|
|
知识路径: > 多媒体信息处理及编辑技术 > 多媒体文字信息的处理与编辑 > 文字信息的处理与编辑概述 > 文字信息的处理与编辑概述 >
|
|
考试要求:掌握
相关知识点:5个
|
|
|
|
|
|
|
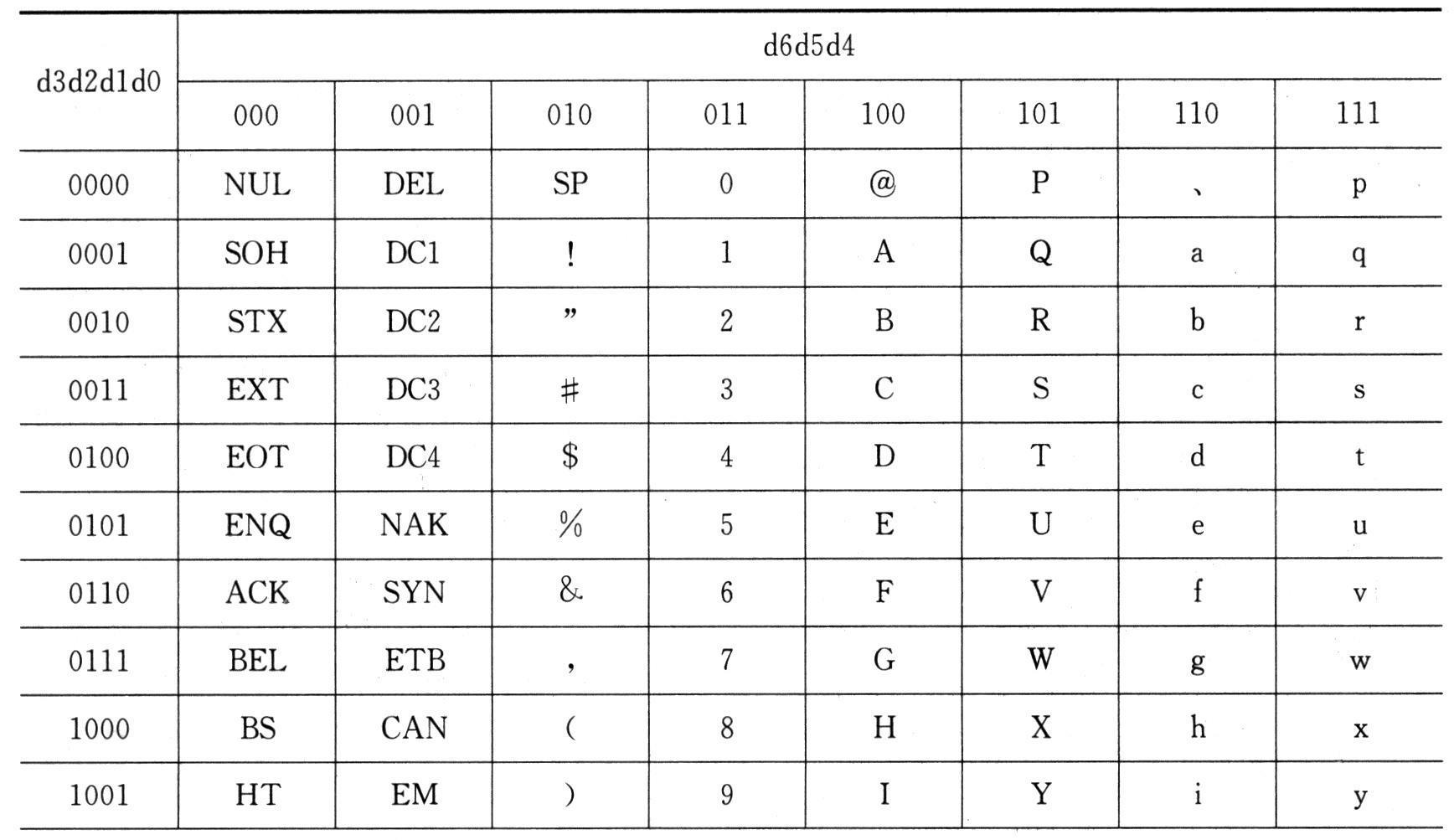
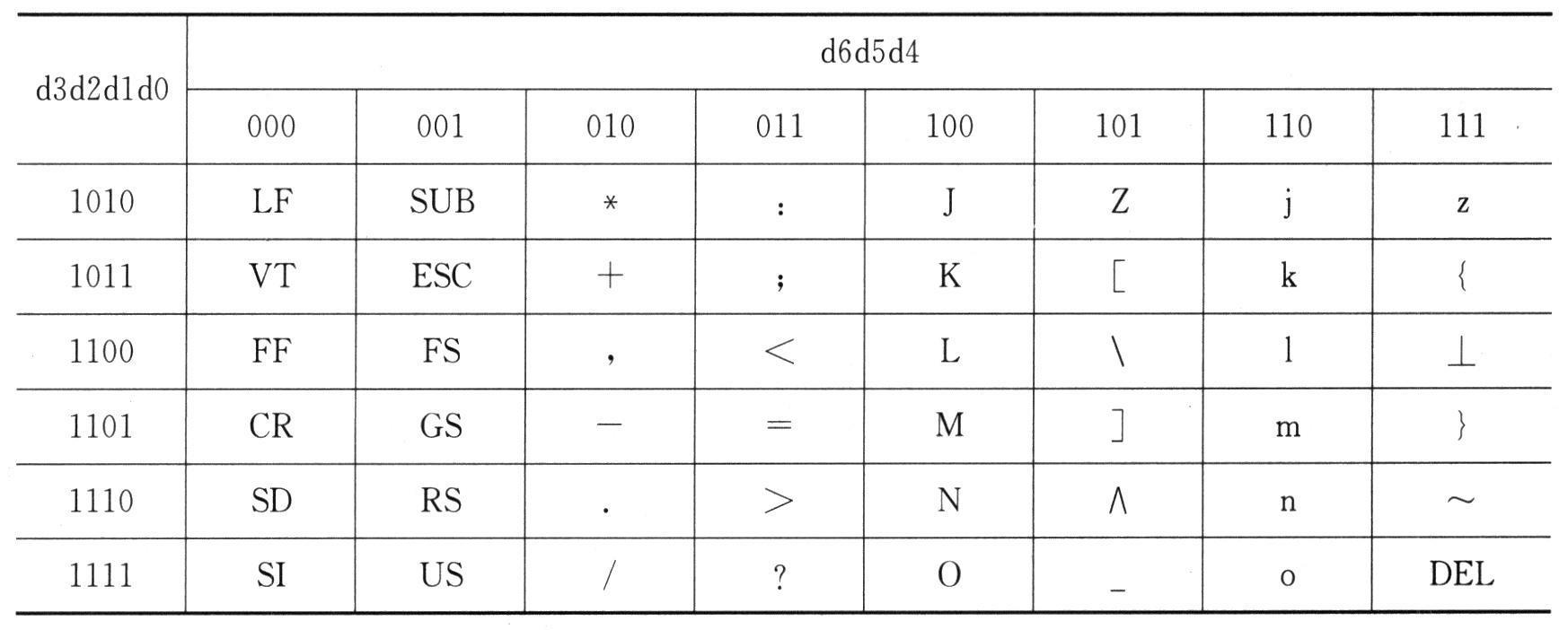
英文字符编码方案的国际标准为美国国家信息交换标准字符码(American Standard Code for Information Interchange, ASCII)。ASCII码利用7位二进制数表示,共有128个元素。字节(8位)是计算机中的常用单位,ASCII字符将字节中多余的最高位取0。下表所示为7位ASCII字符编码表。
|
|
|
|
|
|
|
|
|
|
ASCII规范标准发表于1967年,最后一次更新于1986年,至今共定义了128个字符,其中包括33个非打印字符,其主要用途是操控已经处理过的文字,另外还有95个可显示字符。
|
|
|
|
|
|
英语用128个符号编码就足够了,但若是用来表示汉字,128个符号是远远不够的,所以1981年5月中国国家标准总局发布了GB 2312编码,全称为信息交换用汉字编码字符集。
|
|
|
|
GB 2312编码共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。GB 2312编码基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖了中国99.75%的使用频率。
|
|
|
|
GB 2312编码中对所收录的汉字进行了“分区”处理,每区含有94个汉字/符号,这种表示方式也称区位码。
|
|
|
|
|
|
|
|
|
|
例如,“啊”字是GB 2312编码中的第一个汉字,它的区位码就是1601D,即表示“啊”字是位于第16区的第01个编码。
|
|
|
|
|
|
虽然汉字可以利用GB 2312编码表示,但对于世界上很多国家的文字和字符并没有包含在内,所以Unicode编码(又称万国码、国际码、统一码、单一码)出现了。Unicode编码对世界上大部分的文字系统都进行了整理、编码,是计算机科学领域中的一项业界标准。
|
|
|
|
Unicode编码至今仍在不断增修,每个新版本都加入了更多新的字符,目前的最新版本已经收录了超过10万个字符。Unicode编码涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含字符特性,如大小写字母。
|
|
|
|
Unicode编码被广泛应用于计算机软件的国际化与本地化过程。有很多新科技,如可扩展标记语言、Java编程语言以及现代的操作系统都采用了Umicode编码。
|
|
|
|
需要注意的是,Unicode编码只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字“严”的Unicode编码是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,表示这个符号至少需要2字节,表示其他更大的符号可能需要3字节或者4字节,甚至更多。
|
|
|
|
Unicode编码的实现方式不同于编码方式。一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式便会有所不同。Unicode编码的实现方式称为Unicode转换格式(Unicode Transformation Format, UTF)。目前最常用的实现编码为UTF-8,除此之外还有UTF-16、UTF-32。
|
|
|