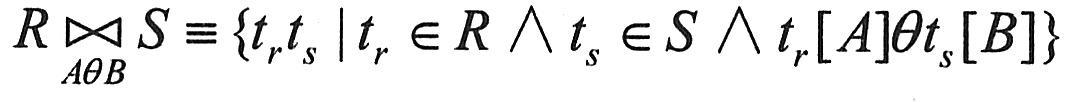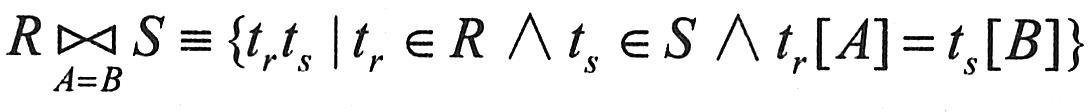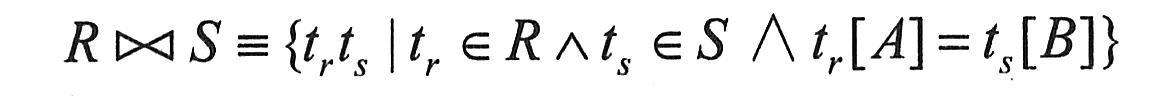|
|
|
在关系数据库中,数据操作主要包括查询和更新两大类。关系数据语言有关系代数语言,关系演算语言、具有关系代数和关系演算双重特点的语言3种。其中关系演算语言又包括元组关系演算语言,域关系演算语言。
|
|
|
|
|
|
传统的集合运算是二目运算,包括并、交、差、广义笛卡儿积4种运算。
|
|
|
|
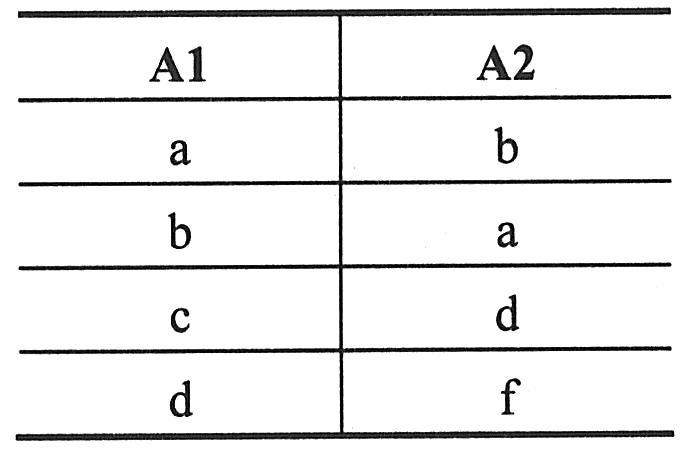
(1)并。设关系R和S具有相同的关系模式,R和S的并是由属于R或属于S的元组组成的集合,记为R∪S。形式定义如下:
|
|
|
|
|
|
|
|
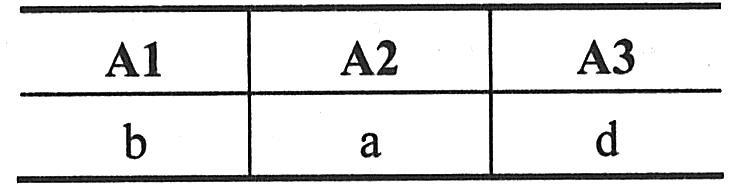
(2)差。关系R和S具有相同的关系模式,R和S的差是由属于R但不属于S的元组组成的集合,记为R-S。形式定义如下:
|
|
|
|
|
|
(3)交。关系R和S具有相同的关系模式,R和S的交是由既属于R又属于S的元组组成的集合,记为R∩S。形式定义如下:
|
|
|
|
|
|
显然,R∩S=R-(R-S),或者R∩S=S-(S-R)。
|
|
|
|
(4)笛卡儿积。设关系R和S元数分别为r和s。R和S的笛卡儿积是一个r+s元的元组集合,每个元组的前r个分量来自R的一个元组,后s个分量来自S的一个元组,记为R×S。形成定义如下:
|
|
|
|
R×S≡{t|t=<tr,ts>∧tr∈R∧ts∈S}
|
|
|
|
若R有m个元组,S有n个元组,则R×S有m×n个元组。
|
|
|
|
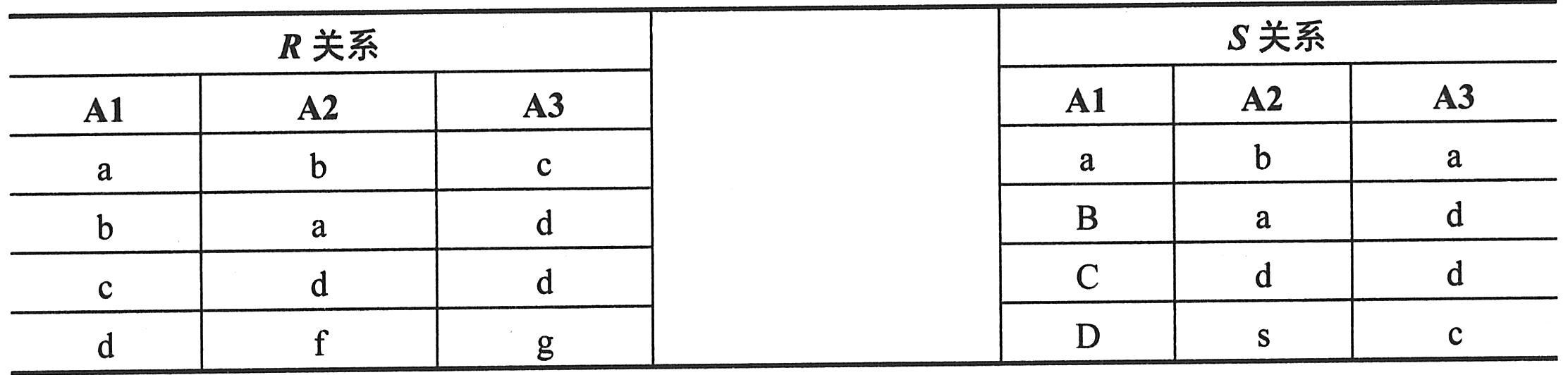
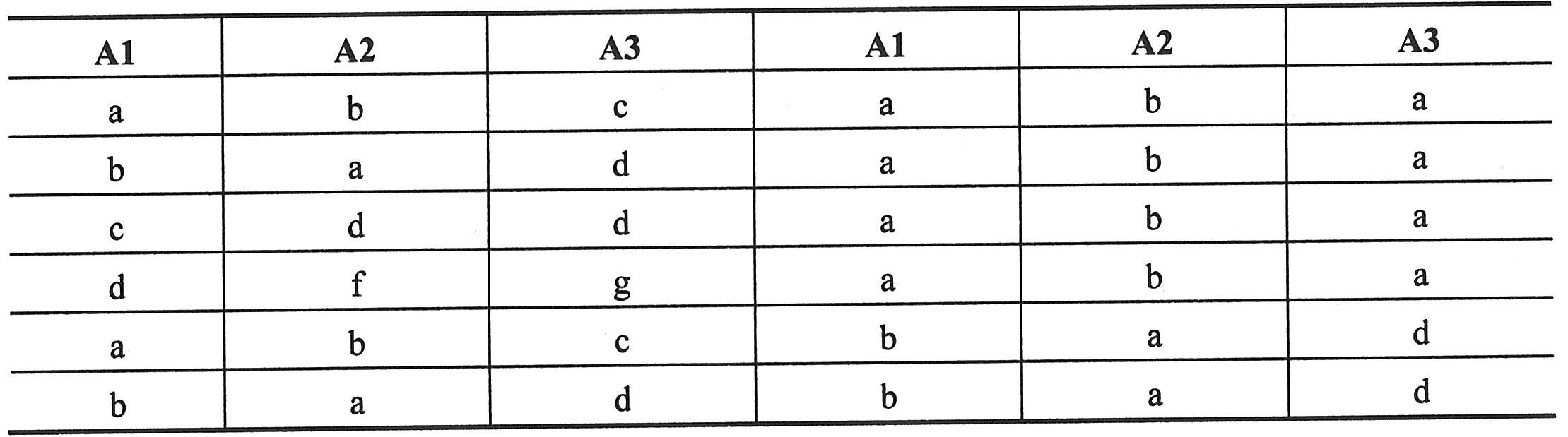
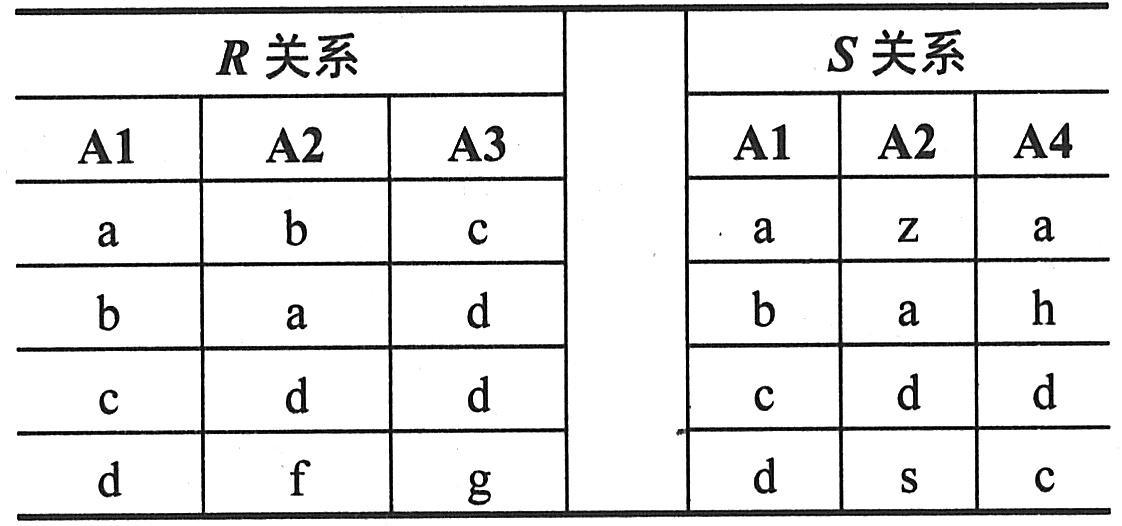
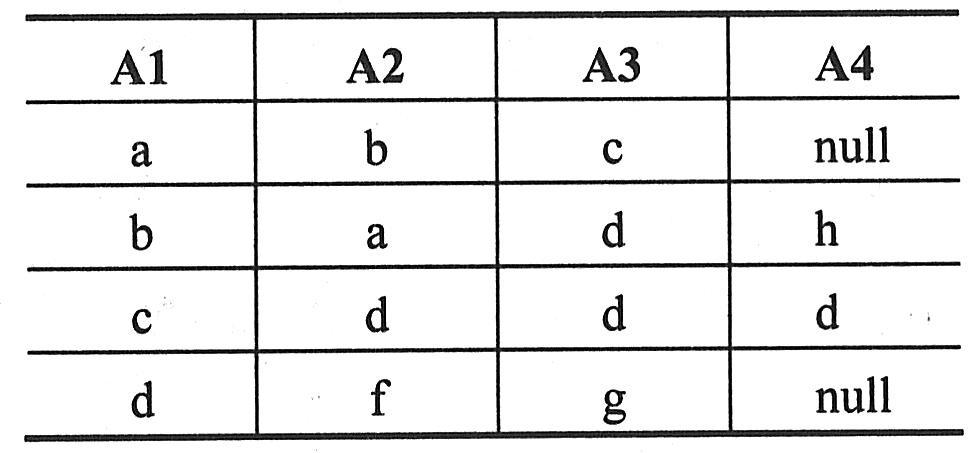
(5)集合运算实例。例如,设关系R和S如下表一所示。则R∪S与R∩S如下表二所示,R-S和S-R如下表三所示,R×S分别如下表四所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在3.4.1节的集合运算基础上,关系数据库还有一些专门的运算,主要有投影、选择、连接、除法和外连接。它们是关系代数最基本的操作,也是一个完备的操作集。在关系代数中,由五种基本代数操作经过有限次复合的式子称为关系代数运算表达式。表达式的运算结果仍是一个关系。我们可以用关系代数表达式表示各种数据查询和更新处理操作。
|
|
|
|
(1)投影。投影操作从关系R中选择出若干属性列组成新的关系,该操作对关系进行垂直分割,消去某些列,并重新安排列的顺序,再删去重复元组。记作:
|
|
|
|
|
|
|
|
(2)选择。选择操作在关系R中选择满足给定条件的所有元组,记作:
|
|
|
|
|
|
其中F表示选择条件,是一个逻辑表达式(逻辑运算符+算术表达式)。选择运算是从行的角度进行的运算。
|
|
|
|
(3)θ连接。θ连接从两个关系的笛卡儿积中选取属性间满足一定条件的元组记作:
|
|
|
|
|
|
其中A和B分别为R和S上度数相等且可比的属性组。θ为“=”的连接,称作等值连接,记作:
|
|
|
|
|
|
如果两个关系中进行比较的分量必须是相同的属性组,并且在结果中把重复的属性列去掉,则称为自然连接,记作:
|
|
|
|
|
|
(4)除法。设两个关系R和S的元数分别为r和s(设r>s>0),那么R÷S是一个(r-s)元的元组的集合。(R÷S)是满足下列条件的最大关系:其中每个元组t与S中每个元组u组成新元组<t,u>必在关系R中。其具体计算公式如下:
|
|
|
|
R÷S=π1,2,…,r-s(R)-π1,2,…,r-s((π1,2,…,r-s(R)×S)-R)
|
|
|
|
(5)外联接。两个关系R和S进行自然连接时,选择两个关系R和S公共属性上相等的元组,去掉重复的属性列构成新关系。这样,关系R中的某些元组有可能在关系S中不存在公共属性值上相等的元组,造成关系R中这些元组的值在运算时舍弃了;同样关系S中的某些元组也可能舍弃。为此,扩充了关系运算左外连接、右外连接和完全外连接。
|
|
|
|
.左外连接:R和S进行自然连接时,只把R中舍弃的元组放到新关系中。
|
|
|
|
.右外连接:R和S进行自然连接时,只把S中舍弃的元组放到新关系中。
|
|
|
|
.完全外连接:R和S进行自然连接时,只把R和S中舍弃的元组都放到新关系中。
|
|
|
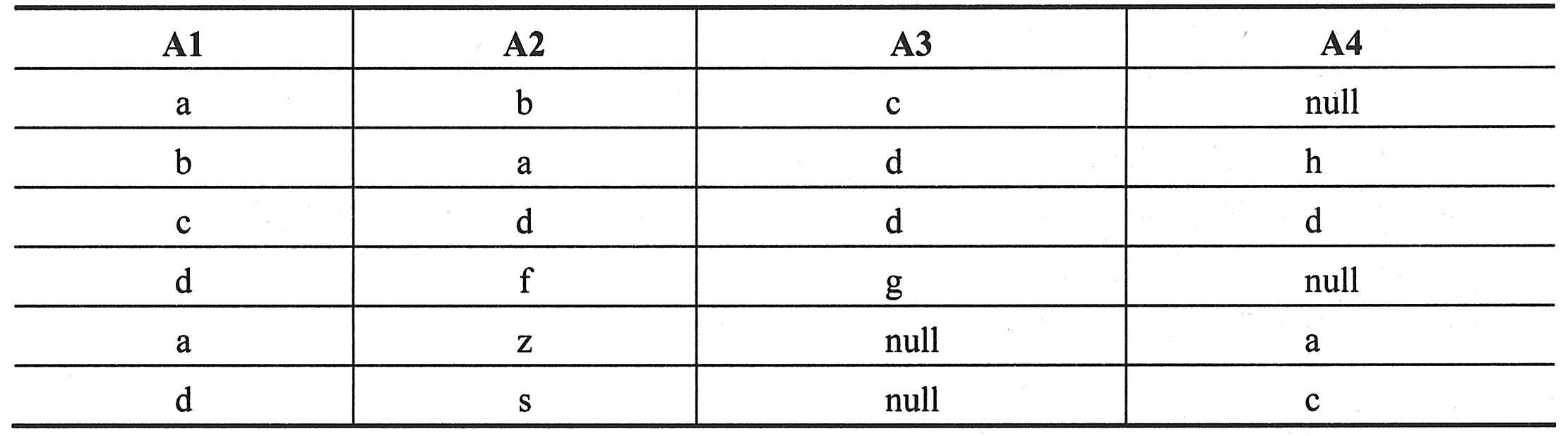
(6)关系运算实例。设两个关系模式R和S如下表一所示,则π1,2(R)的结果如下表二所示,σ1>2(R)的结果如下表三所示, 的结果如下表四所示,R与S的左外连接如下表五所示,R与S的右外连接如下表六所示,R与S的完全外连接如下表七所示。 的结果如下表四所示,R与S的左外连接如下表五所示,R与S的右外连接如下表六所示,R与S的完全外连接如下表七所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在元组演算中,元组演算表达式简称为元组表达式,其一般形式为{t|P(t)},其中,t是元组变量,表示一个元数固定的元组;P是公式,在数理逻辑中也称为谓词,也就是计算机语言中的条件表达式。{t|P(t)}表示满足公式P的所有元组t的集合。
|
|
|
|
在元组表达式中,公式由原子公式组成。原子公式有下列3种形式。
|
|
|
|
(1)R(s),其中R是关系名,s是元组变量。其含义是“s是关系R的一个元组”。
|
|
|
|
(2)s[i]θu[j],其中s和u是元组变量,θ是算术比较运算符,s[i]和u[j]分别是s的第i个分量和u的第j个分量。原子公式s[i]θu[j]表示“元组s的第i个分量与元组u的第j个分量之间满足θ运算”。
|
|
|
|
(3)s[i]θa或aθu[j],其中的a为常量。其含义类似于(2)。
|
|
|
|
在一个公式中,如果元组变量未用存在量词?或全称量词?等符号定义,那么称为自由元组变量,否则称为约束元组变量。公式的递归定义如下:
|
|
|
|
(1)每个原子是一个公式。其中的元组变量是自由变量。
|
|
|
|
(2)如果P1和P2是公式,那么┓P1、P1∨P2、P1∧P2和P1→P2也是公式。
|
|
|
|
(3)如果P1是公式,那么(?s)(P1)和(?s)(P1)也都是公式。
|
|
|
|
(4)公式中各种运算符的优先级从高到低依次为:θ、?和?、┓、∨和∧、→。在公式外还可以加括号,以改变上述优先顺序。
|
|
|
|
(5)公式只能由上述4种形式构成,除此之外构成的都不是公式。
|
|
|
|
|
|
|
|
|
|
(3)(?s)(P1)(s))等价于┓(?s)(┓P1(s))。
|
|
|
|
(?s)(P1(s))等价于┓(?s)(┓P1(s))。
|
|
|
|
|
|
|
|
|
|
(2)R-S可用{t|R(t)∧┓S(t)}表示。
|
|
|
|
(3)R×S可用{t|(?u)(?v)(R(u)∧S(v)∧t[1]=u[1]∧…∧t[r]=u[r]∧t[r+1]=v[1]∧…∧t[r+s]=v[s])}表示,此处设R是r元,S是s元。
|
|
|
|
(4)设投影操作是π2,3(R),那么元组表达式可写成{t|(?u)(R(u)∧t[1]=u[2]∧t[2]=u[3])}。
|
|
|
|
(5)σF(R)可用{t|R(t)∧F′}表示,F′是F的等价表示形式。例如,σ2=′d′(R)可写成{t|(R(t)∧t[2]=′d′)。
|
|
|
例如,设学生S、课程C、学生选课SC的关系模式分别为:S(Sno, Sname, Sage, Saddr)、C(Cno, Cname, Pcno),以及SC(Sno, Cno, Grade)。我们求与关系代数表达式 等价的元组演算表达式。 等价的元组演算表达式。
|
|
|
因为涉及3个关系模式S、SC、C,为了转换成等价的元组演算表达式,需要设置3个元组变量u、v、w,而且这3个元组变量只要用存在量词?限定就可以了。(?u)S(u)表示在S关系中存在一个元组,(?v)SC(v)表示在SC关系中存中一个元组,(?w)C(w)表示在C关系中存在一个元组。因为u[1]对应的是S.Sno,v[1]对应的是SC.Sno,v[2]对应的是SC.Cno,w[1]对应的是C.Cno,w[2]对应的是C.Cname,所以S.Sno=SC.Sno且SC.Cno=C.Cno且Cname=′data′等价于u[1]=v[1]∧v[2]=w[1]∧w[2]=′data′。因为本题的结果集为Sno、Sname和Grade,而u[1]对应的是S.Sno,u[2]对应的是S.Sname,v[3]对应的是SC.Grade,所以对属性列Sno、Sname和Grade的投影等价于t[1]=u[1]∧t[2]=u[2]∧t[3]=v[3]。因此,与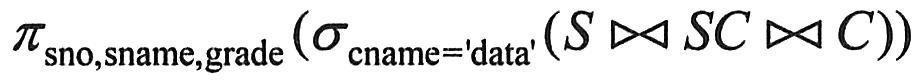 等价的元组演算表达式为{(?u)(?v)(?w)S(u)∧SC(v)∧C(w)∧u[1]=v[1]∧v[2]=w[1]∧w[2]=′data′∧t[1]=u[1]∧t[2]=u[2]∧t[3]=v[3]}。 等价的元组演算表达式为{(?u)(?v)(?w)S(u)∧SC(v)∧C(w)∧u[1]=v[1]∧v[2]=w[1]∧w[2]=′data′∧t[1]=u[1]∧t[2]=u[2]∧t[3]=v[3]}。
|
|
|
|
|
|
访问接口是指分布式环境中保证操作系统、通信协议、数据库等之间进行对话,互操作的软件系统。访问接口的作用是保证网络中各部件(软件和硬件)之间透明地连接,即隐藏网络部件的异构性,尤其保证不同网络,不同DBMS和某些访问语言的透明性,即下面3个透明性。
|
|
|
|
|
|
(2)服务器透明性:不管服务器上的DBMS是何种型号的数据库系统,一个好的访问接口都能通过标准的SQL语言与不同DBMS上的SQL语言连接起来。
|
|
|
|
(3)语言透明性:客户机可用任何开发语言进行发送请求和接收回答,被调用的功能应该像语言那样也是独立的。
|
|
|
|
应用系统访问数据库的接口方式有多种,最常用的有专用调用、ODBC和JDBC。
|
|
|
|
|
|
每个数据库引擎都带有自己的用于访问数据库的动态链接库,应用程序可利用它存取和操纵数据库中的数据。如果应用程序直接调用这些动态链接库,就说它执行的是专用调用,因为该调用对于特定的数据库产品来说是专用的。
|
|
|
|
专用调用接口的优点是执行效率高,由于是专用,编程实现较简单。但它的主要缺点是不具通用性,对于不同的数据库引擎,应用程序必须连接和调用不同的专用动态链接库,这对于网络数据库系统的应用是极不方便的。
|
|
|
|
|
|
ODBC(Open Database Connectivity,开放数据库互连)是Microsoft公司提出的,被当前业界广泛接受的应用程序编程接口(Application Programming Interface, API)标准,它以X/Open和ISO/IEC的调用级接口规范为基础,用于对数据库的访问。
|
|
|
|
ODBC实际上是一个数据库访问函数库,使应用程序可以直接操纵数据库中的数据。ODBC是基于SQL语言的,是一种在SQL和应用界面之间的标准接口,它解决了嵌入式SQL接口非规范核心,免除了应用软件随数据库的改变而改变的麻烦。ODBC的一个最显著的优点是,用ODBC生成的程序是与数据库和数据库引擎无关的,为数据库用户和开发人员屏蔽了异构环境的复杂性,提供了数据库访问的统一接口,为应用程序实现与平台的无关性和可移植性提供了基础。
|
|
|
|
ODBC主要由4个部分组成:应用程序、驱动程序管理器、驱动程序、数据源。
|
|
|
|
(1)应用程序:执行处理并调用ODBC API函数,以提交SQL语句并检索结果。
|
|
|
|
(2)驱动程序管理器:根据应用程序需要加载/卸载驱动程序,处理ODBC函数调用,或把它们传送到驱动程序。
|
|
|
|
(3)驱动程序:处理ODBC函数调用,提交SQL请求到一个指定的数据源,并把结果返回到应用程序。如果有必要,驱动程序修改一个应用程序请求,以使请求与相关的DBMS支持的语法一致。
|
|
|
|
(4)数据源:包括用户要访问的数据及其相关的操作系统、DBMS及用于访问DBMS的网络平台。
|
|
|
|
ODBC的API一致性级别分为3级,分别是核心级、扩展1级和扩展2级。
|
|
|
|
(1)核心级:最基本的功能,包括分配、释放环境句柄,数据库连接,执行SQL语句等。核心级函数能满足最基本的应用程序的要求。
|
|
|
|
(2)扩展1级:在核心级的基础上增加了一些函数,通过它们可以在应用程序中动态地了解表的模式、可用的概念模型类型及它们的名称等。
|
|
|
|
(3)扩展2级:在扩展1级的基础上又增加了一些函数。通过它们可以了解到关于主关键字和外来关键字的信息、表和列的权限信息、数据库中的存储过程信息等,并且还有更强的游标和并发控制功能。
|
|
|
|
|
|
JDBC(Java Database Connectivity, Java数据库连接)是一种可用于执行SQL语句的Java API。它由一些Java语言编写的类和接口组成。JDBC给数据库应用开发人员、数据库前台工具开发人员提供了一种标准的应用程序设计接口,使开发人员可以使用纯Java语言编写完整的数据库应用程序。而且因为JDBC基于X/Open的SQL调用级接口(CLI,这是ODBC的基础),JDBC可以保证JDBC API在其他通用SQL级API(包括ODBC)之上实现。这意味着所有支持ODBC的数据库不加任何修改就能够与JDBC协同合作。
|
|
|
|
通过使用JDBC,开发人员可以很方便地将SQL语句传送给几乎任何一种数据库。JDBC扩展了Java的能力,如使用Java和JDBCAPI就可以公布一个Web页,页面中带有能访问远端数据库的Applet。
|
|
|
|
|
|
到目前为止,微软的ODBC可能是用得最广泛的访问关系数据库的API。它几乎能够连接任何一种平台、任何一种数据库。那么,为什么不直接从Java中使用ODBC呢?
|
|
|
|
(1)ODBC并不适合在Java中直接使用。ODBC是一个C语言实现的API,从Java程序调用本地的C程序会带来一系列类似安全性、完整性、健壮性的问题。
|
|
|
|
(2)完全精确地实现从C代码ODBC到Java API写的ODBC的翻译也并不令人满意。比如,Java没有指针,而ODBC中大量地使用了指针。因此,对Java程序员来说,把JDBC设想成将ODBC转换成面向对象的API是很自然的。
|
|
|
|
(3)ODBC并不容易学习,它将简单特性和复杂特性混杂在一起,甚至对非常简单的查询都有复杂的选项。而JDBC刚好相反,它保持了简单事物的简单性,但又允许复杂的特性。
|
|
|
|
(4)JDBC这样的Java API对于纯Java方案来说是必需的。当使用ODBC时,人们必须在每一台客户机上安装ODBC驱动器和驱动管理器。如果JDBC驱动器是完全用Java语言实现,那么JDBC的代码就可以自动的下载和安装,并保证其安全性。而且,这将适应任何Java平台。
|
|
|
|
总之,JDBC API是能体现SQL最基本抽象概念的,最直接的Java接口。它构建在ODBC的基础上。JDBC保持了ODBC的基本设计特征。实际上,这两种接口都是基于X/Open SQL的调用级接口。它们的最大区别是,JDBC以Java的风格和优点为基础,并强化了它。
|
|
|