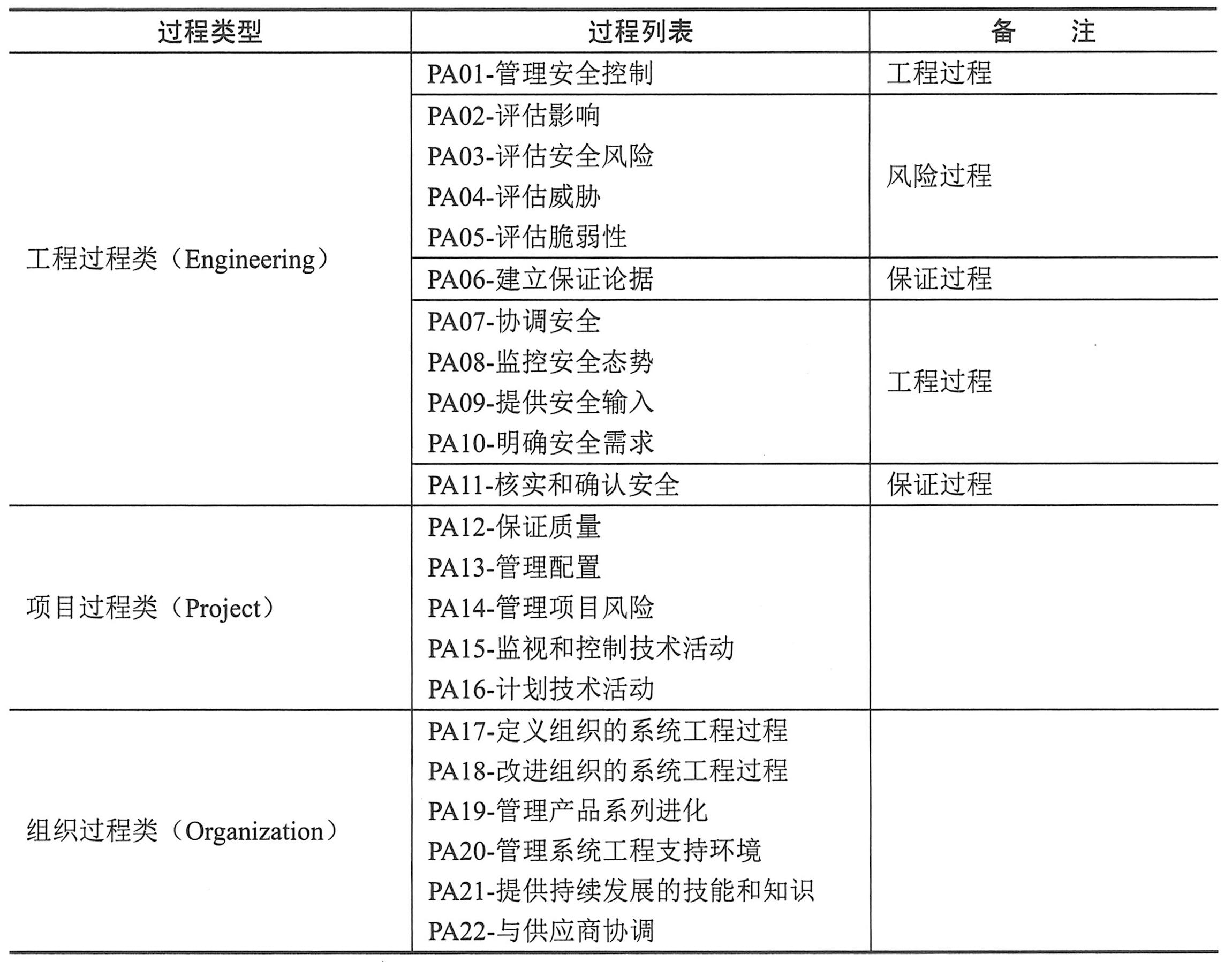
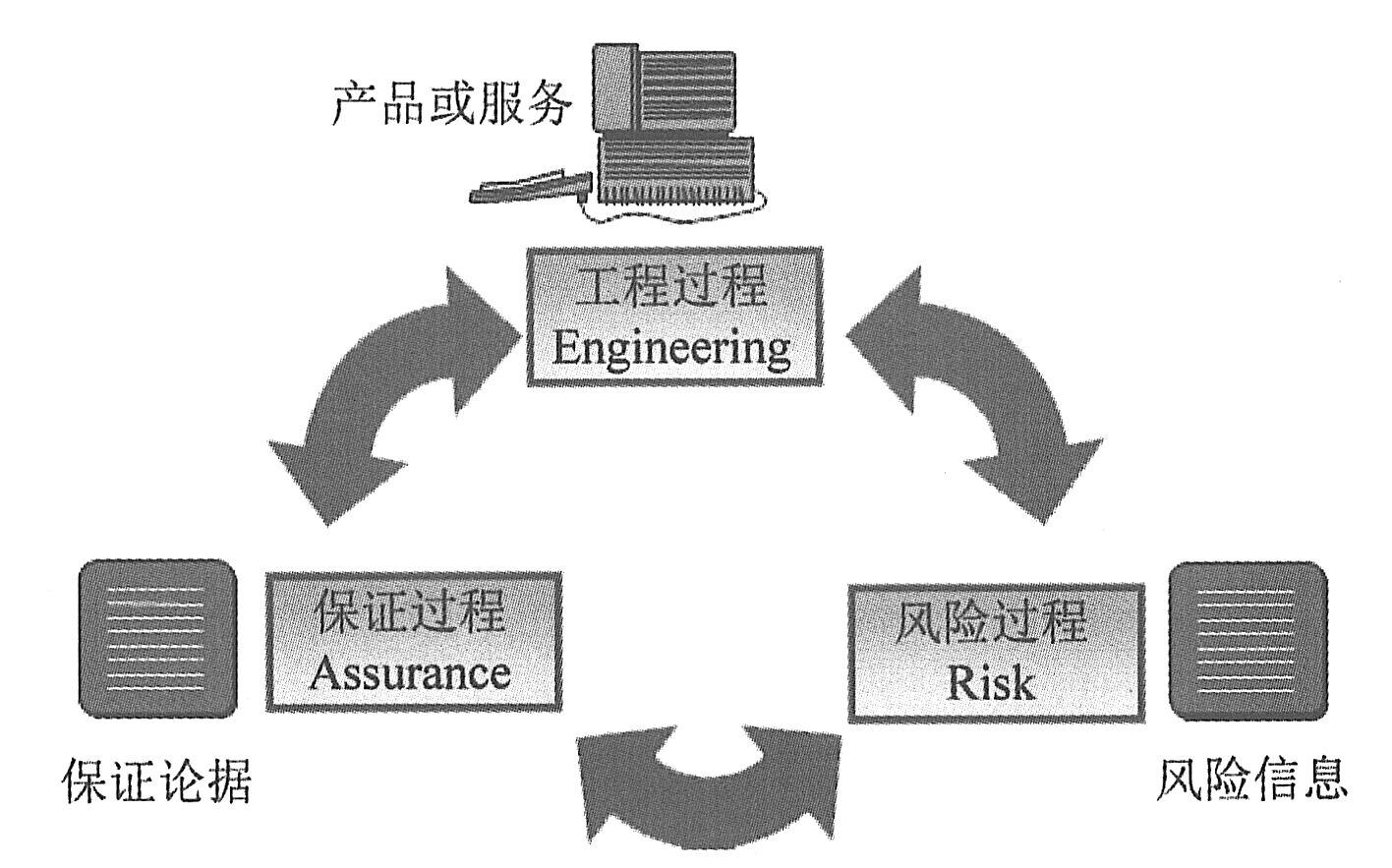
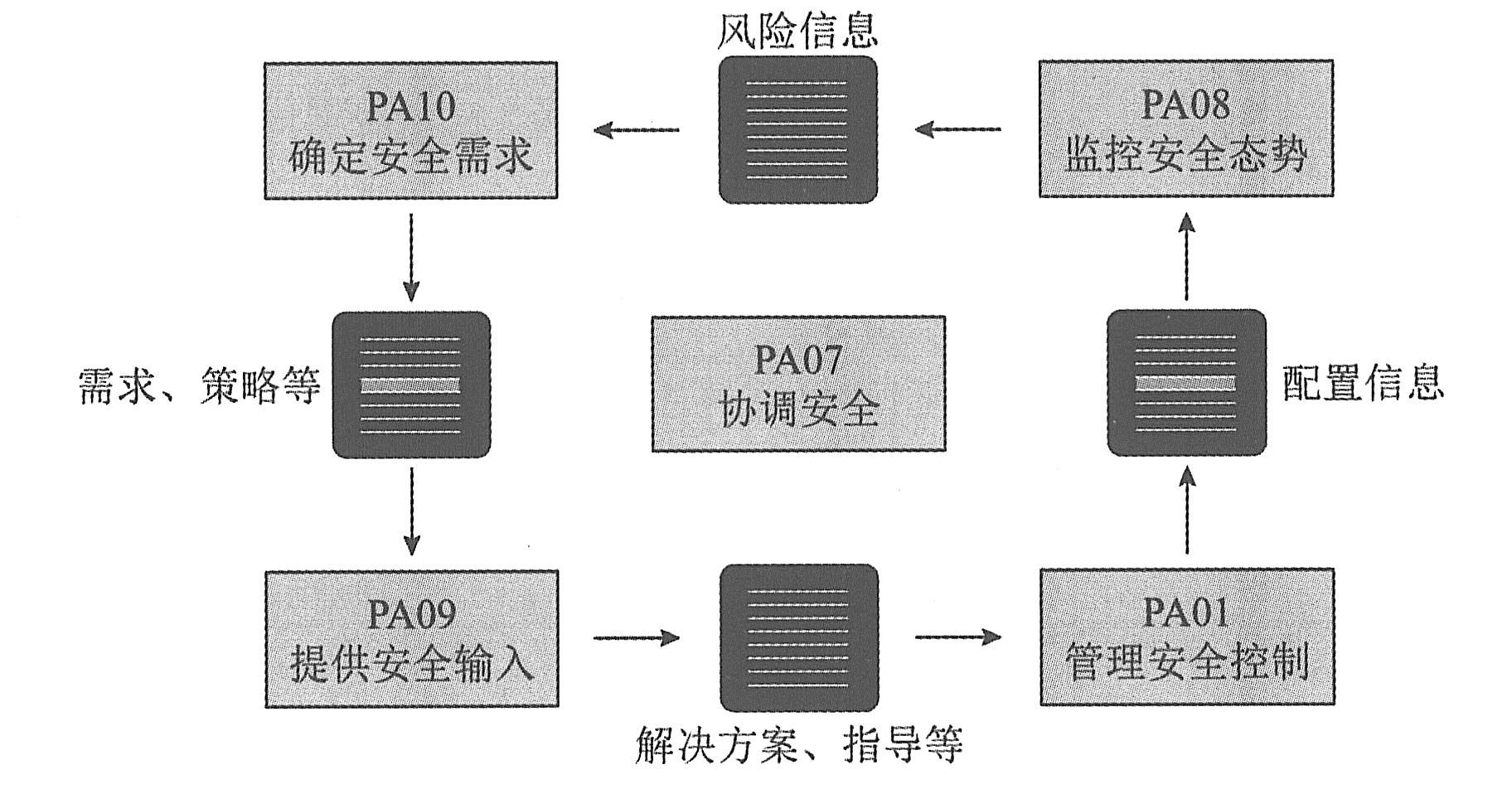
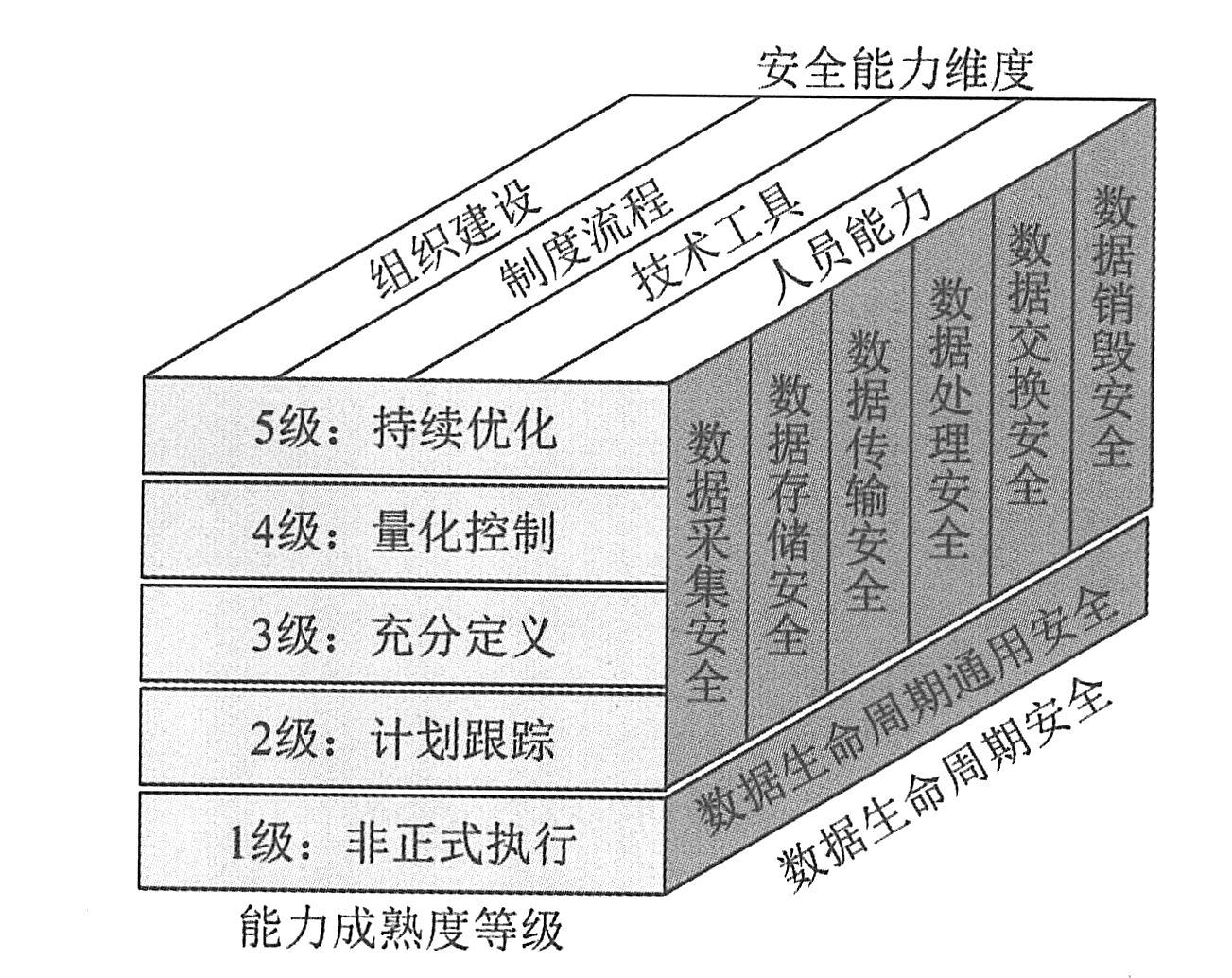
|
|
|
在信息系统项目管理师的考试大纲中,对于最新技术发展趋势并无明确要求。但从考题分布来看,从2011年开始考察考生是否关注IT行业的技术发展趋势。概括来说,最新的IT技术发展趋势主要包含以下各个方面。
|
|
|
|
|
|
云是网络、互联网的一种比喻说法。过去在图中往往用云来表示电信网,后来也用来表示互联网和底层基础设施的抽象。云计算(cloud computing)是主机计算到客户端-服务器计算的大转变之后的又一种巨变。云计算的出现并非偶然,早在上世纪60年代,麦卡锡就提出了把计算能力作为一种像水和电一样的公用事业提供给用户的理念,这成为云计算思想的起源。在20世纪80年代网格计算、90年代公用计算,21世纪初虚拟化技术、SOA、SaaS应用的支撑下,云计算作为一种新兴的资源使用和交付模式逐渐为学界和产业界所认知。
|
|
|
|
|
|
.资源配置动态化。根据消费者的需求动态划分或释放不同的物理和虚拟资源,当增加一个需求时,可通过增加可用的资源进行匹配,实现资源的快速弹性提供;如果用户不再使用这部分资源时,可释放这些资源。云计算为客户提供的这种能力是无限的,实现了IT资源利用的可扩展性。
|
|
|
|
.需求服务自助化。云计算为客户提供自助化的资源服务,用户无需同提供商交互就可自动得到自助的计算资源能力。同时云系统为客户提供一定的应用服务目录,客户可采用自助方式选择满足自身需求的服务项目和内容。
|
|
|
|
.网络访问便捷化,客户可借助不同的终端设备,通过标准的应用实现对网络访问的可用能力,使对网络的访问无处不在。
|
|
|
|
.服务可计量化。在提供云服务过程中,针对客户不同的服务类型,通过计量的方法来自动控制和优化资源配置。即资源的使用可被监测和控制,是一种即付即用的服务模式。
|
|
|
|
.资源的虚拟化。借助于虚拟化技术.将分布在不同地区的计算资源进行整合.实现基础设施资源的共享。
|
|
|
|
|
|
|
|
IaaS(Infrastructure-as-a- Service):基础设施即服务。消费者通过Internet可以从完善的计算机基础设施获得服务。
|
|
|
|
|
|
PaaS(Platform-as-a- Service):平台即服务。PaaS实际上是指将软件研发的平台作为一种服务,以SaaS的模式提交给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。
|
|
|
|
|
|
SaaS(Software-as-a- Service):软件即服务。它是一种通过Internet提供软件的模式,用户无需购买软件,而是向提供商租用基于Web的软件,来管理企业经营活动。
|
|
|
|
|
|
|
|
物联网就是物物相连的互联网。这有两层含义:第一,物联网的核心和基础仍然是互联网,是在互联网基础上的延伸和扩展的网络;第二,其用户端延伸和扩展到了任何物品与物品之间,进行信息交换和通信。
|
|
|
|
|
|
1)MAI(M2M Application Integration),内部MaaS;
|
|
|
|
2)MaaS(M2M As A Service),MMO,Multi-Tenants(多租户模型)。
|
|
|
|
随着物联网业务量的增加,对数据存储和计算量的需求将带来对云计算能力的要求:
|
|
|
|
1)云计算:从计算中心到数据中心,属于物联网的初级阶段;
|
|
|
|
2)在物联网高级阶段,可能出现MVNO/MMO营运商,需要虚拟化云计算技术,例如与SOA等技术相结合实现互联网的广泛服务:TaaS(everyTHING As A Service)。
|
|
|
|
|
|
云安全(Cloud Security)是一个从云计算演变而来的新名词。云安全的策略构想是:使用者越多,每个使用者就越安全,因为如此庞大的用户群,足以覆盖互联网的每个角落,只要某个网站被挂马或某个新木马病毒出现,就会立刻被截获。云安全通过网状的大量客户端对网络中软件行为的异常监测,获取互联网中木马、恶意程序的最新信息,推送到Server端进行自动分析和处理,再把病毒和木马的解决方案分发到每一个客户端。
|
|
|
|
|
|
云存储是在云计算概念上延伸和发展出来的一个新的概念,是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。当云计算系统运算和处理的核心是大量数据的存储和管理时,云计算系统中就需要配置大量的存储设备,那么云计算系统就转变成为一个云存储系统,所以云存储是一个以数据存储和管理为核心的云计算系统。
|
|
|
|
|
|
私有云(Private Cloud)是将云基础设施与软硬件资源创建在防火墙内,以供机构或企业内各部门共享数据中心内的资源。创建私有云,除了硬件资源外,一般还有云设备(IaaS)软件,对应的商业软件有VMware的vSphere和Platform Computing的ISF,开放源代码的云设备软件主要有Eucalyptus和OpenStack。
|
|
|
|
|
|
云游戏是以云计算为基础的游戏方式,在云游戏的运行模式下,所有游戏都在服务器端运行,并将渲染完毕后的游戏画面压缩后通过网络传送给用户。在客户端,用户的游戏设备不需要任何高端处理器和显卡,只需要基本的视频解压能力就可以了。
|
|
|
|
|
|
基于云的流媒体平台采用分布式架构部署,分为Web服务器,数据库服务器、直播服务器和流服务器,如有必要还可在信息中心架设采集工作站搭建网络电视或实况直播应用。
|
|
|
|
|
|
物联网是新一代信息技术的重要组成部分。其英文名称是“The Internet of things”。顾名思义,物联网就是物物相连的互联网。这有两层意思:第一,物联网的核心和基础仍然是互联网,是在互联网基础上的延伸和扩展的网络;第二,其用户端延伸和扩展到了任何物品与物品之间,进行信息交换和通信。因此,物联网的定义是通过射频识别(RFID)、红外感应器、全球定位系统、激光扫描器等信息传感设备,按约定的协议,将任何物品与互联网相连接,进行信息交换和通信,以实现对物品的智能化识别、定位、跟踪、监控和管理的一种网络。
|
|
|
|
|
|
|
|
.公有物联网:基于互联网向公众或大型用户群体提供服务;
|
|
|
|
.社区物联网:向一个关联的“社区”或机构群体(如一个城市政府下属各个机构等)提供服务;
|
|
|
|
.混合物联网:是上述的两种或以上的物联网的组合,但后台有统一运维实体。
|
|
|
|
|
|
从技术架构上来看,物联网可分为三层:感知层、网络层和应用层。
|
|
|
|
感知层由各种传感器以及传感器网关构成,包括二氧化碳浓度传感器、温度传感器、湿度传感器、二维码标签、RFID标签和读写器、摄像头、GPS等感知终端。感知层的作用相当于人的眼耳鼻喉和皮肤等神经末梢,它是物联网识别物体、采集信息的来源,其主要功能是识别物体,采集信息。
|
|
|
|
网络层由各种私有网络、互联网、有线和无线通信网、网络管理系统和云计算平台等组成,相当于人的神经中枢和大脑,负责传递和处理感知层获取的信息。
|
|
|
|
应用层是物联网和用户(包括人、组织和其他系统)的接口,它与行业需求结合,实现物联网的智能应用。
|
|
|
|
|
|
物联网作为一种新的技术发展趋势,目前在多个行业已经有所应用,包括绿色农业、工业监控、公共安全、城市管理、远程医疗、智能家居、智能交通和环境监测等各个行业。
|
|
|
|
|
|
三网融合是指电信网、广播电视网、互联网在向宽带通信网、数字电视网、下一代互联网演进过程中,三大网络通过技术改造,其技术功能趋于一致,业务范围趋于相同,网络互联互通、资源共享,能为用户提供语音、数据和广播电视等多种服务。三合并不意味着三大网络的物理合一,而主要是指高层业务应用的融合。三网融合应用广泛,遍及智能交通、环境保护、政府工作、公共安全、平安家居等多个领域。以后的手机可以看电视、上网,电视可以打电话、上网,电脑也可以打电话、看电视。三者之间相互交叉,形成你中有我、我中有你的格局。
|
|
|
|
三网融合打破了此前广电在内容输送、电信在宽带运营领域各自的垄断,明确了互相进入的准则——在符合条件的情况下,广电企业可经营增值电信业务、比照增值电信业务管理的基础电信业务、基于有线电网络提供的互联网接入业务等;而国有电信企业在有关部门的监管下,可从事除时政类节目之外的广播电视节目生产制作、互联网视听节目信号传输、转播时政类新闻视听节目服务,IPTV传输服务、手机电视分发服务等。
|
|
|
|
|
|
.基础数字技术。数字技术的迅速发展和全面采用,使电话、数据和图像信号都可以通过统一的编码进行传输和交换,所有业务在网络中都将成为统一的“0”或“1”的比特流。所有业务在数字网中都将成为统一的0/1比特流,从而使得话音、数据、声频和视频各种内容(无论其特性如何)都可以通过不同的网络来传输、交换、选路处理和提供,并通过数字终端存储起来或以视觉、听觉的方式呈现在人们的面前。目前,数字技术已经在电信网和计算机网中得到了全面应用,并在广播电视网中迅速发展起来。数字技术的迅速发展和全面采用,使话音、数据和图像信号都通过统一的数字信号编码进行传输和交换,为各种信息的传输、交换、选路和处理奠定了基础。
|
|
|
|
.宽带技术。宽带技术的主体就是光纤通信技术。网络融合的目的之一是通过一个网络提供统一的业务。若要提供统一业务就必须要有能够支持音视频等各种多媒体(流媒体)业务传送的网络平台。这些业务的特点是业务需求量大、数据量大、服务质量要求较高,因此在传输时一般都需要非常大的带宽。另外,从经济角度来讲,成本也不宜太高。这样,容量巨大且可持续发展的大容量光纤通信技术就成了传输介质的最佳选择。宽带技术特别是光通信技术的发展为传送各种业务信息提供了必要的带宽、传输质量和低成本。作为当代通信领域的支柱技术,光通信技术正以每10年增长100倍的速度发展,具有巨大容量的光纤传输网是“三网”理想的传送平台和未来信息高速公路的主要物理载体。目前,无论是电信网,还是计算机网、广播电视网,大容量光纤通信技术都已经得到了广泛的应用。
|
|
|
|
.软件技术。软件技术是信息传播网络的神经系统,软件技术的发展,使得三网络及其终端都能通过软件变更最终支持各种用户所需的特性、功能和业务。现代通信设备已成为高度智能化和软件化的产品,今天的软件技术已经具备三网业务和应用融合的实现手段。
|
|
|
|
.IP技术。内容数字化后,还不能直接承载在通信网络介质之上,还需要通过IP技术在内容与传送介质之间搭起一座桥梁。IP技术(特别是IPv6技术)的产生,满足了在多种物理介质与多样的应用需求之间建立简单而统一的映射需求,可以顺利地对多种业务数据、多种软硬件环境、多种通信协议进行集成、综合、统一,对网络资源进行综合调度和管理,使得各种以IP为基础的业务都能在不同的网络上实现互通。IP协议的普遍采用,使得各种以IP为基础的业务都能在不同的网上实现互通,具体下层基础网络是什么已无关紧要。统一的TCP/IP协议的普遍采用,将使得各种以IP为基础的业务都能在不同的网上实现互通。人类首次具有统一的为三大网都能接受的通信协议,从技术上为三网融合奠定了最坚实的基础.
|
|
|
|
|
|
四网融合是三网融合概念的延伸,即在现有的三网融合的基础上加入电网,成为四网融合。
|
|
|
|
|
|
下一代网络(Next Generation Network),又称为次世代网络。主要思想是在一个统一的网络平台上以统一管理的方式提供多媒体业务,整合现有的市内固定电话、移动电话的基础上,增加多媒体数据服务及其他增值型服务。其中话音的交换将采用软交换技术,而平台的主要实现方式为IP技术,逐步实现统一通信。其中voip将是下一代网络中的一个重点。为了强调IP技术的重要性,业界的主要公司之一思科公司(Cisco Systems)主张称为IP-NGN。
|
|
|
|
NGN是一个分组网络,它提供包括电信业务在内的多种业务,能够利用多种带宽和具有QoS能力的传送技术,实现业务功能与底层传送技术的分离;它允许用户对不同业务提供商网络的自由接入,并支持通用移动性,实现用户对业务使用的一致性和统一性。它是以软交换为核心的,能够提供包括语音、数据、视频和多媒体业务的基于分组技术的综合开放的网络架构,代表了通信网络发展的方向。NGN具有分组传送、控制功能从承载、呼叫/会话、应用/业务中分离、业务提供与网络分离、提供开放接口、利用各基本的业务组成模块、提供广泛的业务和应用、端到端QoS和透明的传输能力通过开放的接口规范与传统网络实现互通、通用移动性、允许用户自由地接入不同业务提供商、支持多样标志体系,融合固定与移动业务等特征。
|
|
|
|
|
|
.多媒体化:NGN中发展最快的特点将是多媒体特点,同时多媒体特点也是NGN最基本、最明显的特点;
|
|
|
|
.开放性:NGN网络具有标准的、开放的接口,为用户快速提供多样的定制业务;
|
|
|
|
.个性化:个性化业务的提供将给未来的运营商带来丰厚的利润;
|
|
|
|
.虚拟化:虚拟业务将是个人身份、联系方式以至于住所都虚拟化。用户可以使用个人号码,号码可以携带等虚拟业务,实现在任何时候、任何地方的通信;
|
|
|
|
.智能化:NGN的通信终端具有多样化、智能化的特点,网络业务和终端特性结合起来可以提供更加智能化的业务。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
集成电路(IC,Integrated Circuit)是一种微型电子器件或部件。采用一定的工艺,把一个电路中所需的晶体管、二极管、电阻、电容和电感等元件及布线互连一起,制作在一小块或几小块半导体晶片或介质基片上,然后封装在一个管壳内,成为具有所需电路功能的微型结构;其中所有元件在结构上已组成一个整体,使电子元件向着微小型化、低功耗和高可靠性方面迈进了一大步。它在电路中用字母“IC”表示。集成电路发明者为杰克·基尔比(基于硅的集成电路)和罗伯特·诺伊思(基于锗的集成电路)。当今半导体工业大多数应用的是基于硅的集成电路。
|
|
|
|
|
|
集成电路按制作工艺可分为半导体集成电路和膜集成电路,膜集成电路又分类厚膜集成电路和薄膜集成电路。
|
|
|
|
|
|
.SSI小规模集成电路(Small Scale Integrated circuits)
|
|
|
|
.MSI中规模集成电路(Medium Scale Integrated circuits)
|
|
|
|
.LSI大规模集成电路(Large Scale Integrated circuits)
|
|
|
|
.VLSI超大规模集成电路(Very Large Scale Integrated circuits)
|
|
|
|
.ULSI特大规模集成电路(Ultra Large Scale Integrated circuits)
|
|
|
|
.GSI巨大规模集成电路也被称作极大规模集成电路或超特大规模集成电路(Giga Scale Integration)
|
|
|
|
|
|
MEMS是微机电系统(Micro-Electro-Mechanical Systems)的英文缩写。MEMS是美国的叫法,在日本被称为微机械,在欧洲被称为微系统,它是指可批量制作的,集微型机构、微型传感器、微型执行器以及信号处理和控制电路、直至接口、通信和电源等于一体的微型器件或系统。MEMS是随着半导体集成电路微细加工技术和超精密机械加工技术的发展而发展起来的,目前MEMS加工技术还被广泛应用于微流控芯片与合成生物学等领域,从而进行生物化学等实验室技术流程的芯片集成化。
|
|
|
|
MEMS技术的发展开辟了一个全新的技术领域和产业,采用MEMS技术制作的微传感器、微执行器、微型构件、微机械光学器件、真空微电子器件、电力电子器件等在航空、航天、汽车、生物医学、环境监控、军事以及几乎人们所接触到的所有领域中都有着十分广阔的应用前景。MEMS技术正发展成为一个巨大的产业,就像近20年来微电子产业和计算机产业给人类带来的巨大变化一样,MEMS也正在孕育一场深刻的技术变革并对人类社会产生新一轮的影响。
|
|
|
|
|
|
.微系统设计技术。主要是微结构设计数据库、有限元和边界分析、CAD/CAM仿真和模拟技术、微系统建模等,还有微小型化的尺寸效应和微小型理论基础研究等课题,如:力的尺寸效应、微结构表面效应、微观摩擦机理、热传导、误差效应和微构件材料性能等。
|
|
|
|
.微细加工技术。主要指高深度比多层微结构的硅表面加工和体加工技术,利用X射线光刻、电铸的LIGA和利用紫外线的准LIGA加工技术;微结构特种精密加工技术包括微火花加工、能束加工、立体光刻成形加工;特殊材料特别是功能材料微结构的加工技术;多种加工方法的结合;微系统的集成技术;微细加工新工艺探索等。
|
|
|
|
.微型机械组装和封装技术。主要指粘接材料的粘接、硅玻璃静电封接、硅硅键合技术和自对准组装技术,具有三维可动部件的封装技术、真空封装技术等新封装技术。
|
|
|
|
.微系统的表征和测试技术主要有结构材料特性测试技术,微小力学、电学等物理量的测量技术,微型器件和微型系统性能的表征和测试技术,微型系统动态特性测试技术,微型器件和微型系统可靠性的测量与评价技术。
|
|
|