图(a)所示的状态转换图中,识别"ababaa"的路径是s0→s1→s2→s1→s2→s1→s3。由于从初态结点s0出发,存在到达终态结点s3的路径,因此该DFA可识别串"ababaa"。而"abab"和"baab"都不能被该DFA接受。对于字符串“abab“,从初态结点s0出发,经过路径s0→s1→s2→s1→s2,当串结束时还没有到达终态结点s3;而对于串"baab",经过路径s0→s2→s1→s3,虽然能到达终态结点s3,但串尚未结束又不存在与下一字符"b"相匹配的状态转换。
|
|
|
|
(2)不确定的有限自动机(Nondeterministic Finite Automata,NFA)。一个不确定的有限自动机也是一个五元组,它与确定有限自动机的区别如下。
|
|
|
|
①f是S×∑→2s上的映像。对于S中的一个给定状态及输入符号,返回一个状态的集合。即当前状态的后继状态不一定是唯一确定的。
|
|
|
|
|
|
例如,已知有NFAN=({s0,s1,s2,s3},{a,b},f,s0,{s3}),其中f为:
|
|
|
|
f(s0,a)=s0,f(s0,a)=s1,f(s0,b)=s0,f(s1,b)=s2,f(s2,b)=s3
|
|
|
|
与NFAM2对应的状态转换图和状态转换矩阵如下图所示。
|
|
|
|
|
|
|
|
显然,DFA是NFA的特例。实际上,对于每个NFAM,都存在一个DFAN,且L(M)=L(N)。
|
|
|
|
词法分析器的任务是把构成源程序的字符流翻译成单词符号序列。手工构造词法分析器的方法是先用正规式描述语言规定的单词符号,然后构造相应有限自动机的状态转换图,最后依据状态转换图编写词法分析器(程序)。
|
|
|