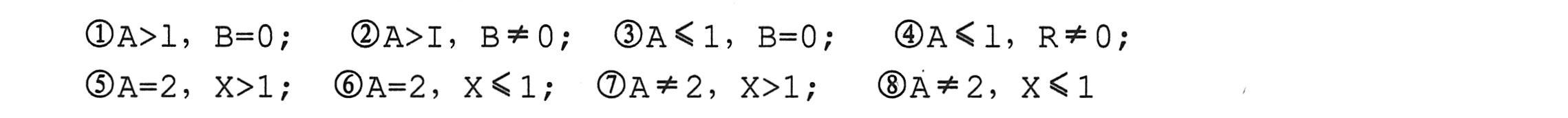|
|
知识路径: > 信息系统开发和运行管理知识 > 系统实施基础知识 > 测试设计和管理 >
|
被考次数:4次
被考频率:中频率
总体答错率:33%
知识难度系数: 
|
由 软考在线 用户真实做题大数据统计生成
|
|
考试要求:了解
相关知识点:19个
|
|
|
|
|
|
|
白盒测试是对软件的过程性细节做详细检查。通过对程序内部结构和逻辑的分析来设计测试用例。适合于白盒测试的设计技术主要有:逻辑覆盖法、基本路径测试等。下面将介绍逻辑覆盖法。
|
|
|
|
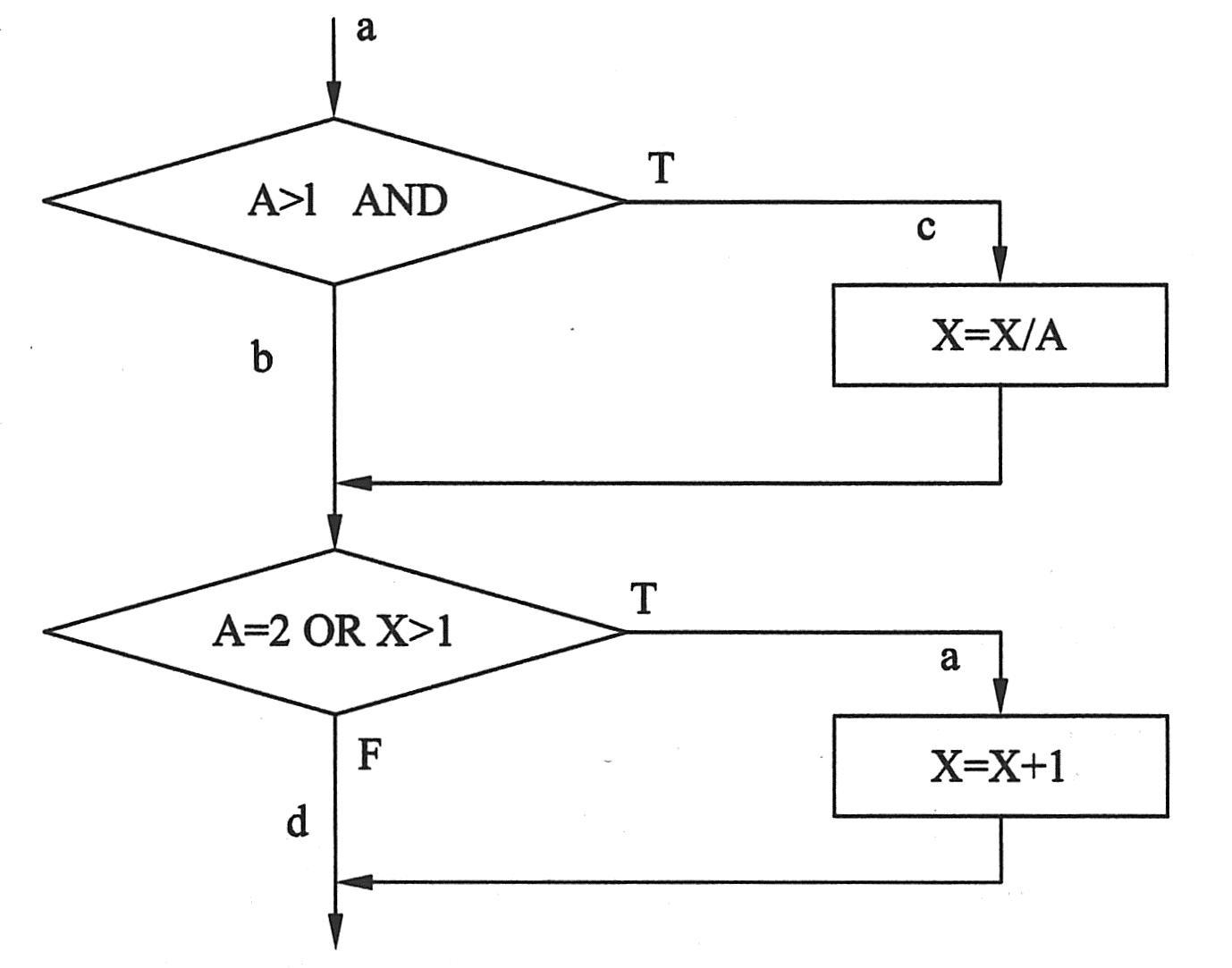
逻辑覆盖(Logic Coverage)是以程序内部的逻辑结构为基础的测试技术。它考虑的是测试数据执行(覆盖)程序的逻辑程度。由于穷举测试是不现实的,因此,只希望覆盖的程度更高些。根据覆盖情况的不同,逻辑覆盖可分为:语句覆盖、判定覆盖、条件覆盖、判定条件覆盖、多重覆盖、路径覆盖。在讨论这几种覆盖时,均以下图所示的程序段为例。这是一个非常简单的程序,共有两个判断、4条不同路径。为了方便起见,分别对第一个判断取假分支,对第一个判断取真分支,对第二个判断取假分支,对第二个判断取真分支并分别命名为b、c、d和e。4条路径表示为abd、acd、abe和ace。其Pascal程序为:
|
|
|
|
|
|
|
|
|
|
|
|
语句覆盖(Statement Coverage)就是设计若干个检测用例,使得程序中的每条语句至少被执行一次。在所举的示例中,只要选择能通过路径ace的测试用例即可。如:
|
|
|
|
|
|
语句覆盖对程序的逻辑覆盖程度很低,如果把第一个判断语句中的AND错写成OR,或把第二个判断语句中的OR错写成AND,用上面的测试用例是不能发现问题的。这说明语句覆盖有可能发现不了判断条件中算法出现的错误。
|
|
|
|
|
|
判定覆盖(Decision Coverage)也被称为分支覆盖,就是设计若干个检测用例,使得程序中的每个判断的取真分支和取假分支至少被执行一次。对上述被测程序来说,需要设计测试用例覆盖路径acd和abe(或abd和ace)。可以选择如下的输入数据:
|
|
|
|
|
|
|
|
|
|
判断覆盖比语句覆盖的程度稍高,因为如果通过了每个分支的测试,则各语句也都被执行了。但仍有不足,如上述的测试用例不能发现把第二个判断语句中的X>1错写成X<1的错误。所以,判断覆盖还不能保证一定能查出判断条件中的错误。因此,需要更强的逻辑覆盖来检测内部条件的错误。
|
|
|
|
|
|
条件覆盖(Condition Coverage)就是设计若干个测试用例,使得被测程序中每个判断的每个条件的所有可能情况都至少被执行一次。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
条件覆盖通常比判断覆盖强,因为条件覆盖可以使判断语句中的每个条件都能取两个不同的结果。但有可能出现虽然每个条件都取了不同的结果,但判断表达式却始终是一个值的情况,请看下面两组输入数据:
|
|
|
|
|
|
它们满足条件覆盖,但不满足语句覆盖和判断覆盖的标准(未经历路径c,那么就发现不了X=X/A错写成X=X/B的错误)。因此,需要对条件及判断产生的分支兼顾,这就是下面要介绍的判断/条件覆盖。
|
|
|
|
|
|
判断/条件覆盖(Decision/Condition Coverage)是既要满足判断覆盖的要求,又要满足条件覆盖的要求。也就是设计若干个测试用例,使得程序中的每个判断的取真分支和取假分支至少执行一次,而且每个条件的所有可能情况都至少被执行一次。对于上图而言,下面两组输入数据可以满足判断/条件覆盖的要求:
|
|
|
|
|
|
但这两组数据也是条件覆盖中所举的示例。因此,有时判断/条件覆盖并不比条件覆盖更强,逻辑表达式的错误也不一定能被检查出来。
|
|
|
|
|
|
多重覆盖(Multi-job Coverage)就是设计多个测试用例,使得各判断表达式中条件的各种组合至少被执行一次。就上图所示的例子而言,要符合多重覆盖的标准,所设计的测试用例必须满足下面的8种条件组合:
|
|
|
|
|
|
|
|
|
|
很显然,多重覆盖包含了条件覆盖、判断覆盖和判断/条件覆盖,是前面几种覆盖标准中最强的。但就上面的4组输入数据,也没有将程序中的每条路径都覆盖了,如:没有通过acd这条路径,所以测试仍不完全。
|
|
|
|
|
|
路径覆盖就是设计足够多的测试示例,使被测程序中的所有可能路径至少被执行一次。对上面的例子束说,可以选择这样的4组测试数据来覆盖程序中的所有路径:
|
|
|
|
|
|
路径覆盖保证了程序中的所有路径都至少被执行一次,是一种比较全的逻辑覆盖标准。但它没有检查判断表达式中条件的各种组合情况,通常把路径覆盖和多重覆盖结合起来就可以得到查错能力很强的测试用例。如上面的例子,把多重覆盖的4组输入数据和路径覆盖中的第3组数据组合成起来,形成5组输入数据,就可以得到既满足路径覆盖的标准,又满足多重覆盖的标准。
|
|
|
|
|
|
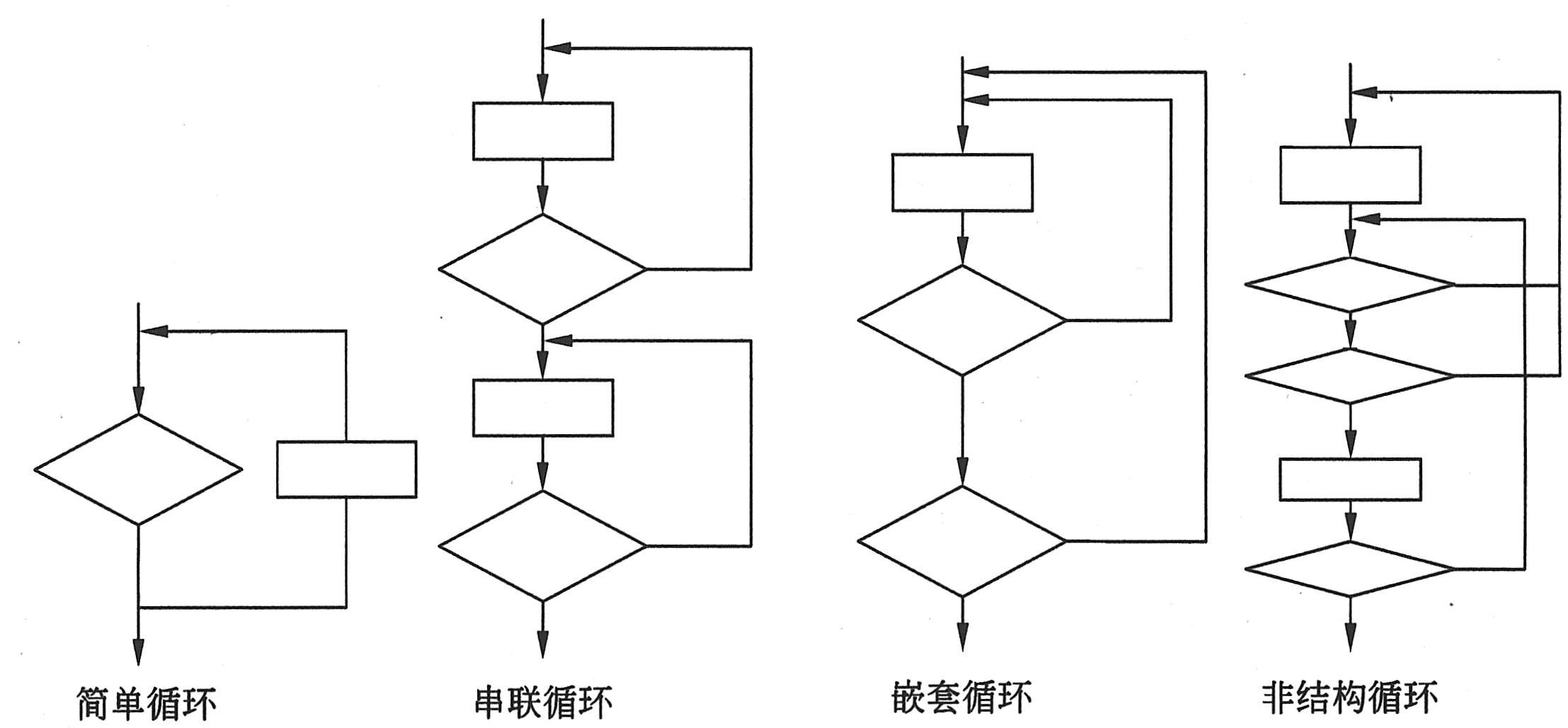
上面介绍的只是语句、分支、条件以及它们的组合情况,而循环也是大多数算法的基础:对循环的测试主要检查循环构造的有效性。循环分为简单循环(Simple Loops)、串联循环(Concatenated Loops)、嵌套循环(Nested Loops)和非结构循环(Unstructured Loops)4种类型,如下图所示。
|
|
|
|
|
|
|
|
对于循环次数为n的简单循环。可以采用下列措施进行测试。
|
|
|
|
|
|
|
|
|
|
对于嵌套循环,如果采用简单循环的测试方法,则测试次数将会成几何级数增长。可以采用以下方法进行测试。
|
|
|
|
.从最内层循环开始测试,对所有外层循环都取最小值,内层循环按简单循环的测试方法进行。
|
|
|
|
.由里向外,一层层进行测试,凡是外层的循环都取最小值,该层循环嵌套的那些循环取一些典型的值。
|
|
|
|
|
|
对于串联循环的测试可分成两种情况:如果两个循环是独立的,则采用简单循环的测试方法;反之,如果两个循环不是独立的,则需要用嵌套循环的测试方法来测试,对于非结构循环,一般先把程序结构化之后再进行测试。
|
|
|
|
|
|
黑盒测试是在测试时把软件看成一个黑盒子,完全不考虑程序的内部结构及其逻辑,重点考察程序功能是否与需求说明书的要求一致。适合于黑盒测试的设计技术主要有:等价类划分、边界值分析、错误推测法、因果图、功能图等。下面重点介绍等价类划分、边界值分析这两种测试技术。
|
|
|
|
|
|
等价类划分是比较典型的黑盒测试技术。如前所述,输入量的穷举测试是不现实的,那么如何才能既可大大减少测试的次数、又不丢失发现错误的机会是问题的关键所在。等价类划分技术的主要思想就是程序的输入数据都可以按照程序说明划分为若下个等价类,每一个等价类对于输入条件可划分为有效的输入和无效的输入,然后再对每一个有效的等价类和无效的等价类设计测试用例。如果用某个等价类的一组测试数据进行测试时没有发现错误,则说明在同一等价类中的其他输入数据也一样查不出问题;反之,如用某个等价类的测试数据进行测试,并检查出错误,则说明用该等价类的其他输入数据进行测试也一样会检测出错误。所以在测试时,只需从每个等价类中取一组输入数据进行测试即可。
|
|
|
|
使用等价类划分技术设计测试方案时,首先需要根据程序的功能说明划分出输入数据的有效等价类和无效等价类,然后为每个等价类设计测试用倒。在确定输入数据的等价类时常常还需要分析输出数据的等价类,以便根据输出数据的等价类来推导出对应的测试用例。
|
|
|
|
|
|
.如果规定了输入数据的范围,则可划分为一个有效等价类和两个无效等价类。如学生年龄输入的范围为0~100,则有效等价类为“0≤年龄≤100”,两个无效等价类为“年龄>100”或“年龄<0”。
|
|
|
|
.如果规定了输入数据的个数,则可划分为一个有效等价类和两个无效等价类。如一个老师在指导毕业设计时必须指导1~5个学生,则有效等价类为“学生人数是1~5个”,两个无效等价类为“一个都不指导”或“指导人数超过5个”。
|
|
|
|
.如果规定了输入数据为一组可能的值,而且程序对每个输入值分别进行处理,这时需要为每个输入数据确定一个有效等价类,把除此之外的所有值确定为一个无效等价类。如在教师涨工资的方案中根据职称(教授、副教授、讲师和助教)的不同其增长幅度也不相同,这时需要对每个职称确定一个有效的等价类(共4个),还有一个无效的等价类,它包含不满足以上身份的所有输入数据。但是,如果在程序对这些可能值的处理都一样时,只需要确定一个有效等价类(所有合理值)和一个无效等价类(除合理值之外的其他任何值)。
|
|
|
|
.如果规定了输入数据必须遵守的规则,则可以划分出一个有效等价类(遵守规则的输入数据)和若干个无效等价类(从不同角度设计得到违反规则的情况)。
|
|
|
|
.如果在划分的某等价类中各值在程序中的处理方式不同,则需要将该等价类进一步划分成更小的等价类。
|
|
|
|
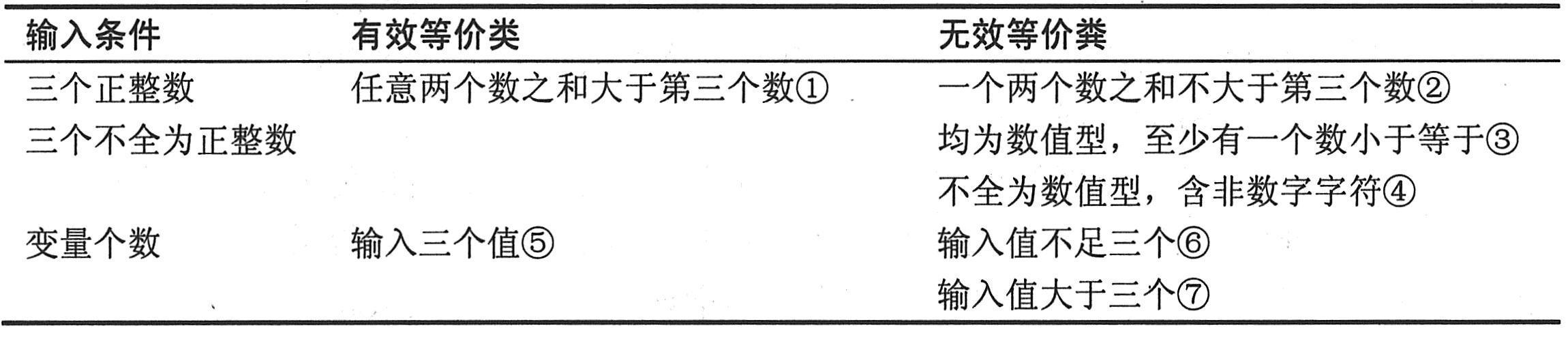
以上列出的原则只是实际情况中很小的一部分。为了正确划分等价类,需要正确分析被测程序的功能。划分等价类的方法是根据每个输入条件(通常是规范说明中的一句话或一个短语)列出两个或更多的等价类,将其填入下表中,建立等价类表。
|
|
|
|
|
|
|
|
|
|
.设计新的测试用例,使其尽可能多地覆盖未被覆盖的有效等价类,重复这一步骤直至所有有效等价类都被覆盖。
|
|
|
|
.设计新的测试用例,使其覆盖一个而且仅此一个未被覆盖的无效等价类,重复这一步骤直至所有无效等价类都被覆盖。
|
|
|
|
之所以这么做,是因为程序在遇到错误之后就不会再检查是否还有其他错误。所以一个测试用例只能覆盖一个无效等价类。
|
|
|
|
例如,判断是否为三角形的条件是其中任意两个数之和应大于第三个数。假入输入的三个数表示三角形的三个边,可以建立如下表所示的等价类表。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
边界值分析也是黑盒测试技术,是等价类划分的一种补充。通常,程序在处理边界时容易发生错误。而等价类划分技术是在等价类中随便选择一组数据作为代表,并没有考虑边界情况。边界值分析是指将每个等价类的各边界作为测试目标,使得测试数据等于、刚刚小于、或刚大于等价类的边界值。
|
|
|
|
边界值分析技术在设计测试用例的原则与等价类划分技术的许多方面类似。需要注意的是,边界值分析技术不仅应注意输入条件的边值,还应根据输出条件的边值设计测试用例(下面的④、⑤原则就是针对输出条件的边值问题)。选择测试用例有以下原则:
|
|
|
|
①如果规定了输入数据的范围,则应取等于该范围的边界值,以及刚刚超过这个范围的边界值的测试数据。如某数输入的范围是从0~1.0,则可选“-0.01”、“0”、“1.0”和“1.01”作为测试数据。
|
|
|
|
②如果规定了输入数据的个数,则应取最大个数、最小个数、比最大个数多1和比最小个数少1的数作为测试数据。如一个老师在指导毕业设计时必须指导1~5个学生,则可选指导人数分别为0个、1个、5个和6个作为测试数据。
|
|
|
|
③如果程序中使用了内部数据结构,则需要选择该数据结构的边界值作为测试用例。如在程序中使用了一个数组,其下标值的范围为0~20,这就需要选择达到该数组的下标边界值(即0与20)作为测试数据。
|
|
|
|
④根据规格说明的每个输出条件可以使用第①条原则。如某个被测程序的输出值在0~1之间,则需要设计测试用例使得其输出值分别为0和1。
|
|
|
|
⑤根据规格说明的每个输出条件也可以使用第②条原则。如某个被测程序在显示时要求显示的记录数最多为5条,则需要设计测试用例使得其输出的记录数分别为0条、1条和5条。
|
|
|
|
例如,前面的三角形判断示例中,如果把a+b>c错误写成a+b≥c,等价类划分方法通常无法发现这个错误。使用边界值分析技术,则会选择这样的测试用例:
|
|
|
|
|
|
|
|
从这里可以看出,边界值分折与等价类划分技术最大的区别是边界值分析技术在设计测试用例时,将重点检测等价类边界和边界附近的情况,而等价类划分技术只是在每个等价类中随便选择一组测试数据。
|
|
|
|
在设计测试方案中,通常会把逻辑覆盖、等价类划分和边界值分析等方法结合起来,这样既可以检测设计的内部要求,又可以检测设计的接口要求。
|
|
|
|
在对非常庞大、复杂的信息系统进行测试时,如果严格按照上面所介绍的测试技术进行,所花费的人力、时间无疑是非常大的。考虑到测试中存在着群集现象以及软件的可重用性,在实际的测试过程中,可以采用抽样测试或重点测试。也就是有针对性地选择具有代表性的测试用例进行测试,或把测试的重点放在容易出错的地方及重要模块上。这样可以以较少资源发现错误,也就提高了测试效率。
|
|
|