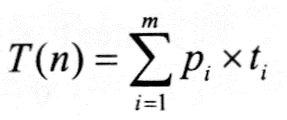|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
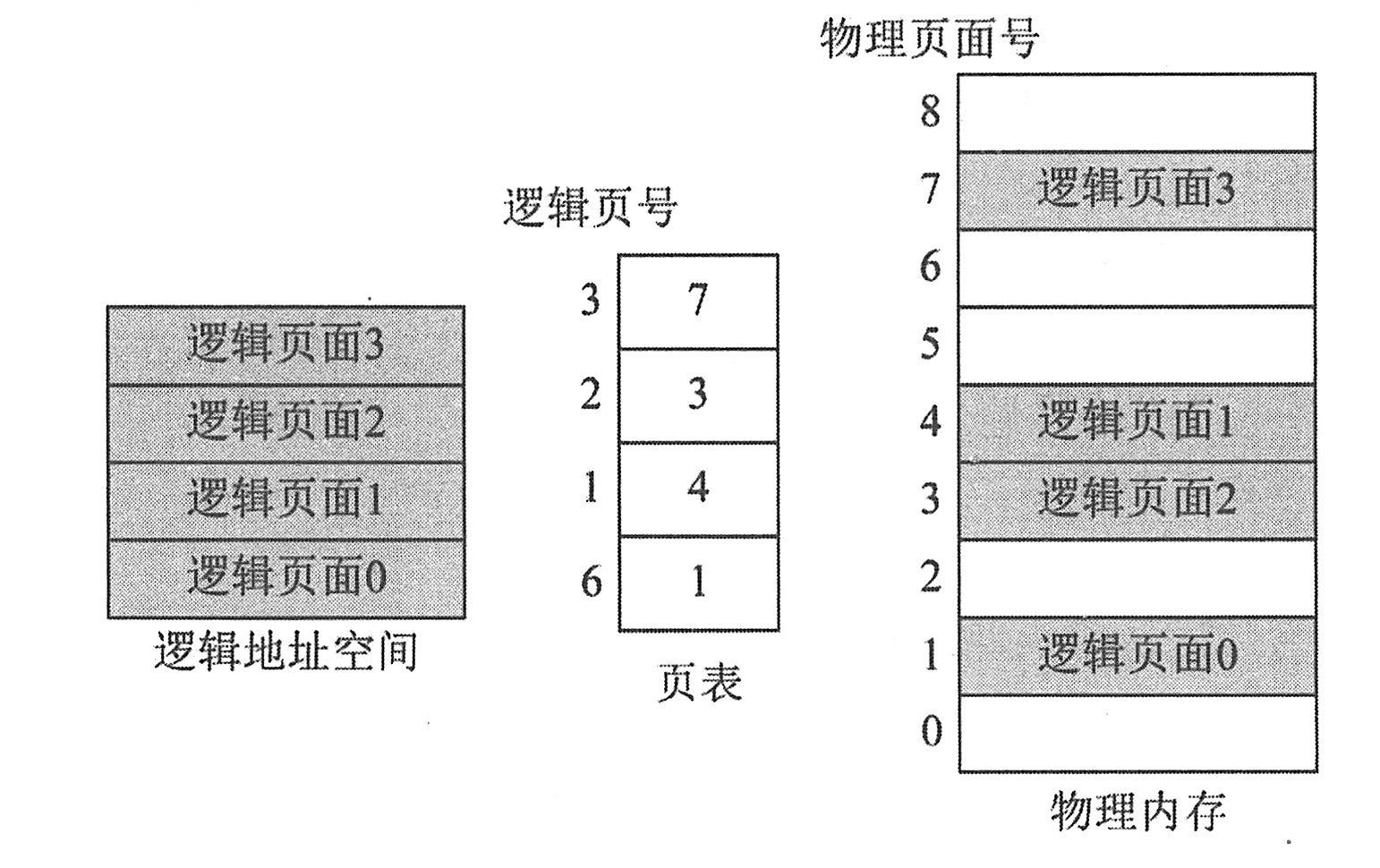
.页表:页表给出了任务的逻辑页面号与内存中的物理页面号之间的对应关系。
|
|
|
|
.物理页面表:用来描述内存空间中各个物理页面的使用分配状况。在具体实现上,可以采用位示图或空闲页面链表等方法。
|
|
|
|
下图是页表的一个例子。在任务的逻辑地址空间当中,总共有4个页面,即页面0、页面1、页面2和页面3。页表描述的是逻辑页面号与物理页面号之间的对应关系,即每一个逻辑页面存放在哪一个物理页面中。页表的下标是逻辑页面号,从0到3。相应的页表项存放的就是该逻辑页面所对应的物理页面号。在本例中,任务的4个逻辑页面分别存放在第1、第4、第3和第7个物理页面中。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n个元素的序列{k1, k2, …, kn}当且仅当满足以下的关系式时才称之为堆: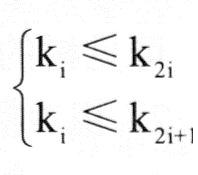 或 或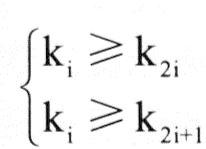 ,并相应地称为小顶堆或大顶堆。 ,并相应地称为小顶堆或大顶堆。
|
|
|
|
|
|
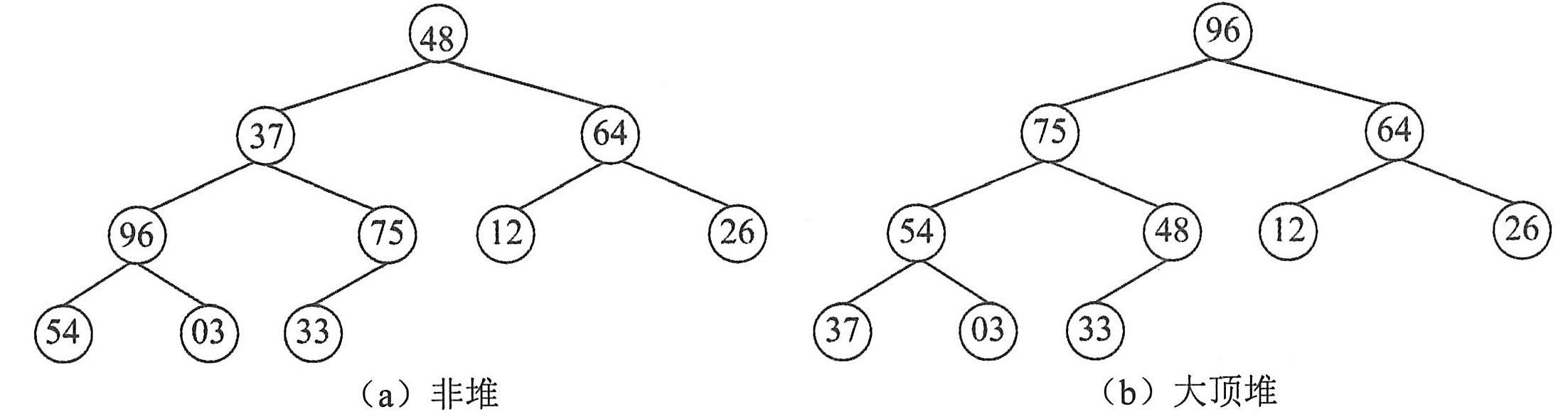
判断堆的办法是把序列看成一棵完全二叉树,若树中所有非终端节点的值均不大于(或不小于)其左右孩子的节点的值,则该序列为堆。
|
|
|
|
|
|
堆的典型应用是堆排序。堆排序首先要根据待排序记录的关键字建立初始堆,其方法是:将待排序的关键字按层序遍历方式分放到一棵完全二叉树的各个节点中,显然所有i>[n/2]的节点ki都没有子节点,以这样的ki为根的子树已经是堆,因此初始堆可从完全二叉树的第(i=[n/2])个节点开始,通过调整,逐步使以k[n/2], k[n/2]-1, …, k2, k1为根的子树满足堆的定义。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对于n个元素的关键字序列{k1,k2,…,kn},当且仅当满足下列关系时称其为堆。
|
|
|
|
|
|
若将此序列对应的一维数组(即以一维数组作为序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。因此,在一个堆中,堆顶元素(即完全二叉树的根结点)必为序列中的最小元素(或最大元素),并且堆中任一棵子树也都是堆。若堆顶为最小元素,则称为小顶堆;若堆顶为最大元素,则称为大顶堆。
|
|
|
|
例如,将序列(48,37,64,96,75,12,26,54,03,33)中的元素依次放入一棵完全二叉树中,如下图(a)所示。显然,它既不是大顶堆(48<64),也不是小顶堆(48>37),调整为大顶堆后如下图(b)所示。
|
|
|
|
|
|
|
|
堆排序的基本思想是:对一组待排序记录的关键字,首先把它们按堆的定义排成一个序列(即建立初始堆),从而输出堆顶的最小关键字(对于小顶堆而言)。然后将剩余的关键字再调整成新堆,便得到次小的关键字,如此反复,直到全部关键字排成有序序列为止。
|
|
|
|
n个元素进行堆排序时,时间复杂度为O(nlog2n),空间复杂度为O(1)。堆排序是不稳定的排序方法。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
假设含n个记录的文件内容为{R1,R2,…,Rn},其相应的关键字为{k1,k2,…,kn}。经过排序确定一种排列{Rj1,Rj2,…,Rjn},使得它们的关键字满足如下递增(或递减)关系:kj1≤kj2≤…≤kjn(或kj1≥kj2≥…≥kjn)。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
算法的时间复杂度分析主要是分析算法的运行时间,即算法所执行的基本操作数。即使对相同的输入规模,数据分布不相同也决定了算法执行不同的路径,因此所需要的执行时间也不相同。根据不同的输入,将算法的时间复杂度分为3种情况。
|
|
|
|
(1)最佳情况。使算法执行时间最少的输入。一般情况下,不进行算法在最佳情况下的时间复杂度分析。应用最佳情况分析的一个例子是已经证明基于比较的排序算法的时间复杂度下限为Ω(nlgn),那么就不需要白费力气去想方设法将该类算法改进为线性时间复杂度。
|
|
|
|
(2)最坏情况。使算法执行时间最多的输入。一般会进行算法在最坏时间复杂度的分析,因为最坏情况是在任何输入下运行时间的一个上限,它提供了一个保障,情况不会比这更糟糕。另外,对于某些算法来说,最坏情况还是相当频繁的。而且大致上看,平均情况通常与最坏情况的时间复杂度一样。
|
|
|
|
(3)平均情况。算法的平均运行时间。一般来说,这种情况很难分析。举个简单的例子,现要排序10个不同的整数,输入就有10!种不同的情况,平均情况的时间复杂度要考虑每一种输入及其该输入的概率。平均情况分析可以按以下3个步骤进行。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
式中,pi为第i类输入发生的概率;ti为第i类输入的执行时间,输入分为m类。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
若设R[1...n]为待排序的n个记录,R[1...i-1]已按照主关键字由小到大排序,且任意x∈R[1...i-1],y∈R[i...n]满足x.key≤y.key,则选择排序的主要思路如下。
|
|
|
|
(1)反复从R[i...n]中选出关键字最小的结点R[k]。
|
|
|
|
(2)若i≠k,则将R[i]与R[k]交换,使得R[1...i]有序且保持原来的性质。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可见,选择排序不管原先序列是否有序,其排序需要比较的次数均为n(n-1)/2;同时,由于相等的两个元素,位置相对在前的可能被交换到后面,故该选择排序是不稳定的。
|
|
|
|
|
|
|
|
|
|
|
|
|