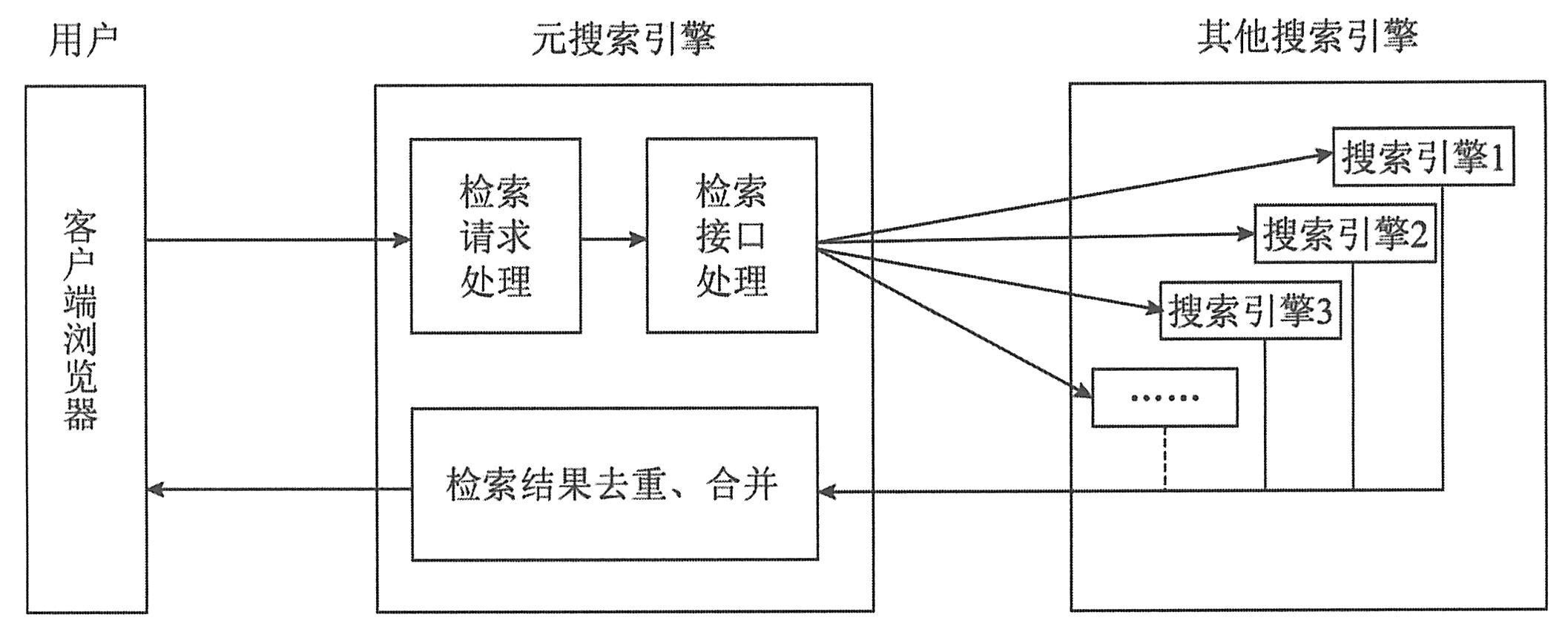
|
|
|
在数据库系统中,索引是一种可选结构,其目的是提高数据访问速度。利用索引可提高用户访问数据的速度,或直接从索引中独立检索数据。如果对索引的配置和使用进行了优化,那么索引能大大降低数据文件的I/O操作并提高系统性能。
|
|
|
|
但是在为一个表创建索引之后,Oracle将自动维护这个索引。当用户在表中插入、更新或删除记录时,系统将自动更新与该表相关的索引。一个表可以有任意数量的索引,但一个表的索引越多,用户在该表中插入、更新或删除记录时所造成的系统开销也越大。其原因是无论何时更新表,系统都必须更新与之相关的索引。
|
|
|
|
索引是建立在表的一个或多个字段之上的。索引的作用大小取决于该字段或字段集的选择性。所谓选择性,是指索引能降低数据集中的程度。如果表中与某个索引相关的字段值各不相同,那么该索引就有很好的选择性。一个选择性很差的索引的例子,是基于字段值仅为true/false的字段创建的索引,因为表中很多记录该字段的字段值都相同。一个索引可能只能帮助管理员降低检索的记录数,而不能惟一地确定一条记录。例如:如果为一个表的LastName字段创建了一个索引,现在用户需要搜索John Smith,那么这个索引将返回LastName字段值为Smith的所有记录,因而用户还不得不在返回的记录中搜索含John的记录。索引的选择性越好,就越有助于降低返回记录的数量,从而提高数据访问速度。下面介绍有效创建和使用索引的技巧和方法。
|
|
|
|
|
|
索引的主要作用之一就是降低系统处理的数据量。对CPU使用和等待完成I/O操作的时间上,I/O操作引起的系统开销都是非常昂贵的。降低I/O操作可提高系统性能和处理能力。如果不使用索引,那么为了找到特定的数据,系统将不得不扫描表中的所有数据。
|
|
|
|
|
|
|
|
如果不使用索引,系统必须扫描整个emp表并检查表中每条记录的employee_id字段的值。如果emp表很大,那么这个操作可能意味着数量巨大的I/O读写和很长的处理时间。
|
|
|
|
如果为emp表的employee_id字段创建了索引,那么系统将遍历该索引并找到用户所查询记录的ID。找到记录ID之后,只需一条额外的I/O操作就能检索到用户所需的数据。
|
|
|
|
用于说明这个问题的最好例子,是只需查找一条记录的情况。在表的每条记录中,类似employee_id这样的字段的值可能在整个表中都是惟一的。这意味着查询结果值返回一条记录,这种查询的效率是非常高的。
|
|
|
|
在某些情况下,索引必须返回大量数据。如下面的例子:
|
|
|
|
|
|
这个查询语句很可能返回大量数据,因为索引操作返回了大量记录的ID,并且系统必须独立访问这些记录的ID,所以这种情况下,不使用索引可能比使用索引的效率更高,直接进行表扫描可能效率更高。不同情况下,采用哪种查寻方法更好,很大程度上取决于表的数据量和组织形式。
|
|
|
|
对于不同的数据,在某些情况下位图索引可能非常有用,而在另外一些情况下,使用位图索引可能没有任何好处。
|
|
|
|
|
|
如果对表创建了索引,那么更新、插入和删除表中的记录都将导致额外的系统开销。在系统提交这些操作之前,系统将会更新所有与该表相关的索引。这可能需要花费很长时间,并额外增加一定的系统开销。
|
|
|
|
|
|
在某些情况下,表中的某些字段的选择性可能很低。开发人员没必要为所有表创建索引,实事上,在某些情况下索引引起的问题比解决的问题更多。在很多情况下,需要反复试验,才能确定一个索引是否有助于提高系统性能。
|
|
|
|
但是,位图索引能在字段选择性不高的情况下工作得很好。一个位图索引可以和其他位图索引联合使用,以降低系统检索的数据集。对于某些值为true/false、yes/no或其他小范围数据的字段,建立位图索引是非常合适的。请记住:位图索引所占用的空间,是随着与该索引相关的字段的不同值的数量的增加而增加的。
|
|
|
|
如果决定创建一个索引,那么确定为哪些字段创建索引是非常重要的。对于不同的表,可能会选择一个或多个字段创建索引。可使用如下方法来确定在哪些字段上创建索引:
|
|
|
|
①选择那些最常出现在where子句中的字段。经常被访问的字段最可能受益于索引。
|
|
|
|
|
|
③必须注意索引导致的查询语句性能的提高与更新数据时性能的降低之间的平衡。
|
|
|
|
④经常被修改的字段不适合创建索引,其原因是,更新索引将增加系统开销。
|
|
|
|
在某些情况下,使用复合索引的效率可能比使用简单索引的效率更高。下面的一些例子说明了应当在何种情况下使用复合索引。
|
|
|
|
①某两个字段单独来看都不具有惟一性,但结合在一起却有惟一性,那么这种情况下,复合索引将工作得很好。例如:A字段和B字段都几乎没有惟一性值,但绝大多数情况下,字段A和B的某个特定组合却具有惟一性特点。那么在检索数据时,可在where子句重视and操作符来将这两个字段连接在一起。
|
|
|
|
②如果select语句中的所有值都位于复合索引中,那么Oracle将不会检索表,而直接从索引中返回数据。
|
|
|
|
③如果多个查询语句的where子句中作为查询条件的字段都不相同,但返回的记录相同,那么应当考虑利用这些字段创建一个复合索引。
|
|
|
|
在创建索引之后,开发人员应当定期利用SQL TRACE工具或EXPLAIN PLAN来察看用户查询是否充分利用了索引。很有必要花费一定精力来试验使用索引和未使用索引在效率上的差别,以判断索引所耗费资源是否物有所值。
|
|
|
|
应该删除那些不经常使用的索引。可使用alter index monitoring usage语句来跟踪索引的使用情况。还可以从系统表all_indexes、user_indexes和dba_indexes中查询用户访问索引的频率。
|
|
|
|
如果为一个不适合创建索引的字段或表创建了索引,那么这可能会导致系统能力的下降。而如果创建的索引合理,那么这将降低系统的I/O操作并加快访问速度,从而大大提高系统性能。
|
|
|