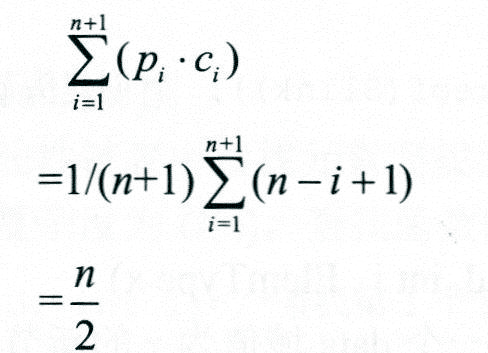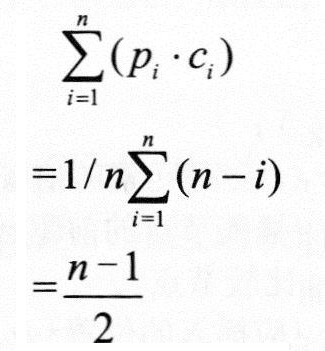|
|
|
|
|
|
|
线性表的顺序存储结构采用一组连续的存储单元依次存储线性表中的各数据元素。建立一个数组V,线性表的长度为N,V[i]表示第i个分量,第i个分量是线性表中第i个元素ai在计算机存储器中的映象,即V[i]=ai。若线性表的第一个元素的存储地址是LOC(a1),每个元素用L个存储单元,则表的第i个元素的存储地址为:LOC(ai)=LOC(a1)+(i-1)*L。
|
|
|
|
假设线性表的数据元素的类型为ElemType(在实际应用中,此类型应根据实际问题中出现的数据元素的特性具体定义,如为int、float类型等),线性表的顺序表的C语言描述如下:
|
|
|
|
|
|
从中可以看出,顺序表是由数组data和len两部分组成的。为了反映data和len之间的关系,上述类型定义中将它们说明为结构体类型Sqlist的两个域。这样,Sqlist类型就完全描述了顺序表的组织。
|
|
|
|
|
|
由于C语言中数组的下标是从0开始的,所以,在逻辑上所指的"第k个位置"实际上对应的是顺序表的"第k-1个位置"。这里仅给出在顺序表上线性表的插入和删除函数。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其中pi是在第i个元素前插入元素的概率,ci是在第i个元素前插入元素时元素移动次数。
|
|
|
|
|
|
|
|
|
|
其中pi是在第i个元素前删除元素的概率,ci是在第i个元素前删除元素时元素移动次数。
|
|
|
|
|
|
|
|
单链表中的每个节点由两部分组成:数据域和指针域。节点形式如下:
|
|
|
|
|
|
其中,data部分称为数据域,用于存储线性表的一个数据元素(节点)。next部分称为指针域或链域,用于存放一个指针,该指针指向本节点所含数据域元素的直接后继所在的节点。若数据元素的类型用ElemType表示,则单链表的类型定义如下:
|
|
|
|
|
|
单链表分为带头节点(其next域指向第一个节点)和不带头节点两种类型,由于头指针的设置使得对链表的第一个位置上的操作与在表其他位置上的操作一致,因而可简化运算的实现过程。
|
|
|
|
|
|
1)初始化函数initlist(Slink *head)
|
|
|
|
初始化函数用于创建一个头节点,由head指向它,该节点的next域为空,data域未设定任何值。由于调用该函数时,指针head在本函数中指向的内容发生改变,为了返回改变的值,因此使用了应用型参数,其时间复杂度为O(1)。初始化函数的语法如下:
|
|
|
|
|
|
2)插入函数insert(Slink *head, int i, ElemType x)
|
|
|
|
插入函数的设计思想是:创建一个data域值为x的新节点*p,然后插入到head所指向的单链表的第i个节点之前。为保证插入正确有效,必须查找到指向第i个节点的前一个节点的指针,主要的时间耗费在查找上,因而在长度为n的线性单链表进行插入操作的时间复杂度为O(n)。插入函数的语法如下:
|
|
|
|
|
|
3)删除函数delete(Slink *head, int i, ElemType x)
|
|
|
|
删除函数的设计思想是:线性链表中元素的删除要修改被删除元素前驱的指针,回收被删除元素所占的空间。主要的时间耗费在查找上,因而在长度为n线性单链表进行删除操作的时间复杂度为O(n)。删除函数的语法如下:
|
|
|
|
|
|
4)查找函数get(Slink *head, int i)
|
|
|
|
查找函数的设计思想是:线性链表中查找元素要找元素前驱的指针。在长度为n的线性单链表进行查找操作的时间复杂度为O(n)。查找函数的语法如下:
|
|
|
|
|
|
5)求单链表长函数Length(Slink *head)
|
|
|
|
求单链表长函数的设计思想是:通过遍历的方法,从头数到尾,即可得到单链表长。求单链表长函数的语法如下:
|
|
|
|
|
|
|
|
带头节点的单链表和不带头节点的单链表的区别主要体现在其结构上和算法操作上。
|
|
|
|
在结构上,带头节点的单链表不管链表是否为空,均含有一个头节点;而不带头节点的单链表不含头节点。
|
|
|
|
在操作上,带头节点的单链表的初始化为申请一个头节点,且在任何节点位置进行的操作算法一致;而不带头节点的单链表让头指针为空,同时其他操作要特别注意空表和第一个节点的处理。下面列举带头节点的单链表插入操作和不带头节点的插入操作的区别。
|
|
|
|
|
|
|
|
1)带头节点的单链表插入函数insert(Slink *head, int i, ElemType x)
|
|
|
|
带头节点的单链表插入函数的设计思想是:创建一个data域值为x的新节点*p,然后插入到head所指向的单链表的第i个节点之前。为保证插入正确有效,必须查找到指向第i个节点的前一个节点的指针,主要的时间耗费在查找上,因而在长度为n的线性单链表中进行插入操作的时间复杂度为O(n)。
|
|
|
|
2)不带头节点的单链表插入函数insert(inti, ElemTypex)
|
|
|
|
不带头节点的单链表插入函数的设计思想是:创建一个data域值为x的新节点*p,然后插入到单链表的第i个节点之前。由于不带头节点,当插入位值i=1时,其算法与i>1时有很大差别,必须单独处理。为保证插入正确有效,必须查找到指向第i个节点的前一个节点的指针,主要的时间耗费在查找上,因而在长度为n的线性单链表中进行插入操作的时间复杂度为O(n)。
|
|
|
|
可见,带头节点的单链表插入操作和不带头节点的插入操作在算法实现上有很大的区别,主要体现在初始化、能否插入成功的判别及插入时的操作上,在带头节点的单链表上插入在任何位置上都是相同的,而在不带头节点单链表的第一个节点和其他节点前插入操作是不同的。
|
|
|
|
对于带头节点的单链表和不带头节点的单链表在其他操作上的区别可类似得到。
|
|
|
|
|
|
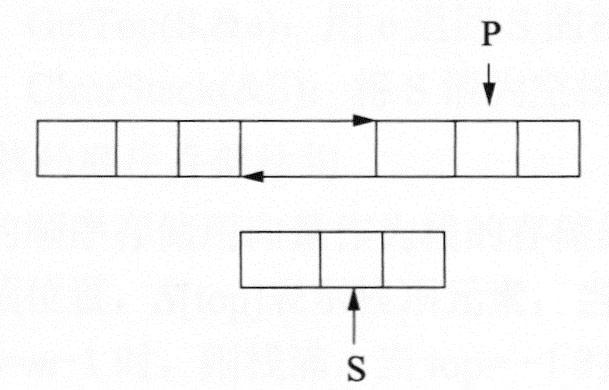
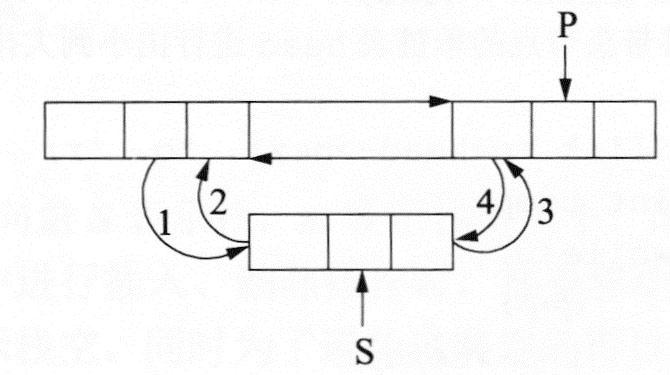
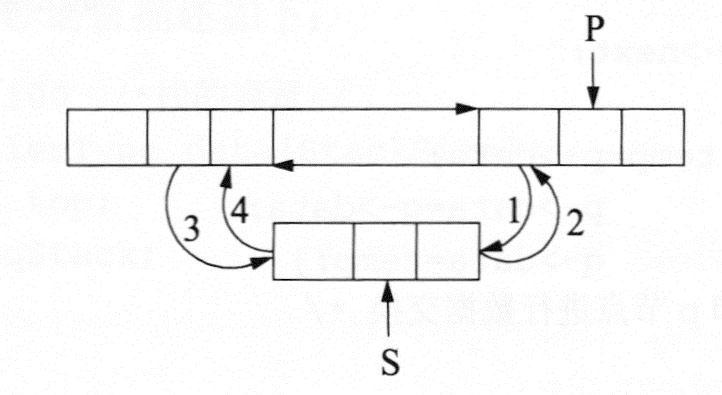
链表的指针修改必须保持其逻辑结构的次序,否则将违背线性表的特征,尤其是进行插入和删除操作。下面通过双向链表的插入操作来说明,若在如下1图所示的P所指向的节点之前插入一个S所指向的节点,则需进行指针的修改,修改指针的策略有如下2图和下3图所示两种,指针的修改次序为1, 2, 3, 4。根据线性表的性质可知,下图可保证指针修改成功;而下图中指针修改不成功,主要原因是其首先将P的前驱指向S,这样P节点的原前驱节点就不能找到了,因而指针修改步骤3和步骤4不成立。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可见,指针的修改次序是链表插入成功与否的关键因素之一;同理,在进行节点的删除时也同样需要主要指针的次序。
|
|
|
|
|
|
很多优秀的算法都是建立在顺序存储结构上的,如何在链式存储结构上实现这些优秀算法,是考生应注意的问题。近年来,在不少程序员水平考试试题中都出现了这样的题目。这里,我们通过在顺序存储结构和链式存储结构两种存储结构上实现选择排序来说明。顺序存储结构下的算法sort的语法如下:
|
|
|
|
|
|
依据顺序存储结构下的算法sort1可以拓展到链式存储结构下的算法sort2。下面将算法sort1拓展到链式存储结构下的算法sort2,语法如下:
|
|
|
|
|
|
可见,只要充分领会顺序存储结构下的算法思想,熟悉链表存储结构就可通过掌握顺序存储结构下的算法得到链表存储结构下的相应算法。
|
|
|