|
|
|
对于给定的一个逻辑地址,如果已经知道了它所对应的物理页面号和页内偏移地址,可以采用简单的叠加算法,计算出最终的物理地址。假设物理页面号为f,页内偏移地址为offset,每个页面的大小为2n,那么相应的物理地址为:f×2n+offset。
|
|
|
|
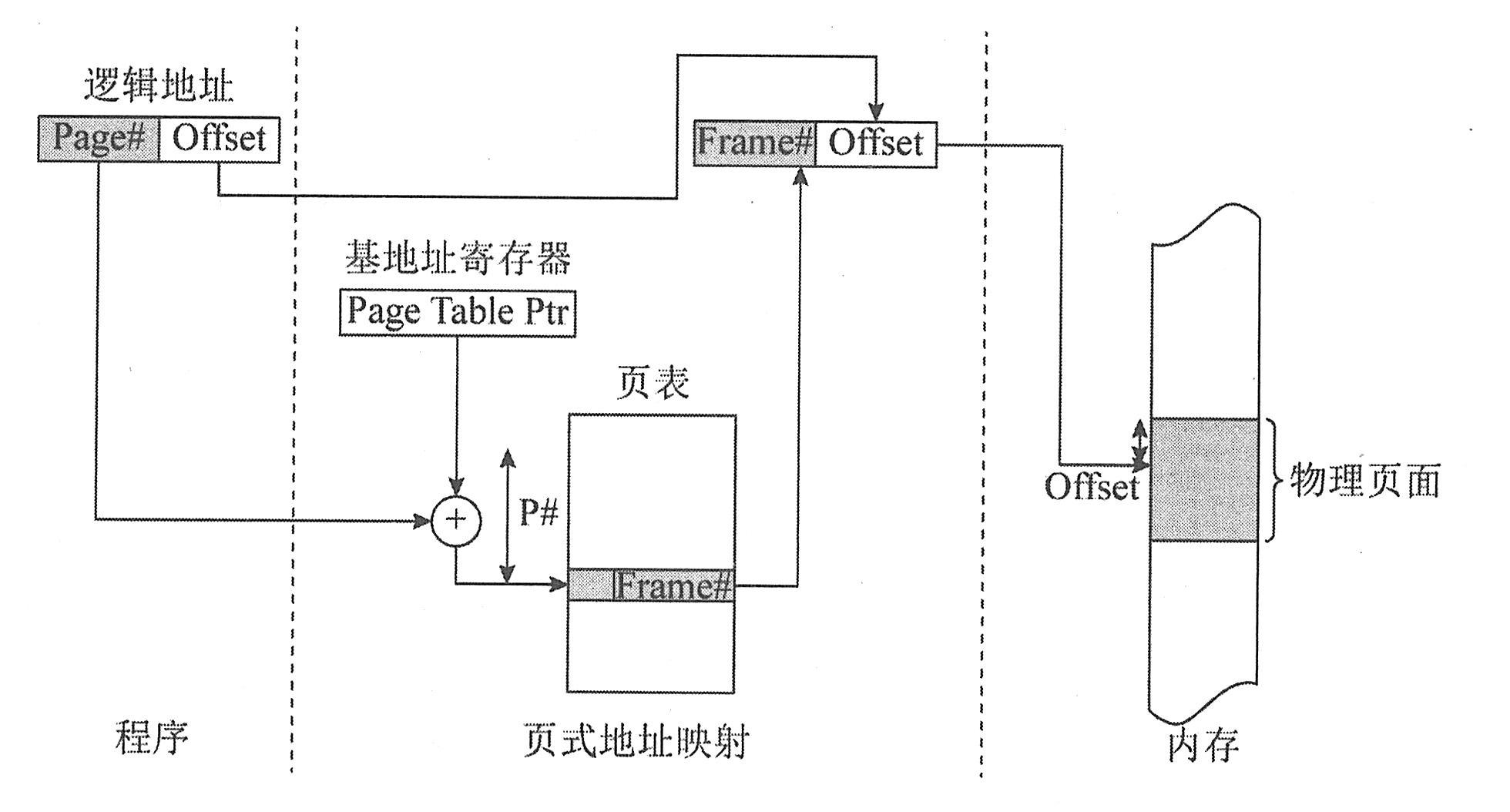
下图是页式存储管理当中的地址映射机制,也是以上各个步骤的一个综合。假设在程序的运行过程中,需要去访问某个内存单元,因此就给出了这个内存单元的逻辑地址。如前所述,这个逻辑地址由两部分组成,一是逻辑页面号,二是页内偏移地址。这个分析工作是由硬件自动来完成的,对用户是透明的。在页表基地址寄存器当中,存放的是当前任务的页表首地址。将这个首地址与逻辑页面号相加,就找到相应的页表项。里面存放的是这个逻辑页面所对应的物理页面号。将这个物理页面号取出来,与页内偏移地址进行组合,从而得到最终的物理地址。然后就可以用这个物理地址去访问内存。
|
|
|
|
|
|
|
|
现有的这种地址映射方案,虽然能够实现从逻辑地址到物理地址的转换,但它有一个很大的问题。当程序运行时需要去访问某个内存单元,例如,去读写内存当中的一个数据,或是去内存取一条指令,需要访问2次内存。第一次是去访问页表,取出物理页面号;第二次才是真正去访问数据或指令。也就是说,内存的访问效率只有50%。这样,就会降低获取数据的存取速度,进而影响到整个系统的使用效率。为了解决这个问题,人们又引入了快表的概念。它的基本思路来源于对程序运行过程的一个观察结果。对于绝大多数的程序,它们在运行时倾向于集中地访问一小部分的页面。因此,对于它们的页表来说,在一定时间内,只有一小部分的页表项会被经常地访问,而其他的页表项则很少使用。根据这个观察结果,人们在MMU中增加了一种特殊的快速查找硬件:TLB(Translation Lookaside Buffer),或者叫关联存储器,用来存放那些最常用的页表项。这种硬件设备能够把逻辑页面号直接映射为相应的物理页面号,不需要再去访问内存当中的页表,这样就缩短了页表的查找时间。
|
|
|
|
在TLB方式下,地址映射的过程略有不同。当一个逻辑地址到来时,它首先会到TLB当中去查找,看这个逻辑页面号所在的页表项是否包含在TLB当中,这个查找的速度是非常快的,因为它是以并行的方式进行。如果能够找到的话,就直接从TLB中把相应的物理页面号取出来,与页内偏移地址拼接成最终的物理地址。如果在TLB中没有找到该逻辑页面,那只能采用通常的地址映射方法,去访问内存当中的页表。接下来,硬件还会在TLB当中寻找一个空闲单元,如果没有空闲单元,就把某一个页表项驱逐出来,然后把刚刚访问过的这个页表项添加到TLB当中。这样,如果下次再来访问这个页面,就可以在TLB中找到它。
|
|
|
|
|
|
(1)没有外碎片,而且内碎片的大小不会超过页面的大小。这是因为系统是以页面来作为内存分配的基本单位,每一个页面都能够用上,不会浪费。只是在任务的某一些页面当中,可能没有装满,里面有一些内碎片。
|
|
|
|
(2)程序不必连续存放,它可以分散地存放在内存的不同位置,从而提高了内存利用率。
|
|
|
|
|
|
|
|
(1)程序必须全部装入内存,才能够运行。如果一个程序的规模大于当前的空闲空间的总和,那么它就无法运行。
|
|
|
|
(2)操作系统必须为每一个任务都维护一张页表,开销比较大。简单的页表结构已经不能满足要求,必须设计出更为复杂的结构,如多级页表结构、哈希页表结构、反置页表等。
|
|
|