|
|
知识路径: > 计算机系统基础知识 > 数据的表示 > 字符、汉字、声音、图像的编码方式 >
|
被考次数:2次
被考频率:低频率
总体答错率:38%
知识难度系数: 
|
由 软考在线 用户真实做题大数据统计生成
|
|
考试要求:掌握
相关知识点:18个
|
|
|
|
|
各类数据的表示都有相应的基本字符集,任何字符在计算机中都必须转换成二进制表示形式,称为字符编码。
|
|
|
|
|
|
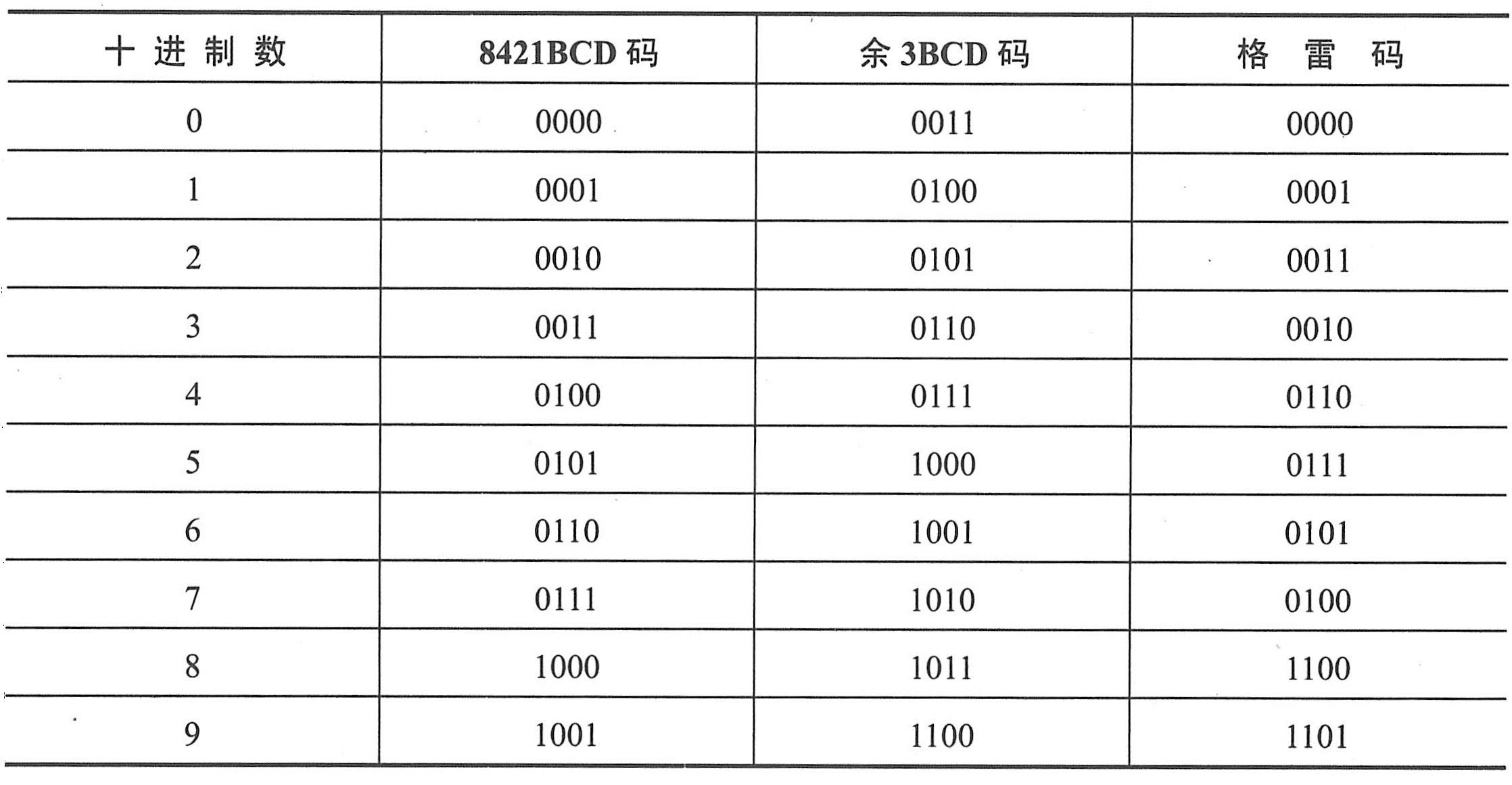
用4位二进制代码表示一位十进制数,称为二-十进制编码,简称BCD编码。因为24=16,而十进制数只有0~9这10个不同的数符,故有多种BCD编码。根据4位代码中每一位是否有确定的权来划分,可分为有权码和无权码两类。
|
|
|
|
应用最多的有权码是8421码,即4个二进制位的权从高到低分别为8、4、2和1。无权码中常用余3码和格雷码(有多种编码形式)。余3码是在8421码的基础上,把每个数的代码加上0011后构成的。格雷码的编码规则是相邻的两个代码之间只有1位不同。
|
|
|
|
常用的8421BCD码、余3码、格雷码与十进制数的对应关系如下表所示。
|
|
|
|
|
|
8421BCD码、余3码、格雷码与十进制数的对应关系
|
|
|
|
|
|
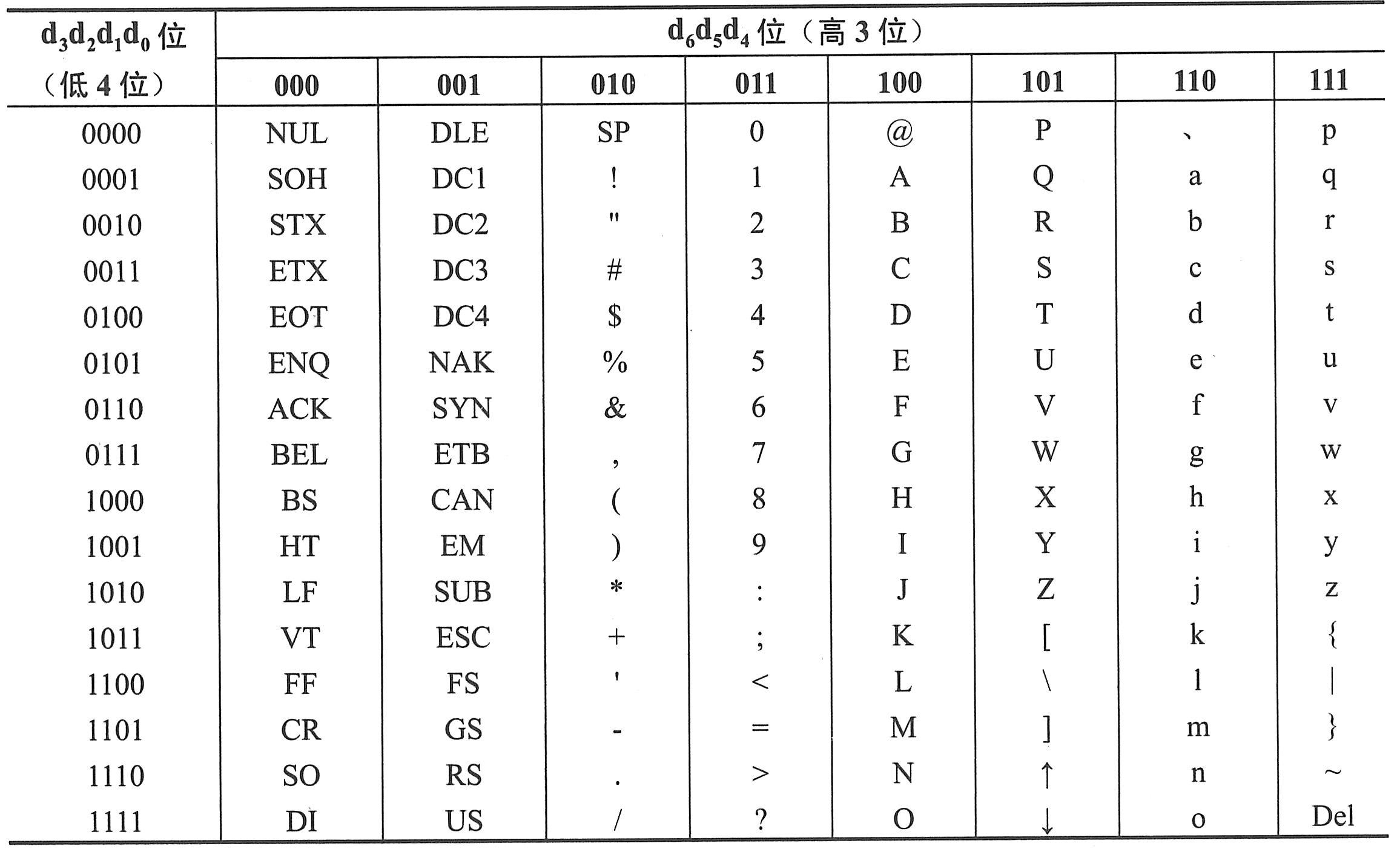
美国标准信息交换代码(American Standard Code for Information Interchange,ASCII)被国际标准化组织ISO采纳,成为一种国际通用的信息交换用标准代码。基本的ASCII码采用7个二进制位,即d6d5d4d3d2d1d0对字符进行编码:低4位组d3d2d1d0用作行编码,高3位组d6d5d4用作列编码。基本的ASCII字符代码表如下表所示。
|
|
|
|
|
|
|
|
根据ASCII码的构成格式,可以很方便地从对应的代码表中查出每一个字符的编码。例如,字符0的ASCII码值为0110000(25+24=48),字符a的ASCII码值为1100001(26+25+20=97)。
|
|
|
|
|
|
计算机中处理汉字时,必须先将汉字代码化,即对汉字进行编码。汉字处理包括汉字的编码输入、汉字的存储和汉字的输出等环节。
|
|
|
|
西文是拼音文字,基本符号比较少,比较容易编码,在计算机系统中输入、内部处理、存储和输出都可以使用同一代码。汉字种类繁多,编码比拼音文字困难,而且在一个汉字处理系统中,输入、内部处理、存储和输出对汉字代码的要求不尽相同,所以采用的编码也不同。汉字信息处理系统在处理汉字和词语时,关键的问题是要进行一系列的汉字代码转换。
|
|
|
|
|
|
中文字数繁多,字形复杂,字音多变,常用汉字就有7000个左右。为了能直接使用西文标准键盘输入汉字,必须为汉字设计相应的编码方法,汉字的输入码主要分为三类:数字编码、拼音码和字形码。
|
|
|
|
(1)数字编码。数字编码就是用数字串代表一个汉字的输入,常用的是国标区位码。国标区位码将国家标准局公布的6763个两级汉字分成94个区,每个区94位,区码和位码各两位十进制数字。例如,“中”字位于第54区48位,区位码为5448。
|
|
|
|
汉字在区位码表的排列是有规律的。在94个分区中,1~15区用来表示字母、数字和符号,16~87区为一级和二级汉字。一级汉字以汉语拼音为序排列,二级汉字以偏旁部首进行排列。使用区位码方法输入汉字时,必须先在表中查找汉字对应的代码,才能输入。数字编码输入的优点是无重码,而且输入码和内部编码的转换比较方便,但是数字码有难以记忆的缺点。
|
|
|
|
(2)拼音码。拼音码是以汉语读音为基础的输入方法。由于汉字同音字太多,输入重码率很高,因此,按拼音输入后还必须进行同音字选择,会影响输入速度。
|
|
|
|
(3)字形编码。字形编码是以汉字的形状确定的编码。汉字总数虽多,但都是由一笔一划组成,全部汉字的部件和笔划是有限的。因此,把汉字的笔划部件用字母或数字进行编码,按笔划书写的顺序依次输入,就能表示一个汉字,五笔字型、表形码等便是这种编码法。
|
|
|
|
|
|
汉字内部码(简称汉字内码)是汉字在设备和信息处理系统内部存储、处理、传输汉字用的代码。汉字数量多,用一个字节无法区分,采用国家标准局GB 2312—1980中规定的汉字国标码,两个字节存放一个汉字的内码,每个字节的最高位置1,作为汉字机内码。由于两个字节各用7位,因此可表示16 384个可区别的机内码。以汉字“大”为例,国标码为3473H,两个字节的高位置1,得到的机内码为B4F3H。
|
|
|
|
GB 18030—2005《信息技术中文编码字符集》是我国最新的内码字符集,与GB 2312—1980完全兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
|
|
|
|
|
|
汉字字形码是表示汉字字形的字模数据,通常用点阵、矢量函数等方式表示,用点阵表示字形时,汉字字形码指的就是这个汉字字形点阵的代码。字形码也称字模码,是用点阵表示的汉字字形码,它是汉字的输出方式。根据输出汉字的要求不同,点阵的多少也不同。简易型汉字为16×16点阵,高精度型汉字为24×24点阵、32×32点阵、48×48点阵等。
|
|
|
|
字模点阵的信息量是很大的,所占存储空间也很大,以16×16点阵为例,每个汉字就需要32字节用于机内存储。字库中存储了每个汉字的点阵代码,当显示输出时才检索字库,输出字模点阵得到字形。
|
|
|
|
汉字的矢量表示法是将汉字看作由笔画组成的图形,提取每个笔画的坐标值,这些坐标值就可以决定每一笔画的位置,将每一个汉字的所有坐标值信息组合起来就是该汉字字形的矢量信息。显然,汉字的字形不同,其矢量信息也就不同,每个汉字都有自己的矢量信息。由于汉字的笔画不同,则矢量信息就不同。所以,每个汉字矢量信息所占的内存大小不一样。同样,将每一个汉字的矢量信息集中在一起就构成了汉字库。当需要汉字输出时,利用汉字字形检索程序根据汉字内码从字模库中找到相应的字形码。
|
|
|
|
|
|
为了统一地表示世界各国的文字,国际标准化组织1993年公布了“通用多八位编码字符集”国际标准ISO/IEC 10646,简称UCS(Universal Coded Character Set)。另一个是Unicode(称为统一码、万国码或单一码)软件制造商协会(unicode.org)开发的可以容纳世界上所有文字和符号的字符编码标准,包括字符集、编码方案等。Unicode 2.0开始采用与ISO 10646-1相同的字库和字码。目前这两个项目独立地公布各自的标准。
|
|
|
|
UCS规定了两种编码格式:UCS-2和UCS-4。UCS-2用两个字节编码,UCS-4用4个字节(实际上只用了31位,最高位必须为0)编码。
|
|
|
|
Unicode可以通过不同的编码实现,Unicode标准定义了用于传输和保存的UTF-8、UTF-16和UTF-32等,其中,UTF表示UCS Transformation Format。在网络上广泛使用的UTF-8以8位(一个字节)为单元对UCS进行编码。UCS-2与UTF-8的编码对应关系如下表所示。
|
|
|
|
|
|
|
|
例如,“汉”字的UCS编码是6C49(0110 11000100 1001),位于0800-FFFF之间,所以采用3字节模板,其UTF-8编码为11100110 10110001 10001001,也就是E6B189。
|
|
|
|
我国相应的国家标准为GB 13000,等同于国际标准的《通用多八位编码字符集(UCS)》ISO10646.1。
|
|
|