|
|
|
|
|
|
|
大数据的应用和技术是在互联网快速发展中诞生的,起点可追溯到2000年前后。当时互联网网页爆发式增长,每天新增约700万个网页,到2000年底全球网页数达到40亿,用户检索信息越来越不方便。谷歌等公司率先建立了覆盖数十亿网页的索引库,开始提供较为精确的搜索服务,大大提升了人们使用互联网的效率,这是大数据应用的起点。当时搜索引擎要存储和处理的数据,不仅数量之大前所未有,而且以非结构化数据为主,传统技术无法应对。为此,谷歌提出了一套以分布式为特征的全新技术体系,即后来陆续公开的分布式文件系统(Google File System,GFS)、分布式并行计算(MapReduce)和分布式数据库(BigTable)等技术,以较低的成本实现了之前技术无法达到的规模。这些技术奠定了当前大数据技术的基础,可以认为是大数据技术的源头。
|
|
|
|
伴随着互联网产业的崛起,这种创新的海量数据处理技术在电子商务、定向广告、智能推荐、社交网络等方面得到应用,取得巨大的商业成功。这启发全社会开始重新审视数据的巨大价值,于是金融、电信等拥有大量数据的行业开始尝试这种新的理念和技术,取得初步成效。与此同时,业界也在不断对谷歌提出的技术体系进行扩展,使之能在更多的场景下使用。2011年,麦肯锡、世界经济论坛等知名机构对这种数据驱动的创新进行了研究总结,随即在全世界兴起了一股大数据热潮。
|
|
|
|
虽然大数据已经成为全社会热议的话题,但至今“大数据”尚无公认的统一定义。我们认为,认识大数据要把握“资源、技术、应用”三个层次。大数据是具有体量大、结构多样、时效强等特征的数据;处理大数据需采用新型计算架构和智能算法等新技术;大数据的应用强调以新的理念应用于辅助决策、发现新的知识,更强调在线闭环的业务流程优化。因此可以说,大数据不仅“大”,而且“新”,是新资源、新工具和新应用的综合体。
|
|
|
|
|
|
业界通常用Volume、Variety、Value、Velocity这4个V来概括大数据的特点:
|
|
|
|
(1)数据体量巨大(Volume)。IDC研究表明,数字领域存在着1.8万亿吉字节的数据。企业数据正在以55%的速度逐年增长。实体世界中,数以百万计的数据采集传感器被嵌入到各种设备中,在数字化世界中,消费者每天的生活(通信、上网浏览、购物、分享、搜索)都在产生着数量庞大的数据。
|
|
|
|
(2)数据类型繁多(Variety)。数据可分为结构化数据、半结构化数据和非结构化数据。相对于以往便于存储的以文本为主的结构化数据,音频、视频、图片、地理位置信息等类型的非结构化数据量占比达到了80%,并在逐步提升,有用信息的提取难度不断增大。
|
|
|
|
(3)价值密度低(Value)。价值密度的高低与数据总量的大小成反比。以视频为例,一部1小时的视频,在连续不间断监控过程中,可能有用的数据仅仅只有一两秒。
|
|
|
|
(4)时效性高(Velocity)。这是大数据区分于传统数据挖掘最显著的特征。数据的价值除了与数据规模相关,还与数据处理周期成正比关系。也就是,数据处理的速度越快、越及时,其价值越大,发挥的效能越大。
|
|
|
|
|
|
|
|
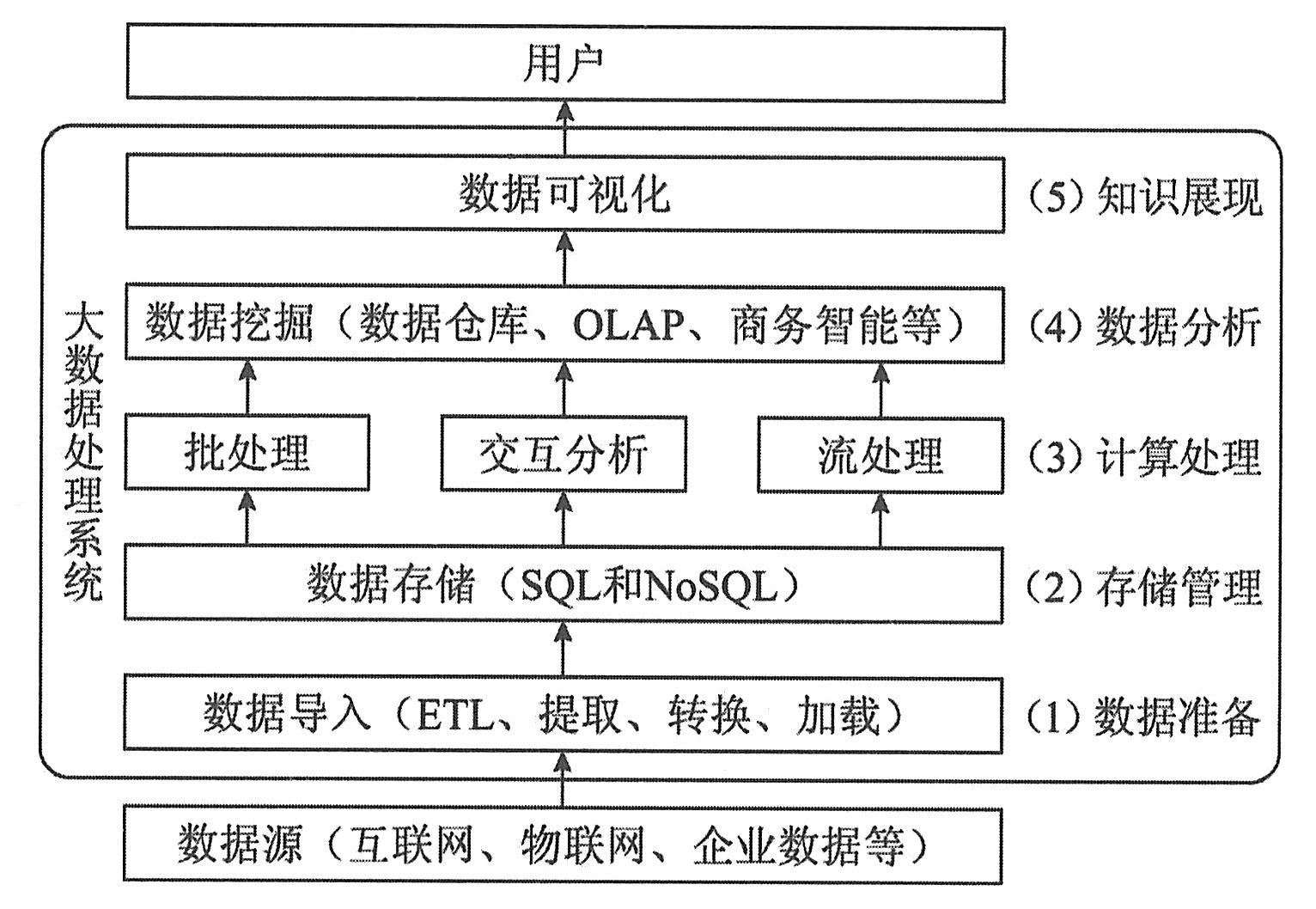
大数据来源于互联网、企业系统和物联网等信息系统,经过大数据处理系统的分析挖掘,产生新的知识用以支撑决策或业务的自动智能化运转。从数据在信息系统中的生命周期看,大数据从数据源经过分析挖掘到最终获得价值一般需要经过5个主要环节,包括数据准备、数据存储与管理、计算处理、数据分析和知识展现,技术体系如下图所示。每个环节都面临不同程度的技术上的挑战。
|
|
|
|
|
|
|
|
(1)数据准备环节。在进行存储和处理之前,需要对数据进行清洗、整理,传统数据处理体系中称为ETL(Extracting,Transforming,Loading)过程。与以往数据分析相比,大数据的来源多种多样,包括企业内部数据库、互联网数据和物联网数据,不仅数量庞大、格式不一,质量也良莠不齐。这就要求数据准备环节一方面要规范格式,便于后续存储管理,另一方面要在尽可能保留原有语义的情况下去粗取精、消除噪声。
|
|
|
|
(2)数据存储与管理环节。当前全球数据量正以每年超过50%的速度增长,存储技术的成本和性能面临非常大的压力。大数据存储系统不仅需要以极低的成本存储海量数据,还要适应多样化的非结构化数据管理需求,具备数据格式上的可扩展性。
|
|
|
|
(3)计算处理环节。需要根据处理的数据类型和分析目标,采用适当的算法模型,快速处理数据。海量数据处理要消耗大量的计算资源,对于传统单机或并行计算技术来说,速度、可扩展性和成本上都难以适应大数据计算分析的新需求。分而治之的分布式计算成为大数据的主流计算架构,但在一些特定场景下的实时性还需要大幅提升。
|
|
|
|
(4)数据分析环节。数据分析环节需要从纷繁复杂的数据中发现规律提取新的知识,是大数据价值挖掘的关键。传统数据挖掘对象多是结构化、单一对象的小数据集,挖掘更侧重根据先验知识预先人工建立模型,然后依据既定模型进行分析。对于非结构化、多源异构的大数据集的分析,往往缺乏先验知识,很难建立显式的数学模型,这就需要发展更加智能的数据挖掘技术。
|
|
|
|
(5)知识展现环节。在大数据服务于决策支撑场景下,以直观的方式将分析结果呈现给用户,是大数据分析的重要环节。如何让复杂的分析结果易于理解是主要挑战。在嵌入多业务中的闭环大数据应用中,一般是由机器根据算法直接应用分析结果而无需人工干预,这种场景下知识展现环节则不是必需的。
|
|
|
|
总的来看,大数据对数据准备环节和知识展现环节来说只是量的变化,并不需要根本性的变革。但大数据对数据分析、计算和存储三个环节影响较大,需要对技术架构和算法进行重构,是当前和未来一段时间大数据技术创新的焦点。下面简要分析上述3个环节面临的挑战及发展趋势。
|
|
|
|
|
|
大数据技术体系纷繁复杂,其中一些技术创新格外受到关注。随着社交网络的流行导致大量非结构化数据出现,传统处理方法难以应对,数据处理系统和分析技术开始不断发展。从2005年Hadoop的诞生开始,形成了数据分析技术体系这一热点。伴随着量急剧增长和核心系统对吞吐量以及时效性的要求提升,传统数据库需向分布式转型,形成了事务处理技术体系这一热点。然而时代的发展使得单个企业甚至行业的数据都难以满足要求,融合价值更加显现,形成了数据流通技术体系这一热点。
|
|
|
|
|
|
从数据在信息系统中的生命周期看,数据分析技术生态主要有5个发展方向,包括数据采集与传输、数据存储与管理、计算处理、查询与分析、可视化展现。在数据采集与传输领域渐渐形成了Sqoop、Flume、Kafka等一系列开源技术,兼顾离线和实时数据的采集和传输。在存储层,HDFS已经成为了大数据磁盘存储的事实标准,针对关系型以外的数据模型,开源社区形成了K-V(key-value)、列式、文档、图这四类NoSQL数据库体系,Redis、HBase、Cassandra、MongoDB、Neo4j等数据库是各个领域的领先者。计算处理引擎方面,Spark已经取代MapReduce成为了大数据平台统一的计算平台,在实时计算领域Flink是Spark Streaming强力的竞争者。在数据查询和分析领域形成了丰富的SQL on Hadoop的解决方案,Hive、HAWQ、Impala、Presto、Spark SQL等技术与传统的大规模并行处理(Massively Parallel Processor,MPP)数据库竞争激烈,Hive还是这个领域当之无愧的王者。在数据可视化领域,敏捷商业智能(Business Intelligence,BI)分析工具Tableau、QlikView通过简单的拖拽来实现数据的复杂展示,是目前最受欢迎的可视化展现方式。
|
|
|
|
相比传统的数据库和MPP数据库,Hadoop最初的优势来源于良好的扩展性和对大规模数据的支持,但失去了传统数据库对数据精细化的操作,包括压缩、索引、数据的分配裁剪以及对SQL的支持度。经过10多年的发展,数据分析的技术体系渐渐在完善自己的不足,也融合了很多传统数据库和MPP数据库的优点,从技术的演进来看,大数据技术正在发生以下变化:
|
|
|
|
(1)更快。Spark已经替代MapReduce成为了大数据生态的计算框架,以内存计算带来计算性能的大幅提高,尤其是Spark 2.0增加了更多了优化器,计算性能进一步增强。
|
|
|
|
(2)流处理的加强。Spark提供一套底层计算引擎来支持批量、SQL分析、机器学习、实时和图处理等多种能力,但其本质还是小批的架构,在流处理要求越来越高的现在,Spark Streaming受到Flink激烈的竞争。
|
|
|
|
(3)硬件的变化和硬件能力的充分挖掘。大数据技术体系本质是数据管理系统的一种,受到底层硬件和上层应用的影响。当前硬件的芯片的发展从CPU的单核到多核演变转化为向GPU、FPGA、ASIC等多种类型芯片共存演变。而存储中大量使用SSD来代替SATA盘,NVRAM有可能替换DRAM成为主存。大数据技术势必需要拥抱这些变化,充分兼容和利用这些硬件的特性。
|
|
|
|
(4)SQL的支持。从Hive诞生起,Hadoop生态就在积极向SQL靠拢,主要从兼容标准SQL语法和性能等角度来不断优化,层出不穷的SQL on Hadoop技术参考了很多传统数据库的技术。而Greenplum等MPP数据库技术本身从数据库继承而来,在支持SQL和数据精细化操作方面有很大的优势。
|
|
|
|
(5)深度学习的支持。深度学习框架出现后,和大数据的计算平台形成了新的竞争局面,以Spark为首的计算平台开始积极探索如何支持深度学习能力,TensorFlow on Spark等解决方案的出现实现了TensorFlow与Spark的无缝连接,更好地解决了两者数据传递的问题。
|
|
|
|
|
|
随着移动互联网的快速发展,智能终端数量呈现爆炸式增长,银行和支付机构传统的柜台式交易模式逐渐被终端直接交易模式替代。以金融场景为例,移动支付以及普惠金融的快速发展,为银行业、支付机构和金融监管机构带来了海量高频的线上小额资金支付行为,生产业务系统面临大规模并发事务处理要求的挑战。
|
|
|
|
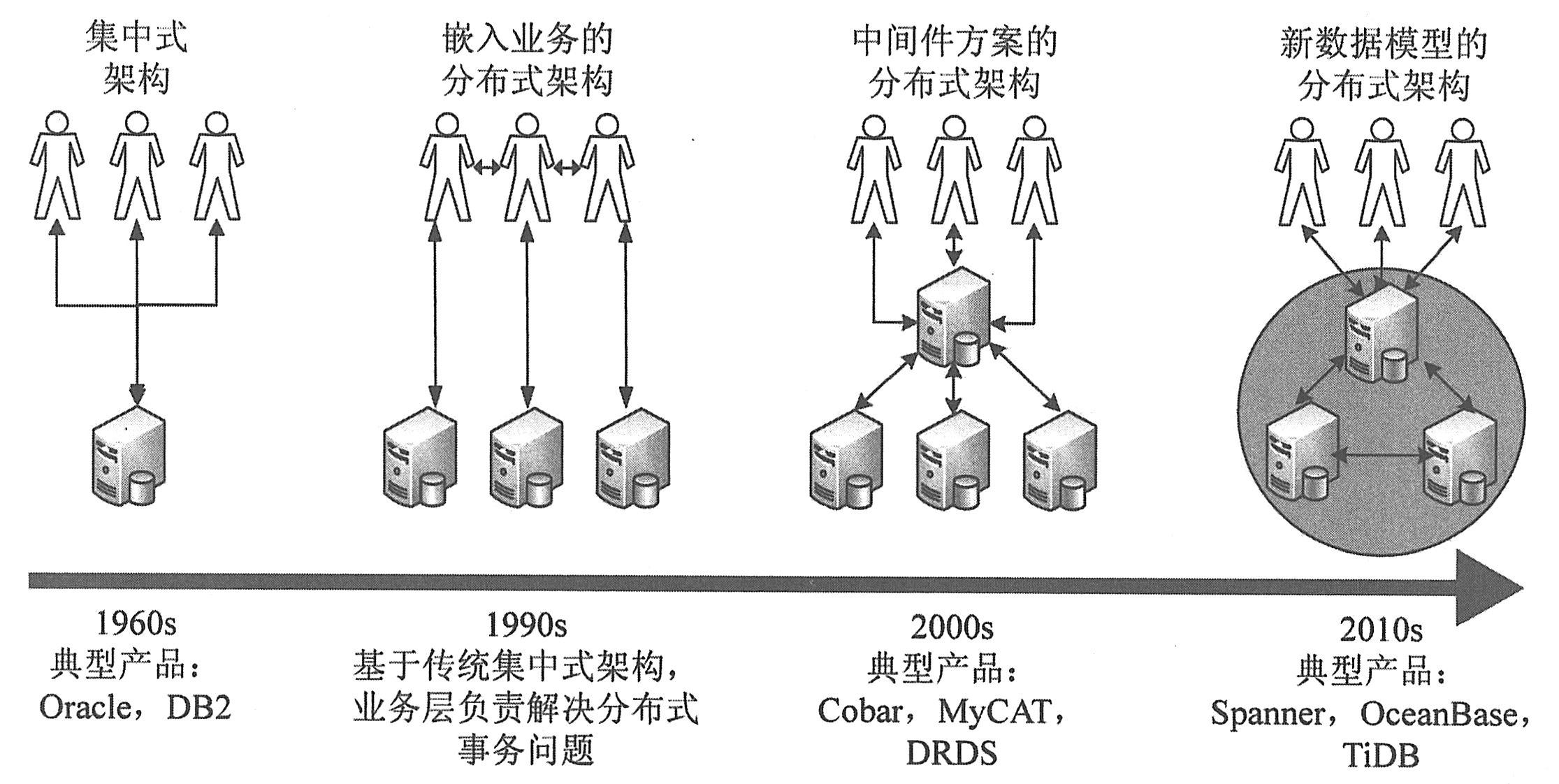
传统事务技术模式以集中式数据库的单点架构为主,通过提高单机的性能上限适应业务的扩展。而随着摩尔定律的失效(底层硬件的变化),单机性能扩展的模式走到了尽头,而数据交易规模的急速增长(上层应用的变化)要求数据库系统具备大规模并发事务处理的能力。大数据分析系统经过10多年的实践,积累了丰富的分布式架构的经验,Paxos、Raft等一致性协议的诞生为事务系统的分布式铺平了道路。新一代分布式数据库技术在这些因素的推动下应运而生。
|
|
|
|
如下图所示,经过多年发展,当前分布式事务架构正处在快速演进的阶段,综合学术界以及产业界工作成果,目前主要分为三类:
|
|
|
|
|
|
|
|
(1)基于原有单机事务处理关系数据库的分布式架构改造:利用原有单机事务处理数据库的成熟度优势,通过在独立应用层面建立起数据分片和数据路由的规则,建立起一套复合型的分布式事务处理数据库的架构。
|
|
|
|
(2)基于新的分布式事务数据库的工程设计思路的突破。通过全新设计关系数据库的核心存储和计算层,将分布式计算和分布式存储的设计思路和架构直接植入数据库的引擎设计中,提供对业务透明和非侵入式的数据管理和操作/处理能力。
|
|
|
|
(3)基于新的分布式关系数据模型理论的突破。通过设计全新的分布式关系数据管理模型,从数据组织和管理的最核心理论层面,构造出完全不同于传统单机事务数据库的架构,从数据库的数据模型的根源上解决分布式关系数据库的架构。
|
|
|
|
分布式事务数据库进入到各行各业面临诸多挑战,其一是多种技术路线,目前没有统一的定义和认识;其二是除了互联网公司有大规模使用外,其他行业的实践刚刚开始,需求较为模糊,采购、使用、运维的过程缺少可供参考的经验,需要较长时间的摸索;其三是缺少可行的评价指标、测试方法和测试工具来全方位比较当前的产品,规范市场,促进产品的进步。故应用上述技术进行交易类业务进行服务时,应充分考虑“可持续发展”“透明开放”“代价可控”三原则,遵循“知识传递先行”“测试评估体系建立”“实施阶段规划”三步骤,并认识到“应用过度适配和改造”“可用性管理策略不更新”“外围设施不匹配”三个误区。
|
|
|
|
大数据事务处理类技术体系的快速演进正在消除日益增长的数字社会需求同旧式的信息架构缺陷,未来人类行为方式、经济格局以及商业模式将会随大数据事务处理类技术体系的成熟而发生重大变革。
|
|
|
|
|
|
数据流通是释放数据价值的关键环节。然而,数据流通也伴随着权属、质量、合规性、安全性等诸多问题,这些问题成为了制约数据流通的瓶颈。为了解决这些问题,大数据从业者从诸多方面进行了探索。目前来看,从技术角度的探索是卓有成效和富有潜力的。
|
|
|
|
从概念上讲,基础的数据流通只存在数据供方和数据需方这两类角色,数据从供方通过一定手段传递给需方。然而,由于数据权属和安全的需要,不能简单地将数据直接进行传送。数据流通的过程中需要完成数据确权、控制信息计算、个性化安全加密等一系列信息生产和再造,形成闭合环路。
|
|
|
|
安全多方计算和区块链是近年来常用的两种技术框架。由于创造价值的往往是对数据进行的加工分析等运算的结果而非数据本身,因此对数据需方来说,本身不触碰数据、但可以完成对数据的加工分析操作,也是可以接受的。安全多方计算这个技术框架就实现了这一点。其围绕数据安全计算,通过独特的分布式计算技术和密码技术,有区分地、定制化地提供安全性服务,使得各参与方在无需对外提供原始数据的前提下实现了对与其数据有关的函数的计算,解决了一组互不信任的参与方之间保护隐私的协同计算问题。区块链技术中多个计算节点共同参与和记录,相互验证信息有效性,既进行了数据信息防伪,又提供了数据流通的可追溯路径。业务平台中授权和业务流程的解耦对数据流通中的溯源、数据交易、智能合约的引入有了实质性的进展。
|
|
|
|
|
|
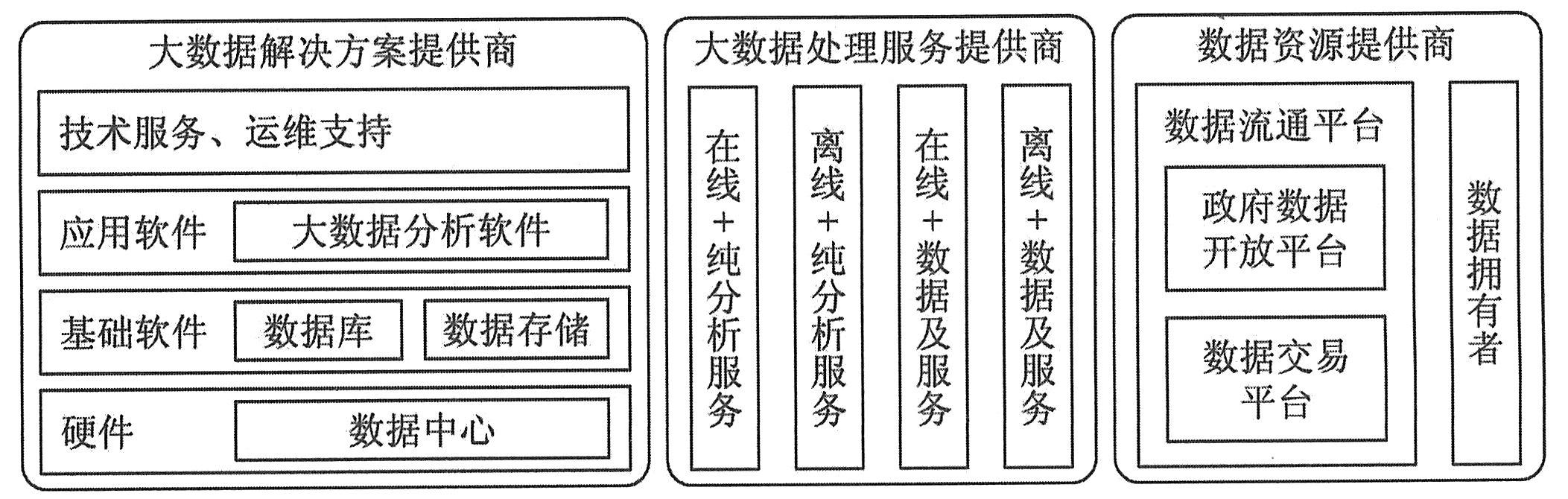
随着大数据技术不断演进和应用持续深化,以数据为核心的大数据产业体系正在加速构建。大数据产业体系中主要包括大数据解决方案提供商、大数据处理服务提供商和数据资源提供商三个角色,分别向大数据的应用者提供大数据服务、解决方案和数据资源,如下图所示。
|
|
|
|
|
|
|
|
|
|
大数据解决方案提供商面向企业用户提供大数据一站式部署方案,覆盖数据中心和服务器等硬件、数据存储和数据库等基础软件、大数据分析应用软件以及技术运维支持等方面内容。其中,大数据基础软件和应用软件是大数据解决方案中的重点内容。当前,企业提供的大数据解决方案大多基于Hadoop开源项目,例如,IBM基于Hadoop开发的大数据分析产品BigInsights、甲骨文融合了Hadoop开源技术的大数据一体机、Cloudera的Hadoop商业版等。大数据解决方案提供商中,主要包括传统IT厂商和新兴的大数据创业公司。传统IT厂商主要有IBM、HP等解决方案提供商以及甲骨文、Teradata等数据分析软件商。它们大多以原有IT解决方案为基础,融合Hadoop,形成融合了结构化和非结构化两条体系的“双栈”方案。通过一系列收购来提升大数据解决方案服务能力,成为这些IT巨头的主要策略。
|
|
|
|
国际上也诞生了一批专门提供非结构化数据处理方案的新兴创业公司。这些公司包括Cloudera、Hortonworks、MapR等,它们主要基于Hadoop开源项目,开发Hadoop商业版本和基于Hadoop的大数据分析工具,单独或者与传统IT厂商合作提供企业级大数据解决方案。这些新兴大数据企业成为资本市场的热点。国内华为、联想、浪潮、曙光等一批IT厂商也都纷纷推出大数据解决方案。但总体上,国内大数据解决方案提供商实力较弱,产品一些关键行业还未形成影响力,新兴大数据解决方案初创企业也凤毛麟角。
|
|
|
|
|
|
大数据处理服务提供商主要以服务的方式为企业和个人用户提供大数据海量数据分析能力和大数据价值挖掘服务。按照服务模式进行划分,大数据处理服务提供商可以分为以下四类。
|
|
|
|
第一类是在线纯分析服务提供商。此类服务商主要是互联网企业、大数据分析软件商和新创企业等,通过SaaS或PaaS云服务形式为用户提供服务。典型的服务如谷歌提供的大数据分析工具Big Query、亚马逊提供的云数据仓库服务RedShift、微软的Azure HDInsigh1010data提供的商业智能服务等。国内一些云服务商也逐步开始提供大数据相关云服务,如阿里云的开放数据处理服务(ODPS)、百度的大数据引擎、腾讯的数据云等。
|
|
|
|
第二类是既提供数据又提供分析服务的在线提供商。此类服务商主要是拥有海量用户数据的大型互联网企业,主要以SaaS形式为用户提供大数据服务,服务背后以自有大数据资源为支撑。典型的服务如谷歌Facebook的自助式广告下单服务系统、Twitter基于实时搜索数据的产品满意度分析等。国内百度推出的大数据营销服务“司南”就属于此类。
|
|
|
|
第三类是单纯提供离线分析服务的提供商。此类服务商主要为企业提供专业、定制化的大数据咨询服务和技术支持,主要集中为大数据咨询公司、软件商等,例如专注于大数据分析的奥浦诺管理咨询公司(Opera Solutions)、数据分析服务提供商美优管理顾问公司(Mu Sigma)等。
|
|
|
|
第四类是既提供数据又提供离线分析服务的提供商。此类服务商主要集中在信息化水平较高、数据较为丰富的传统行业。例如日本日立集团(Hitachi)于2013年6月初成立的日立创新分析全球中心,其广泛收集汽车行驶记录、零售业购买动向、患者医疗数据、矿山维护数据和资源价格动向等庞大数据信息,并基于收集的海量信息开展大数据分析业务。又如美国征信机构Equifax基于全球8000亿条企业和消费者行为数据,提供70余项面向金融的大数据分析离线服务。
|
|
|
|
|
|
既然数据成为了重要的资源和生产要素,必然会产生供应与流通需求。数据资源提供商因此应运而生,它是大数据产业的特有环节,也是大数据资源化的必然产物。数据资源提供商,包括数据拥有者和数据流通平台两个主要类型。数据拥有者可以是企业、公共机构或者个人。数据拥有者通常直接以免费或有偿的方式为其他有需求的企业和用户提供原数据或者处理过的数据。例如美国电信运营商Verizon推出的大数据应用精准营销洞察(Precision Market Insights),将向第三方企业和机构出售其匿名化和整合处理后的用户数据。国内阿里巴巴公司推出的淘宝量子恒道、数据魔方和阿里数据超市等,属于此种类型。
|
|
|
|
数据数据流通平台是多家数据拥有者和数据需求方进行数据交换流通的场所。按平台服务目的不同,可分为政府数据开放平台和数据交易市场。
|
|
|
|
(1)政府数据开放平台。主要提供政府和公共机构的非涉密数据开放服务,属于公益性质。全球不少国家已经加入到开放政府数据行动,推出公共数据库开放网站,例如美国数据开放网站Data.gov已有超过37万个数据集、1209个数据工具、309个网页应用和137个移动应用,数据源来自171个机构。国内地方政府数据开放平台开始出现,如国家统计局的国家数据网站、北京市政府和上海市政府的信息资源平台等数据开放平台正在建设过程中。
|
|
|
|
(2)数据交易市场。商业化的数据交易活动催生了多方参与的第三方数据交易市场。国际上比较有影响力的有微软的AzureData Marketplace、被甲骨文收购的BlueKai、DataMarket、Factual、Infochimps、DataSift等等,主要提供地理空间、营销数据和社交数据的交易服务。大数据交易市场发展刚刚起步,在市场机制、交易规则、定价机制、转售控制和隐私保护等方面还有很多工作要做。国内,2014年2月,在北京市和中关村管委会指导下,中关村大数据交易产业联盟成立,将在国内推动国内大数据交易相关规范化方面开展工作。
|
|
|
|
|
|
|
|
电子商务发展到今天,其营销平台、营销方式都发生了很大的改变。电子商务平台、移动终端、社交网络以及物联网等设备的使用大大增加了消费者数据,而云计算、复杂分析系统等大数据处理手段,为人们整合各个渠道消费者数据、形成有用的营销信息提供了可能。与传统的电子商务数据处理方式相比,大数据处理方式更快捷、更精细,它给我们科学分析消费者偏好及其消费行为轨迹提供巨大帮助。特别是在移动设备进入电子商务领域后,地理位置服务信息处理使电子商务一对一精准营销成为可能,极大程度提升了电子商务营销的准确性,有力地支撑了电子商务营销的精准化与实时化。
|
|
|
|
|
|
在传统电子商务营销背景下,企业与消费者总是处于双向信息不对称状态。一方面企业很难掌握消费者的消费行为和消费习惯,另一方面消费者了解企业产品的信息渠道相对较窄。进入大数据时代后,企业可以通过科学分析海量数据来获得更加丰富的消费者信息,从而针对不同消费者消费需求,提供特定的产品和服务,以最大限度地提高其满意度。消费者可以通过移动终端等渠道及时向电子商务企业传递信息,为企业进行个性化服务提供依据。由此可以推断,未来电子商务价值创造将会围绕消费者个性化需求展开,并将消费者纳入到企业产品设计与生产过程,实现共同的价值创造。
|
|
|
|
|
|
大数据等新型信息技术可以促进各个渠道的跨界数据整合,使所有围绕消费者消费行为的价值链、供应链企业成为一个整体。如大数据可以将地理位置不同、从事行业不同的研发、生产、加工、营销、仓储、配送、服务等各环节企业在满足消费者消费需求这一共同目的下组成动态联盟,通过彼此协作和创造,真正为消费者提供个性化产品和服务。相对于传统意义上的供应链,通过大数据连接起来的动态联盟反应速度更快、智能化程度更高,这既有利于联盟内企业的信息、资源共享,也有利于联盟内企业的分工协作,从而创造新的价值。
|
|
|
|
|
|
电子商务中应用众多的新型信息技术产生了生产、消费、金融、物流等一系列大数据,这些本属于不同领域的大数据在被综合运用的过程中会产生新的融合,从而形成新的增值服务。如电子商务中产生的买卖双方信息、物流信息、金融信息,如果加以整合肯定能够使企业在市场竞争中处于比较有利的位置。在此基础上,企业还可以积极开展类似金融信用服务、供应链整合等增值服务。随着大数据的广泛应用,加之大数据分析手段创新,已经产生了互联网金融等多个增值服务,给包括电子商务企业在内的众多中小企业提供了新的发展空间。假以时日,大数据还会催生更多新型增值服务模式、产生众多的产业。
|
|
|