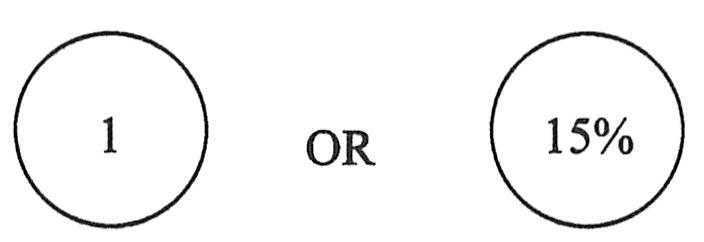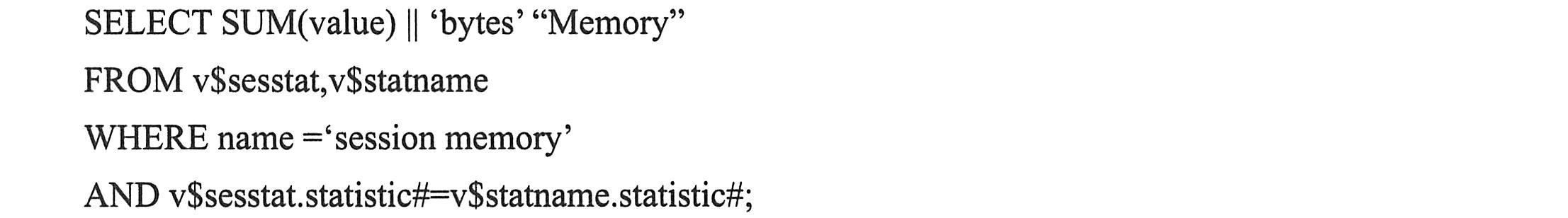|
|
知识路径: > 测试技术的分类 > 应用负载压力测试 >
|
被考次数:2次
被考频率:低频率
总体答错率:28%
知识难度系数: 
|
由 软考在线 用户真实做题大数据统计生成
|
|
考试要求:掌握
相关知识点:63个
|
|
|
|
|
|
|
|
|
测试计划→测试需求分析→测试案例制定→测试环境、工具、数据准备→测试脚本录制、编写与调试→场景制定→测试执行→获取测试结果→结果评估与测试报告。
|
|
|
|
|
|
|
|
制定一个全面的测试计划是负载测试成功的关键。定义明确的测试计划将确保制定的方案能完成负载测试目标。这部分内容描述负载测试计划过程,包括分析应用程序、定义测试目标、计划方案实施、检查测试目标。在任何类型的系统测试中,制定完善的测试计划是成功完成测试的基础。负载压力测试计划有助于:
|
|
|
|
①构建能够精确地模拟工作环境的测试方案。负载测试指在典型的工作条件下测试应用程序,并检测系统的性能、可靠性和容量等。
|
|
|
|
②了解测试需要的资源。应用程序测试需要硬件、软件和人力资源。开始测试之前,应了解哪些资源可用并确定如何有效地使用这些资源。
|
|
|
|
③以可度量的指标定义测试成功条件。明确的测试目标和标准有助于确保测试成功。仅定义模糊的目标(如检测重负载情况下的服务器响应时间)是不够的。明确的成功条件应类似于“50个客户能够同时查看他们的账户余额,并且服务器响应时间不超过1分钟”。
|
|
|
|
|
|
|
|
负载测试计划的第一步是分析应用程序。应该对硬件和软件组件、系统配置以及典型的使用模型有一个透彻的了解。应用程序分析可以确保使用的测试环境能够在测试中精确地反映应用程序的环境和配置。
|
|
|
|
|
|
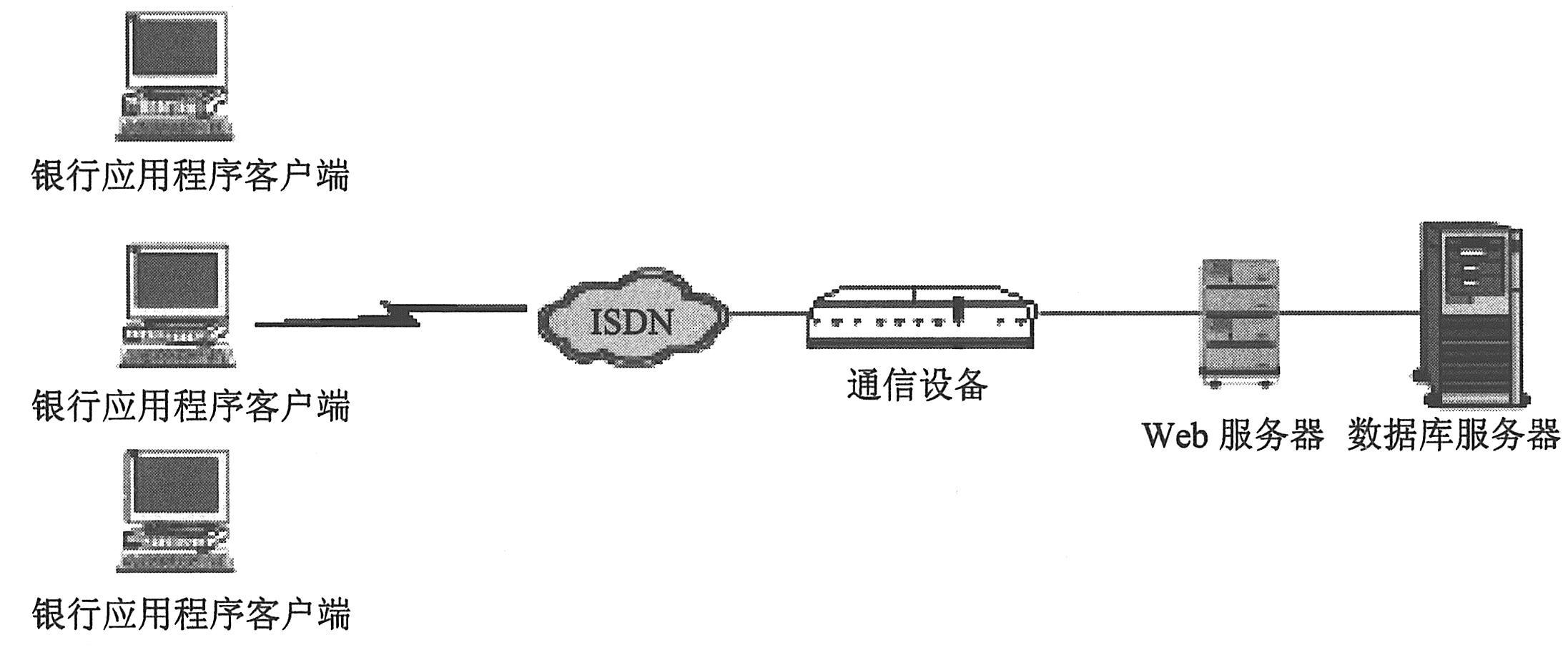
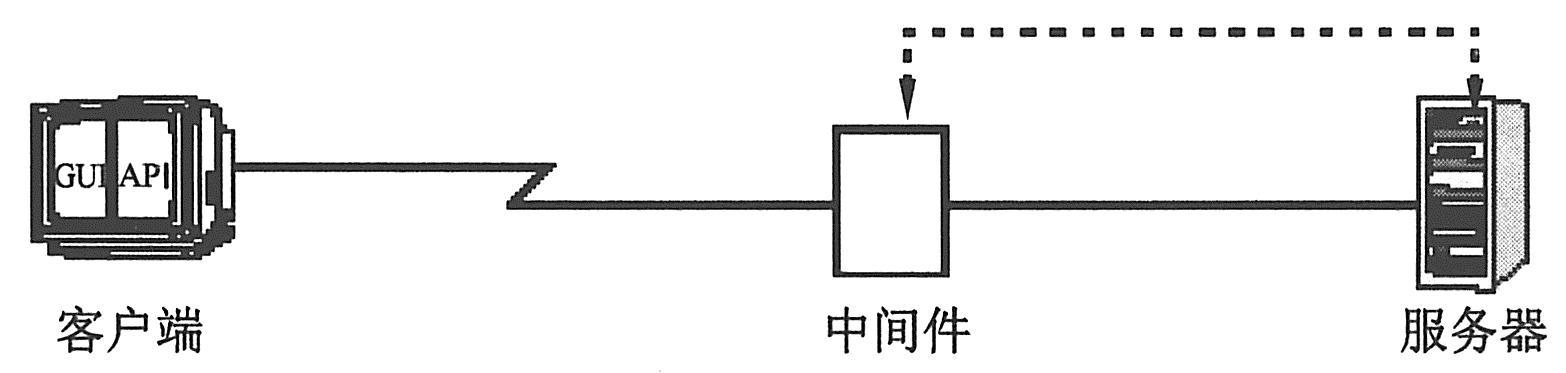
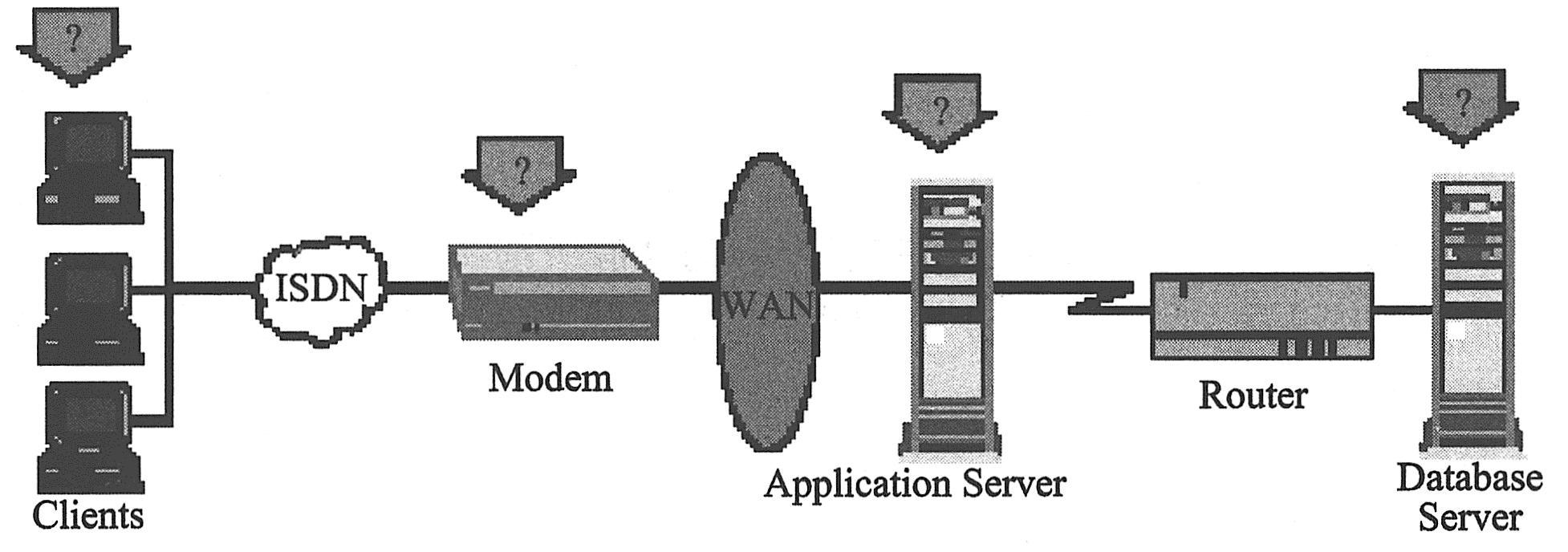
绘制一份应用程序结构示意图。如果可能,从现有文档中提取一份示意图。如果要测试的应用程序是一个较大的网络系统的一部分,应该确定要测试的系统组件。确保该示意图包括了所有的系统组件,例如客户机、网络、中间件和服务器等。
|
|
|
|
如下图所示说明了一个由许多Web用户访问的联机银行系统。各Web用户连接到同一数据库以转移现金和支票余额。客户使用不同的浏览器,通过Web方式连接到数据库服务器。
|
|
|
|
|
|
|
|
|
|
增加更多详细信息以完善示意图。描述各系统组件的配置。应当掌握以下信息:
|
|
|
|
|
|
. 应用程序客户端计算机的配置情况(硬件、内存、操作系统、软件、开发工具等);
|
|
|
|
. 使用的数据库和Web服务器的类型(硬件、数据库类型、操作系统、文件服务器等);
|
|
|
|
|
|
. 前端客户端与后端服务器之间的中间件配置和应用程序服务器;
|
|
|
|
. 可能影响响应时间的其他网络组件(调制解调器等);
|
|
|
|
. 通信设备的吞吐量以及每个设备可以处理的并发用户数。
|
|
|
|
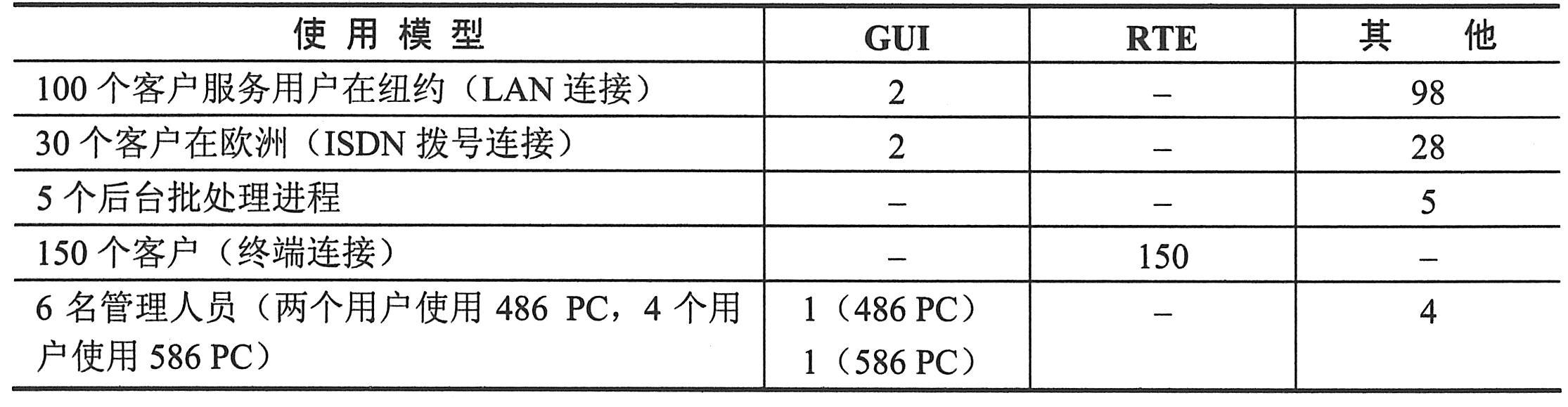
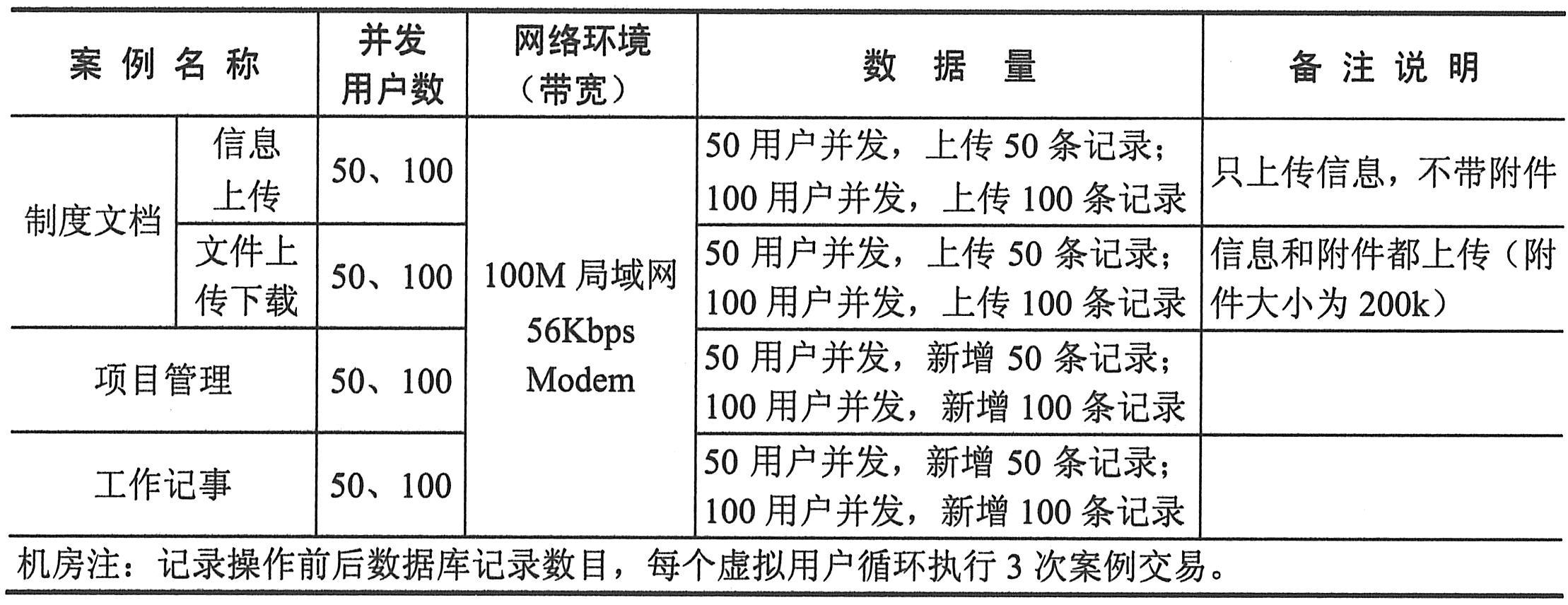
例如,在如上图所示的示意图中,多个应用程序客户端在访问系统。客户端的配置如下表所示。
|
|
|
|
|
|
|
|
|
|
定义系统的典型使用方式,并确定需要重点测试的功能。考虑哪些用户使用系统、每种类型用户的数量,以及每个用户的典型任务。此外,还应考虑任何可能影响系统响应时间的后台负载。
|
|
|
|
例如,假设每天上午有200名员工登录记账系统,并且该办公室网络有固定的后台负载:50名用户执行各种字处理和打印任务。可以创建一个200个虚拟用户登录访问记账数据库的方案,并检测服务器的响应时间。要了解后台负载对响应时间的影响,可以在运行方案的网络中再模拟员工执行字处理和打印活动的负载。
|
|
|
|
|
|
除定义常规用户任务外,还应该查看这些任务的分布情况。例如,假设银行用户使用一个中央数据库为跨越多个州和时区的客户提供服务。250个应用程序客户端分布在两个不同的时区,全都连接到同一个Web服务器中。其中150个在芝加哥,另外100个在底特律。每个客户端从上午9点开始工作,但由于处于不同的时区,因此在任何特定时间内都不会有超过150个的用户同时登录。可以分析任务分布,以确定数据库活动峰值期的发生时间,以及负载峰值期间的典型活动。
|
|
|
|
|
|
|
|
|
|
确定了负载测试的一般性目标后,应该以可度量指标制定更具针对性的目标。为了提供评估基准,应精确地确定、区分可接受和不可接受测试结果的标准。
|
|
|
|
|
|
|
|
. 明确目标产品评估:在一台HP服务器和一台NEC服务器上运行同一个包含300个虚拟用户的组。当300个用户同时浏览Web应用程序页面时,确定哪一种硬件提供更短的响应时间。
|
|
|
|
|
|
①度量最终用户的响应时间,完成一个业务流程需要多长时间;
|
|
|
|
②定义最优的硬件配置,哪一种硬件配置可以提供最佳性能;
|
|
|
|
③检查可靠性,系统无错误或无故障运行的时间长度或难度;
|
|
|
|
|
|
|
|
⑥度量系统容量,在没有显著性能下降的前提下,系统能够处理多大的负载;
|
|
|
|
|
|
|
|
负载测试应贯穿于产品的整个生命周期。如下表说明了在产品生命周期的各个阶段有哪些类型的测试与之相关。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可以度量应用程序中不同点的响应时间。根据测试目标确定在哪里运行Vuser(虚拟用户)以及运行哪些Vuser。
|
|
|
|
|
|
可以在前端运行GUI Vuser(图形用户界面用户)或RTE Vuser(终端用户)来度量典型用户的响应时间。GUI Vuser可以将输入提交给客户端应用程序并从该应用程序接收输出,以模拟实际用户;RTE Vuser则向基于字符的应用程序提交输入,并从该应用程序接收输出,以模拟实际用户。
|
|
|
|
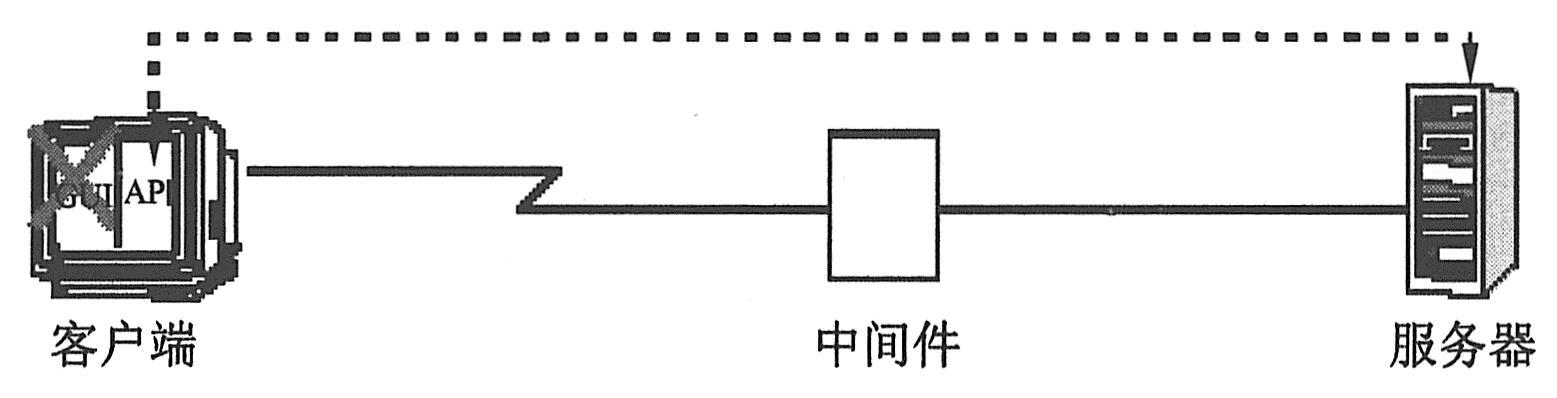
可以在前端运行GUI或RTE Vuser来度量跨越整个网络(包括终端仿真器或GUI前端、网络和服务器)的响应时间。如下图所示为端到端的响应时间。
|
|
|
|
|
|
|
|
|
|
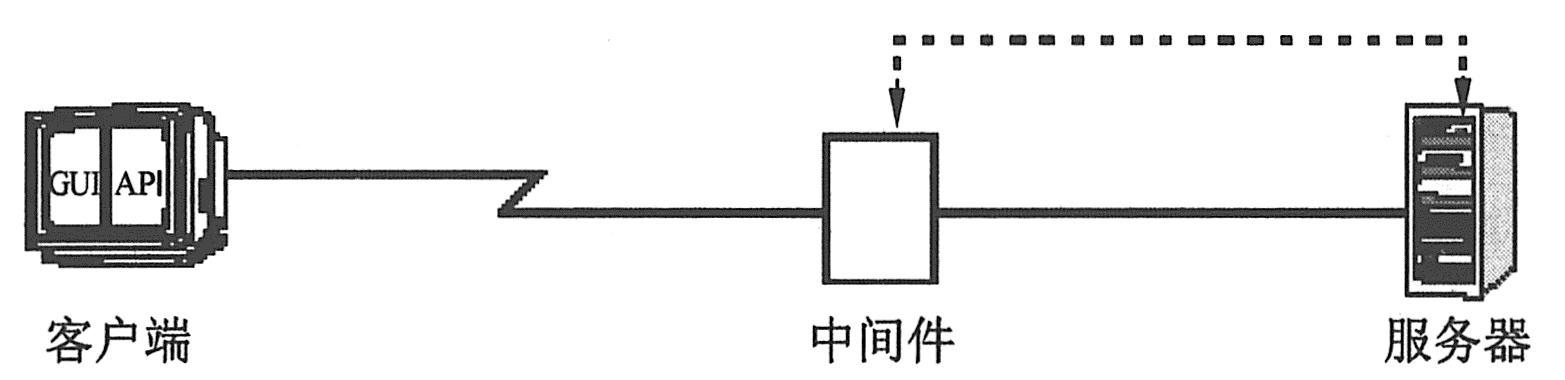
可以通过在客户机运行Vuser(非GUI或RTE Vuser)来度量网络和服务器的响应时间(不包括GUI前端的响应时间)。Vuser模拟客户端对服务器的进程调用,但不包括用户界面部分。在客户机运行大量Vuser时,可以度量负载对网络和服务器响应时间的影响。如下图所示为网络和服务器的响应时间。
|
|
|
|
|
|
|
|
|
|
可以通过减去前两个度量值,来确定客户端应用程序界面对响应时间的影响。GUI响应时间=端到端响应时间-网络和服务器响应时间。如下图所示为GUI响应时间。
|
|
|
|
|
|
|
|
|
|
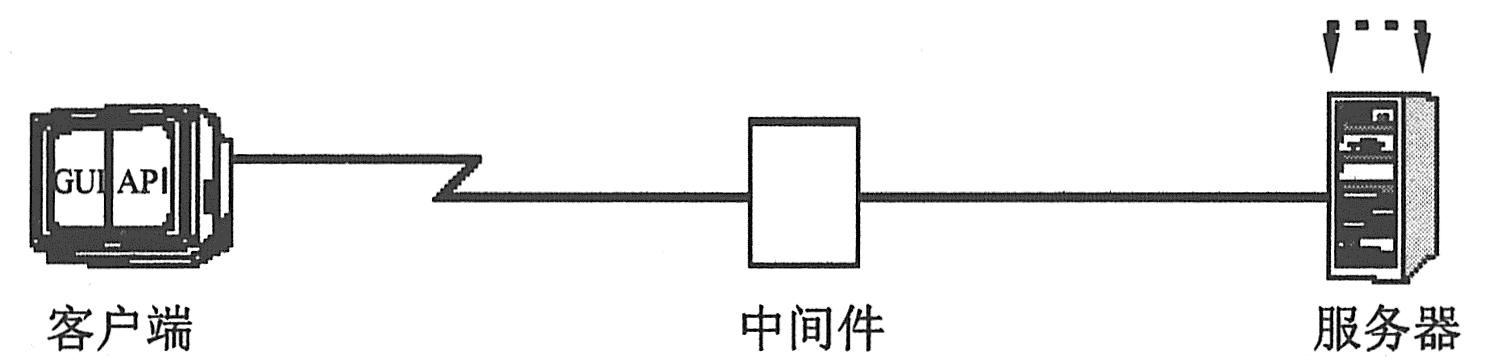
可以度量服务器响应请求(不跨越整个网络)所花费的时间。通过在与服务器直接相连的计算机上运行Vuser,可以度量服务器性能。如下图所示为服务器响应时间。
|
|
|
|
|
|
|
|
|
|
如果可以访问中间件及其API,便可以度量服务器到中间件的响应时间。可以使用中间件API创建Vuser,来度量中间件到服务器的性能。如下图所示为中间件到服务器响应时间。
|
|
|
|
|
|
根据对Vuser类型的分析以及它们的典型任务和测试目标来创建Vuser脚本。由于Vuser模拟典型最终用户的操作,因此Vuser脚本应包括典型的最终用户任务。例如,要模拟联机银行客户端,应该创建一个执行典型银行任务的Vuser脚本。需要浏览经常访问的页面,以转移现金或支票余额。
|
|
|
|
|
|
|
|
根据测试目标确定要衡量的任务,并定义这些任务的事务。这些事务度量服务器响应Vuser提交的任务所花费的时间(端到端时间)。例如,要查看提供账户余额查询的银行Web服务器的响应时间,则应在Vuser脚本中为该任务定义一个事务。
|
|
|
|
此外,可以通过在脚本中使用集合点来模拟峰值期活动。集合点指示多个Vuser在同一时刻执行任务。例如,可以定义一个集合点,以模拟70个用户同时更新账户信息的情况。
|
|
|
|
|
|
确定用于测试的硬件配置之前,应该先确定需要的Vuser的数量和类型。要确定运行多少个Vuser和哪些类型的Vuser,请综合考虑测试目标来查看典型的使用模型。以下是一些一般性规则:
|
|
|
|
. 使用一个或几个GUI用户来模拟每一种类型的典型用户连接;
|
|
|
|
|
|
. 运行多个非GUI或非RTE Vuser来生成每个用户类型的其余负载。
|
|
|
|
例如,假设有五种类型的用户,每种用户执行一个不同的业务流程,如下表所示。
|
|
|
|
|
|
|
|
|
|
硬件和软件应该具有强大的性能和足够快的运行速度,以模拟所需数量的虚拟用户。
|
|
|
|
在确定计算机的数量和正确的配置时,请考虑以下事项。
|
|
|
|
|
|
. 在一台Windows计算机只能运行一个GUI Vuser;而在一台UNIX计算机上则可以运行几个GUI Vuser。
|
|
|
|
. GUI Vuser测试计算机的配置应该尽量与实际用户的计算机配置相同。
|
|
|
|
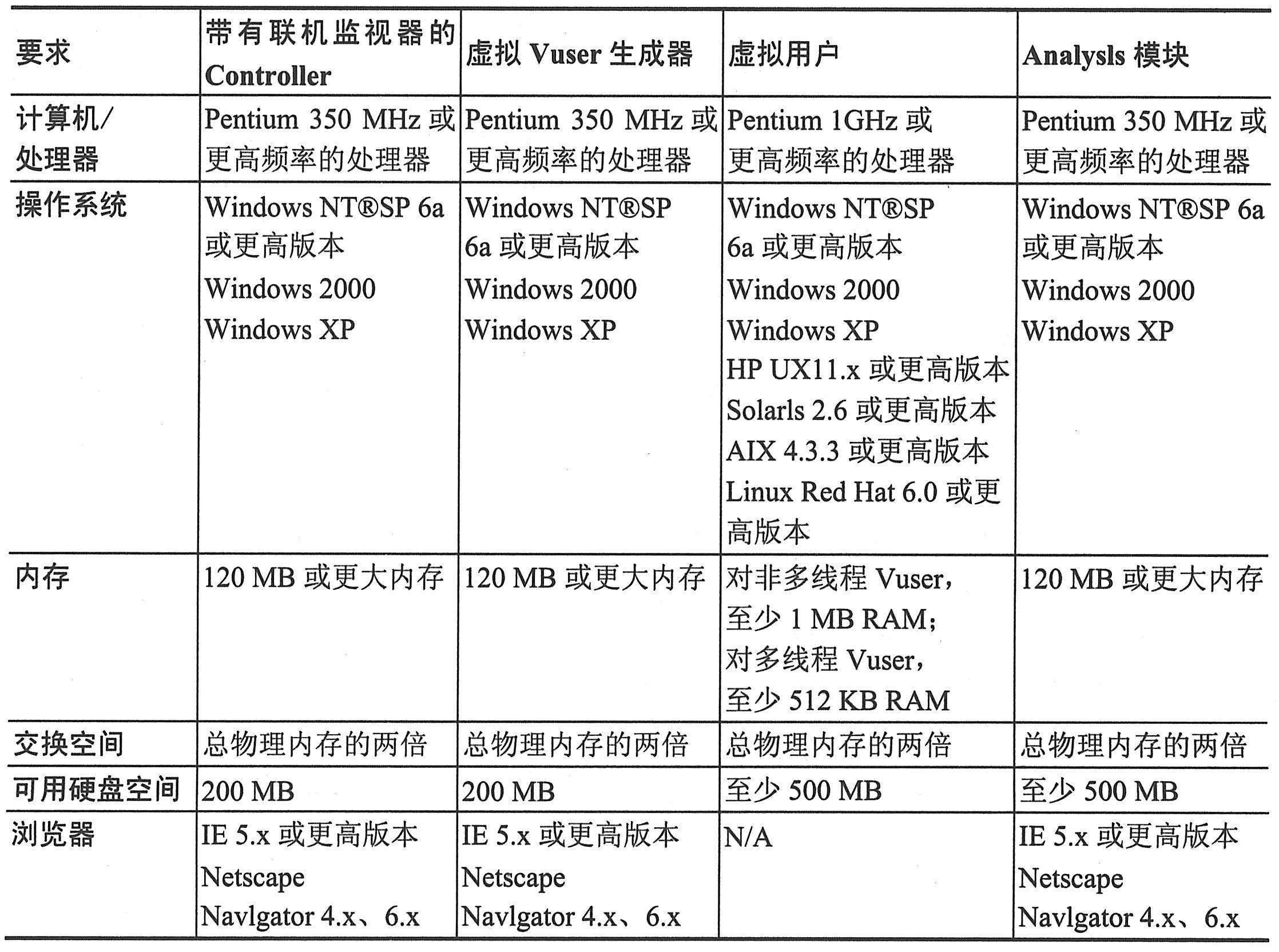
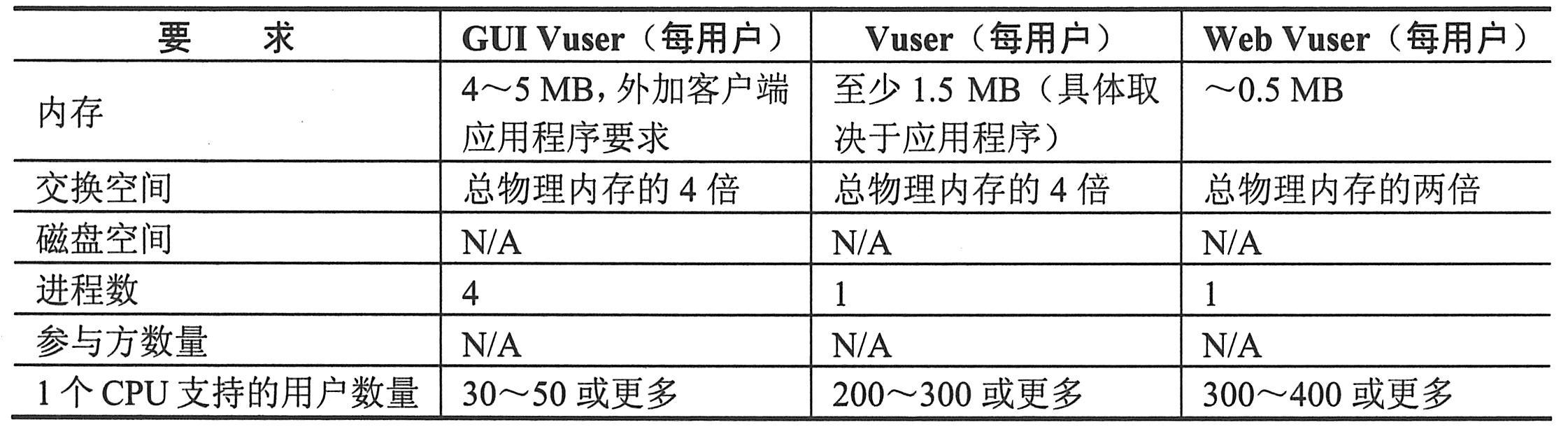
关于每个测试组件的硬件要求,请参考下表一和下表二。要获得最佳性能,应满足表中所列要求。
|
|
|
|
|
|
|
|
注意:对于一个要运行许多事务的长方案,结果文件需要几个MB的磁盘空间。负载生成器计算机还需要几个MB的磁盘空间来存储临时文件(如果没有NFS)。有关运行时文件存储的详细信息,请参阅第10章“配置方案”。
|
|
|
|
|
|
http://www.mercuryinteractive.com/products/loadrunner/technical/
|
|
|
|
|
|
|
|
注意:对于一个要运行许多事务的长方案,结果文件需要几个MB的磁盘空间。负载生成器计算机还需要几个MB的磁盘空间来存储临时文件(如果没有NFS)。有关运行时文件存储的详细信息,请参阅第10章“配置方案”。
|
|
|
|
|
|
测试计划应该基于明确定义的测试目标。下面概述了常规的测试目标。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
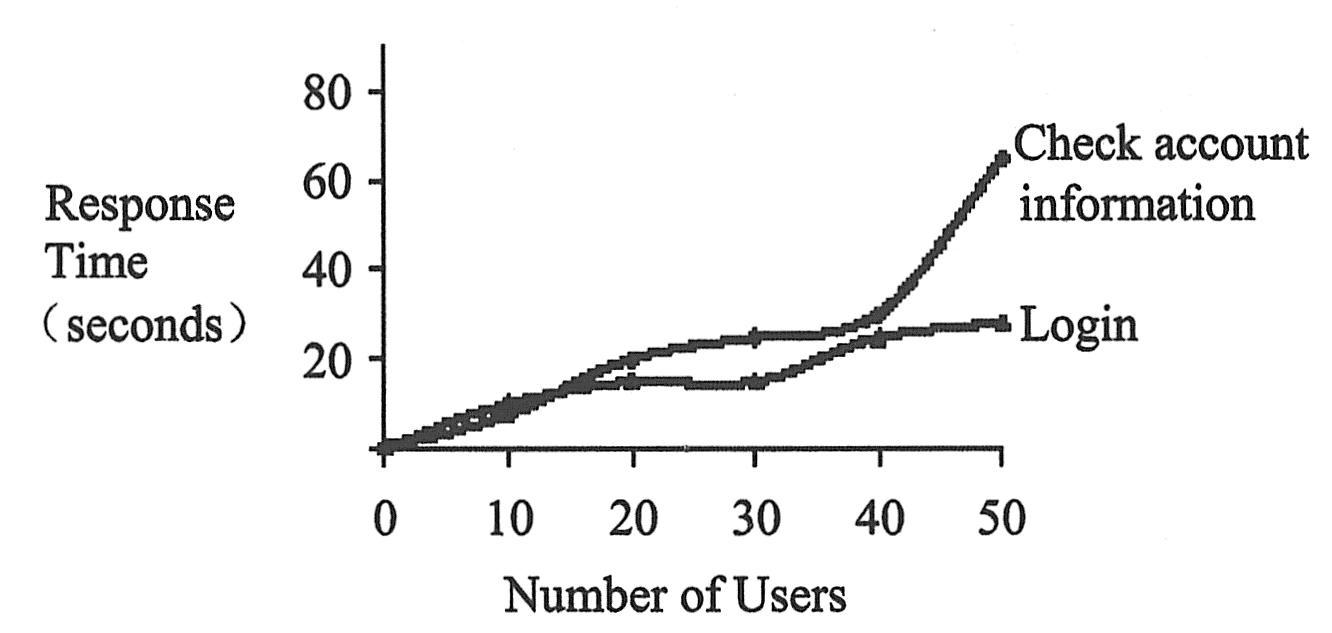
查看用户执行业务流程以及从服务器得到响应所花费的时间。例如,假设想要检测:系统在正常的负载情况下运行时,最终用户能否在20秒内得到所有请求的响应。如下图显示了一个银行应用程序的负载和响应时间度量之间的关系。
|
|
|
|
|
|
|
|
|
|
检测各项系统配置(内存、CPU速度、缓存、适配器、调制解调器)对性能的影响。了解系统体系结构并测试了应用程序响应时间后,可以度量不同系统配置下的应用程序响应时间,从而确定哪一种设置能够提供理想的性能级别。
|
|
|
|
例如,可以设置三种不同的服务器配置,并针对各个配置运行相同的测试,以确定性能上的差异。
|
|
|
|
|
|
|
|
|
|
|
|
确定系统在连续的高工作负载下的稳定性级别。可以创建系统负载:强制系统在短时间内处理大量任务,来模拟系统在数周或数月的时间内通常会遇到的活动类型。
|
|
|
|
|
|
执行回归测试,以便对新旧版本的硬件或软件进行比较。可以查看软件或硬件升级对响应时间(基准)和可靠性的影响。应用程序回归测试需要查看新版本的效率和可靠性是否与旧版本相同。
|
|
|
|
|
|
可以运行测试,以评估单个产品和子系统在产品生命周期中的计划阶段和设计阶段的表现。例如,可以根据评估测试来选择服务器的硬件或数据库套件。
|
|
|
|
|
|
可以运行测试以确定系统的瓶颈,并确定哪些因素导致性能下降,例如,文件锁定、资源争用和网络过载。使用负载压力测试工具,以及网络和计算机监视工具以生成负载,并度量系统中不同点的性能。如下图所示为系统不同点的性能。
|
|
|
|
|
|
|
|
|
|
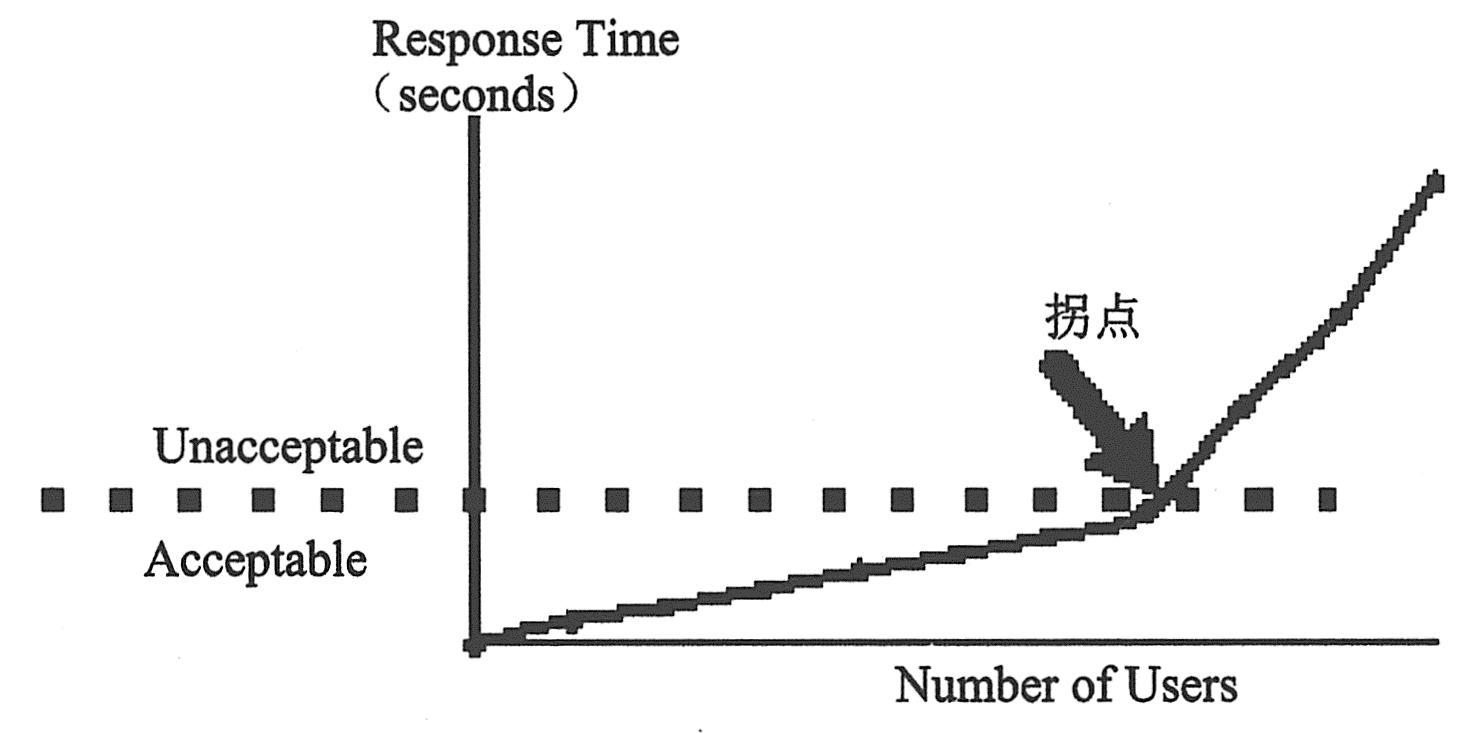
度量系统容量,并确定系统在不降低性能的前提下能提供多少额外容量。要查看容量,可以查看现有系统中性能与负载间的关系,并确定出现响应时间显著延长的位置。该处通常称为响应时间曲线的“拐点”。确定了当前容量后,便可以确定是否需要增加资源以支持额外的用户。如下图所示为响应时间与负载关系。
|
|
|
|
|
|
|
|
|
|
负载压力测试需求分析既需要借助于相关的理论知识,又要依靠测试工程师在相关领域的经验积累,下面分别介绍一些理论知识及经验方法。
|
|
|
|
|
|
测试需求是应用需求的衍生,而且测试用例也必须覆盖所有的测试需求,否则,这个测试过程就是不完整的。主要有以下的几个关键点:
|
|
|
|
. 测试的对象是什么,例如“被测系统中有负载压力需求的功能点包括哪些”;“测试中需要模拟哪些部门用户产生的负载压力”等问题。
|
|
|
|
. 系统配置如何,例如“预计有多少用户并发访问”;“用户客户端的配置如何”;“使用什么样的数据库”;“服务器怎样和客户端通信”;“网络设备的吞吐能力如何,每个环节承受多少并发用户”等问题。
|
|
|
|
. 应用系统的使用模式是什么,例如“使用在什么时间达到高峰期”;“用户使用该系统是采用B/S运行模式吗”等问题。
|
|
|
|
我们来针对用户提出的问题,做一个简单的需求回答,如下表所示。
|
|
|
|
|
|
|
|
|
|
下面我们介绍80~20原理测试强度估算及UCML压力需求分析。
|
|
|
|
|
|
80~20原理:每个工作日中80%的业务在20%的时间内完成。例如,每年业务量集中在8个月,每个月20个工作日,每个工作日8小时即每天80%的业务在1.6小时完成。
|
|
|
|
举一个例子来看80~20原理如何应用与测试需求分析。
|
|
|
|
去年全年处理业务约100万笔,其中,15%的业务处理中,每笔业务需对应用服务器提交7次请求;70%的业务处理中,每笔业务需对应用服务器提交5次请求;其余15%的业务处理中,每笔业务需对应用服务器提交3次请求。根据以往的统计结果,每年的业务增量为15%,考虑到今后3年业务发展的需要,测试需按现有业务量的两倍进行。
|
|
|
|
|
|
每年总的请求数为:(100×15%×7+100×70%×5+100×15%×3)×2=1000万次/年;
|
|
|
|
每天请求数为:1000/160=6.25万次/天;
|
|
|
|
每秒请求数为:(62500×80%)/(8×20%×3600)=8.68次/秒;
|
|
|
|
|
|
UCML(User Community Modeling Language)压力需求分析
|
|
|
|
UCML?是一个符号集合,这些符号可以创建虚拟系统用法模型,以及描述相关参数。当把它应用到负载压力性能测试时,这些符号可用于表示工作量分配、操作流程、重点工作表、矩阵和马尔可夫链等。负载压力性能测试工程师在决定测试中用到什么活动,以及它们发生的频率时,经常用到这些参量。UCML输出的结论图表可有效地应用于文档,甚至是测试计划、测试设计等,还可作为讨论和数据整理的依据。系统分析人员和用户还可以用它们回顾和验证工作流程和工作量的需求。
|
|
|
|
UCML?给支持负载压力性能测试的复杂数学模型创建一个直观的可视化模型,对于数学模型来说,UCMLT?不是代替品,而是一种补充。现在至少可以证明这一可视化技术对测试人员、应用用户、开发者、经理和商家来说都是相当直观的。根据我们的经验,它使类似于“此activity通用吗”、“为什么activityB必须以activityD作为先决条件,这是不正确的”,甚至“如何再次阅读重点工作表”这样的重要问题得到了更直观的表现。
|
|
|
|
没有专门对应于UCMLT?的画图工具,除了用SmartDraw画UCMLT?模型时,还可以应用PowerPoint、Microsoft Visio等软件来画,而且我们可以为Microsoft Visio和SmartDraw创建符号库。
|
|
|
|
UCMLT?不是一种工业标准,现在还不能证明是适用于任何类似IEEE的工业标准或规范。用户可以应用其中的全部或部分符号,或者按照需要来修改或改进它们。下面我们来看看UCML?的符号。
|
|
|
|
|
|
基本符号可以表示系统应用。在许多情况下,一个用法路径可以看作是一个应用会话。事实上,用法路径是UCML?的基础,因为项目组的所有成员早已理解了系统应用。
|
|
|
|
|
|
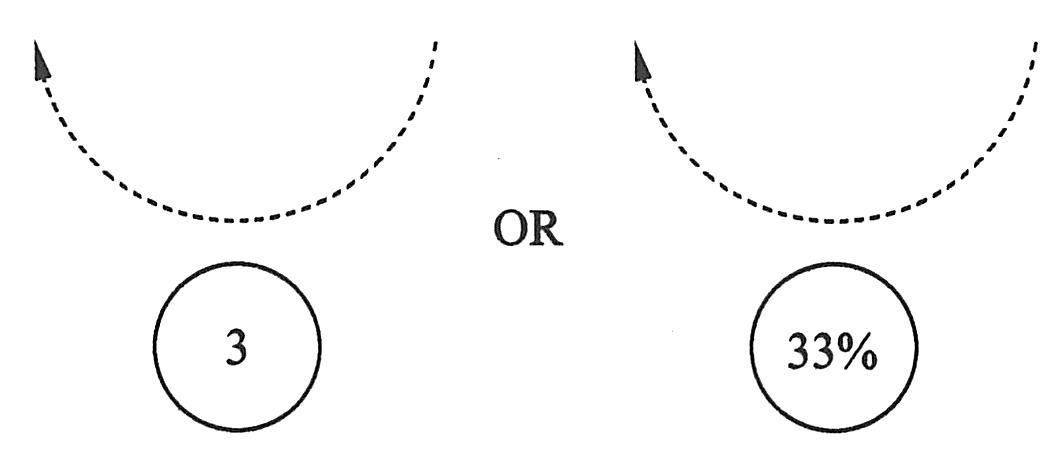
数量环是用来回答“多少”、“多大频率”问题的。圆圈里显示的是一个数或者百分比。例如,在模拟精确量的时候用数,不管人数的具体多少;在模拟整个用户群中的一部分时,用百分比表示。如下图所示为数量环。
|
|
|
|
|
|
|
|
|
|
描述线是水平的实线,表示activity和用户类型。每个描述线都标注了一个或多个描述内容,来显示用户类型、activity或运行路径。附在描述语句后面的圆括号里的内容是所有同类用户的百分比,或者是在一定时间段内运行这一activity、执行这条路径的用户百分比。在一定情况下,用数量环来描述特定用户类型、activity、数量和频率更直观。通常,当有多项标注的activity出现或者同一条线上出现相同的数量或频率时,使用数量环,当数量或频率附属于一个特定activity时,使用圆括号。
|
|
|
|
|
|
用户类型描述线在模型的最左边,表示将要进入已创建的应用中的用户类型,例如:基本用户、超级用户、管理员。与用户类型相关的百分比显示了所有用这种类型表示的系统中的用户比例。如下图所示为用户类型描述。
|
|
|
|
|
|
|
|
|
|
activity类型描述线表示系统的不同类型用户的activity和运行路径。线的上面列出了已完成的用户activity,或运行路径所查看的界面。由建模人员决定应该将特定activity的每个步骤列出还是简单地给activity命名。记录的关键是每个水平线表示毫无转折的到达该activity的直线路径。这条线可以分出支路也可以合并,表示通过该系统对行动路线的选择。选择特定运行路径的用户的百分比显示在路径始端的数量环里。在模型中任何一个指定点,所有运行路径的用户之和都是100%,与访问站点的人数相同。如下图所示为activity类型描述线。
|
|
|
|
|
|
|
|
|
|
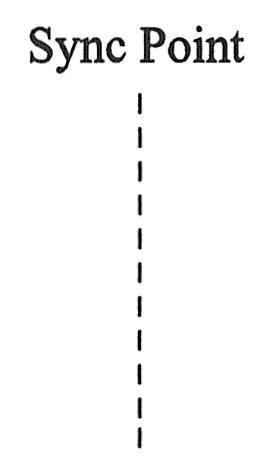
垂直的虚线表示模型中的同步节点。如果同步节点已命名,就将它的名字写在线的上方。同步节点用于描述合并。有两种可以用同步节点符号表示的合并,即时间上的合并和运行点的合并。如下图所示为同步点。
|
|
|
|
|
|
|
|
时间上的合并意味着在进程开始之前,先到达同步节点的建模用户必须等待所有其他建模用户都到达此节点。在建立信息系统时,这是非常有帮助的。
|
|
|
|
运行点上的合并意味着,所有建模用户都运行通过了应用中的同一位置,但不一定在同一时间。网站的注册界面就是一个常见的例子。在这个例子中,所有用户在被允许访问其他界面之前,必须在同一网页上填写各自的资格鉴定。在开发脚本时鉴别这些运行同步节点是很有帮助的,因为它们可以为脚本、草稿、功能、程序等充当普通的开始/关闭点。
|
|
|
|
我们发现,在名称后用圆括号插入同步节点类型的注释很有帮助,例如:“同步点1(time)”。
|
|
|
|
|
|
系统运行时,常常要求用户进行一些不会改变其全部行为的选择或输入数据。模型中,用位于运行路径下方的一个虚线框来表示这些选项。如下图所示。
|
|
|
|
|
|
|
|
选择框需要标注一个词或断语,来描述那些随着用户的改变而变化的选择和数据。特定数据将会记录在模型内的电子数据表中。
|
|
|
|
|
|
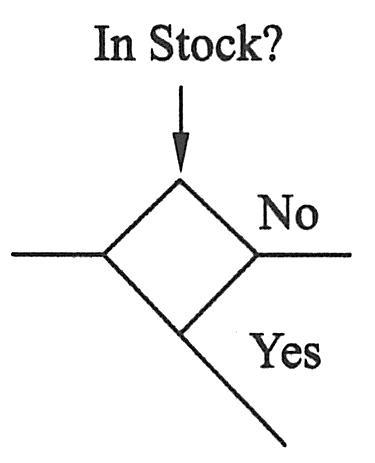
模型中,条件是用户根据结果来改变其运行路径的节点。下面的例子里,假设用户要购买一本书。如果用户查询后,发现它有库存,用户就按照“Yes”路径购买此书。但是,如果此书无库存,用户就按照“No”路径取消此过程。如下图所示为条件。
|
|
|
|
|
|
|
|
|
|
在运行路径上,虚线的半圆弧表示循环,半圆弧所环绕的活动将重复执行。需要反复的次数或需要重复此行为的用户百分数(不是模型表示的所有用户),标注在数量环里。如下图所示。
|
|
|
|
|
|
|
|
|
|
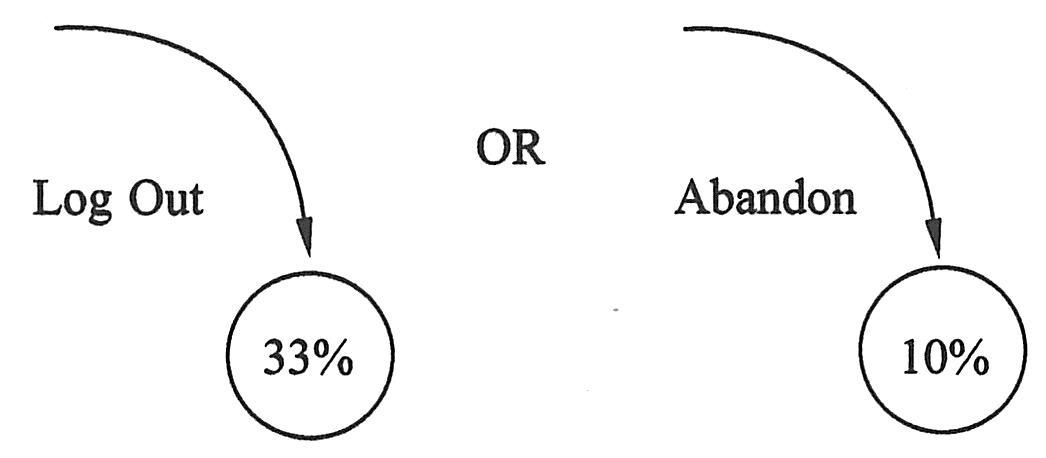
除了运行路径中断的节点以外,构筑用户的跳出是非常重要的。指向数量环的下划线表示路径在具体某点处,将要跳出系统的用户百分比。记住,所有进入系统的用户都应显示退出。跳出系统的类型应记录在标签上,例如“Log Out”(如果用户基于首选方式退出系统)或“Abandon”(如果用户没有基于首选方式退出系统)。如下图所示为跳出路径单方式。
|
|
|
|
|
|
|
|
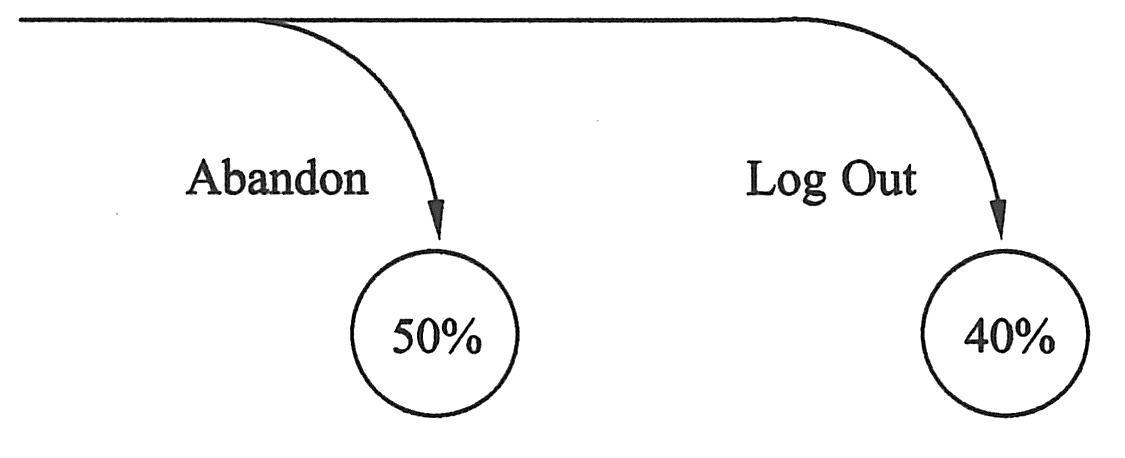
下面的例子显示了从运行路径跳出的多种方式。其中,50%的用户放弃了系统,40%的用户正在退出系统,因此他们是以首选方式跳出系统的(另外的10%从另一个运行路径跳出,没有给出表示)。如下图所示为跳出路径多种方式。
|
|
|
|
|
|
|
|
|
|
大多数应用是不局限于直线路径的。开始执行同一activity的一组用户,可能只是为了以后分支到不同的运行路径中。如果我们把activity线想象成汽车运行的马路,那么分支就表示由司机进行方向选择的十字路口。下面的例子显示了一个分支,可以在这个分支上选择两条路径中的一条离开主页。分支上用户百分数的和必须等于引起分支的界面上的用户百分比。这个例子里,主页有100%的用户,而分支上的百分比之和也是100%。如下图所示为分支一。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
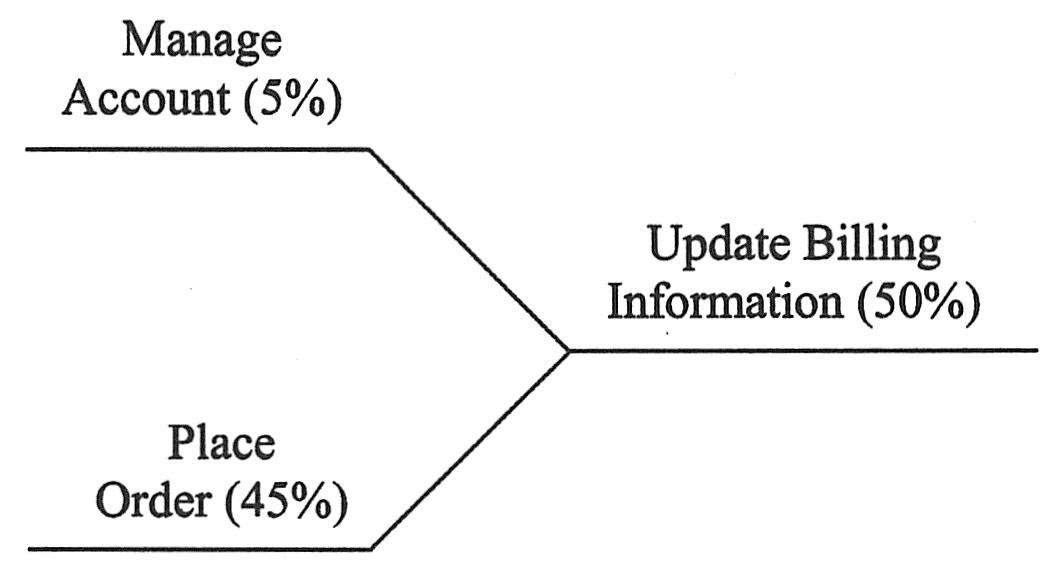
带有分支的运行路径常遇到将不同分支合并到一起的情况。仍以交通类推,这就相当于来自不同道路的汽车行驶到同一条马路。下面的例子显示了两个不同路径合并到Update Billing Information这一activity。同理,合并前的用户的总百分比必须等于合并后的总用户百分比。如下图所示为分支合并。
|
|
|
|
|
|
|
|
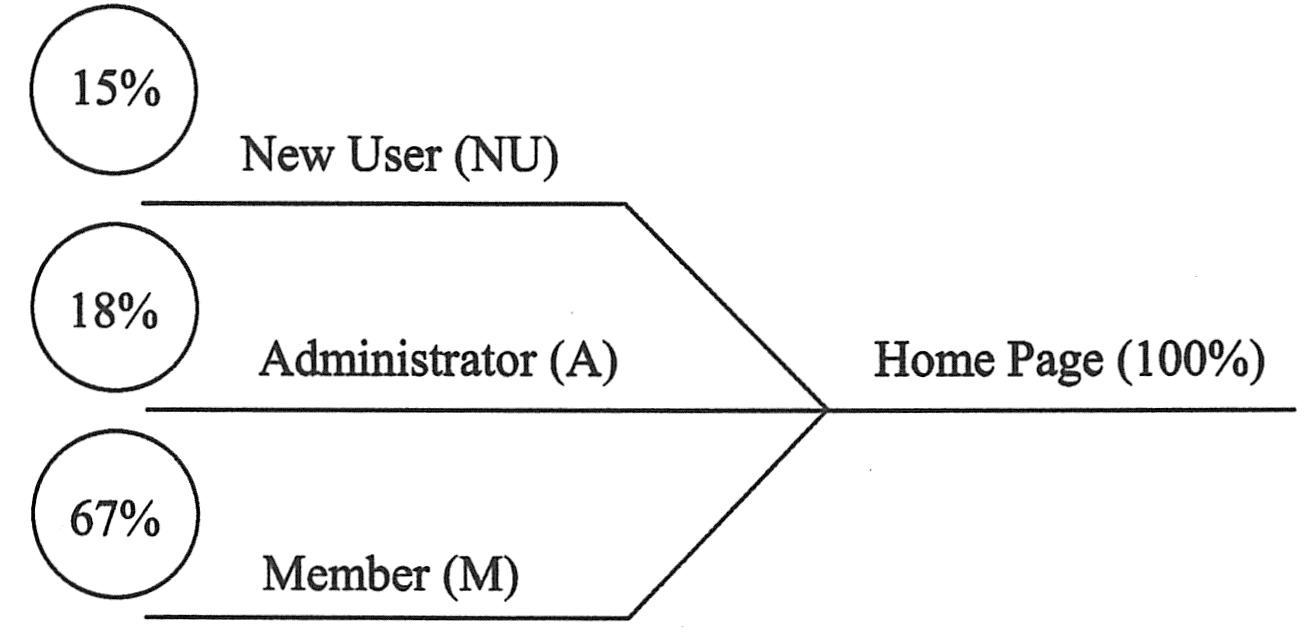
另外一个常应用的合并是为了显示不同类型的用户在同一点进入了软件,如下图所示。这里,每个不同类型的用户用不同的颜色表示。这样做是为了在以后的模型中,使对应于特定用户组的行为能够通过颜色区分。每个用户类型后面都用圆括号标注了它的缩写,这些缩写在以后的模型中也可以应用。这对那种必须由黑白表示的模型特别有利。
|
|
|
|
|
|
|
|
我们可以将符号组合为User Community模型。
|
|
|
|
基本符号的组合使UCML?语言更加强大。通过组合符号,可以在一个能形成整个Community的虚拟模型的系统中,表示所有可能的用户运行路径。再以交通类比,将模型中的线想象成马路、每个建模用户想象成在这些路上行驶的汽车。把两条或更多条线相遇的点看作十字路口,将同步点看作是交通信号,将跳出看作是驶出轨道。数量环显示出马路的运行载重,因此创建了一个用户如何穿过软件的“地图”。
|
|
|
|
举个例子,我们将为在线书店建立一个UCML?图表。假设这是一个新的应用,所以我们没有可以分析利用的现存数据。经过一系列的采访,我们收集了下面的信息。它们是关于用户进入网站的activity和他们预期的相关量。
|
|
|
|
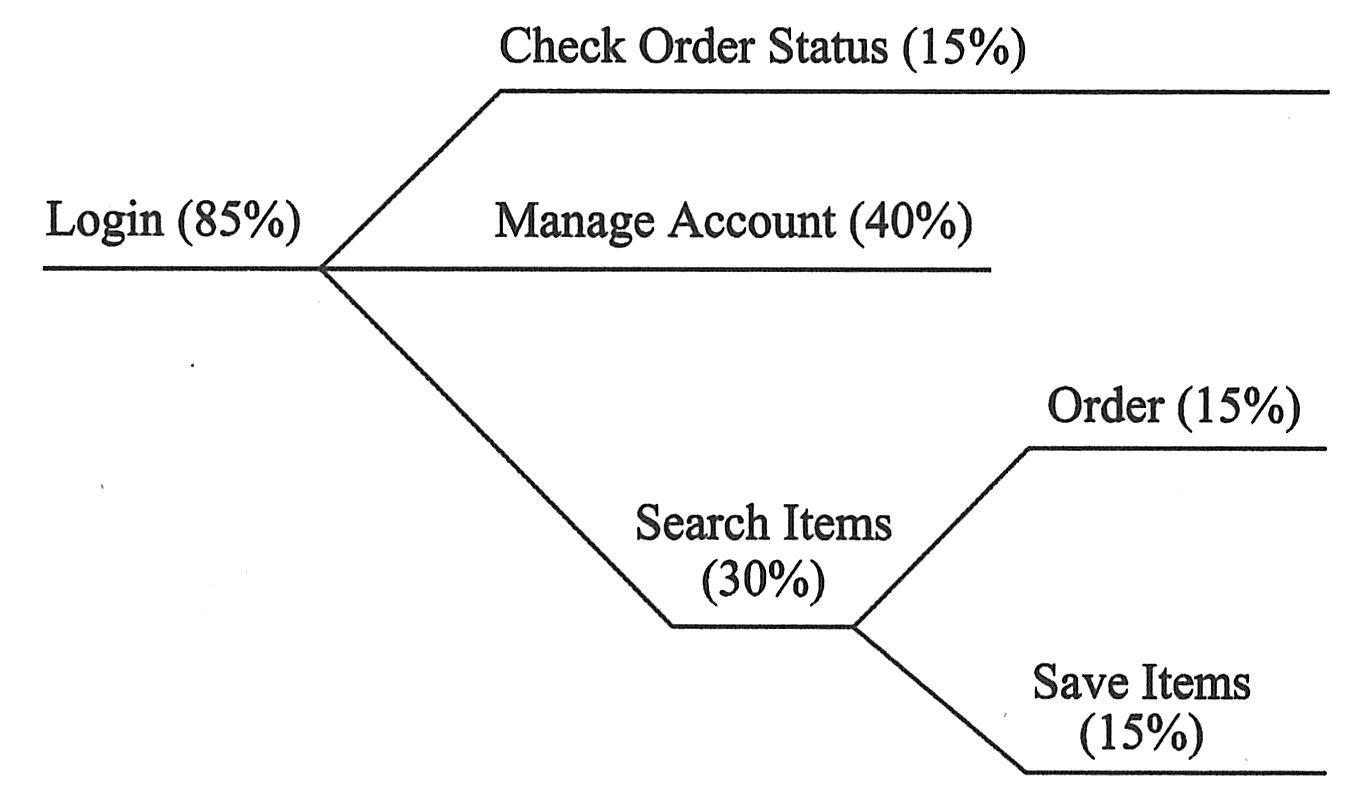
. 四种用户类型:新用户(20%),会员(70%),管理员(4%),商家(6%)。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. 新用户可以开设账户(开设账户后就变成了会员)。
|
|
|
|
. 会员可以选择以下activity:进入系统、升级账户、项目结算、检查结算状态。
|
|
|
|
. 管理员和商家必须从主页进入系统,再从管理员界面开始。
|
|
|
|
. 管理员可以选择以下activity:添加新书、检查结算状态、升级结算状态、取消命令。
|
|
|
|
. 商家可执行以下报告:库存、上周销售额、上月销售额。
|
|
|
|
|
|
|
|
|
|
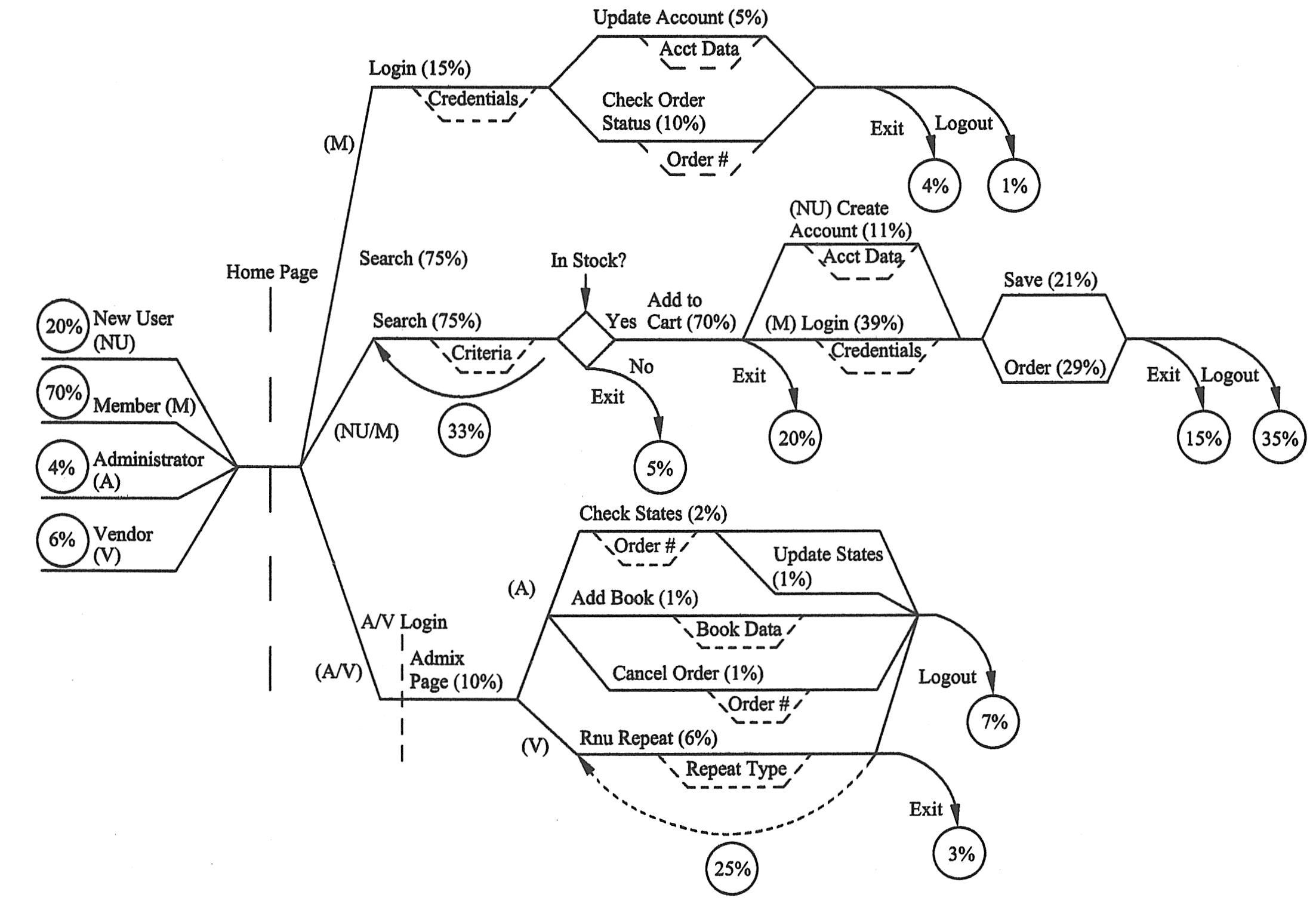
很明显,如上图所示包含了访问总结中所未提到的信息,这些信息是为最初草案而估计的。仔细观察还会发现,不是所有来自于访问总结的信息都囊括进来了。现在图标可以反馈到被采访者处了,以便他们确认或改正运行路径和用户量、添加或删除activity。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. 系统日常业务主要有哪些操作,高峰期主要有哪些操作。
|
|
|
|
|
|
|
|
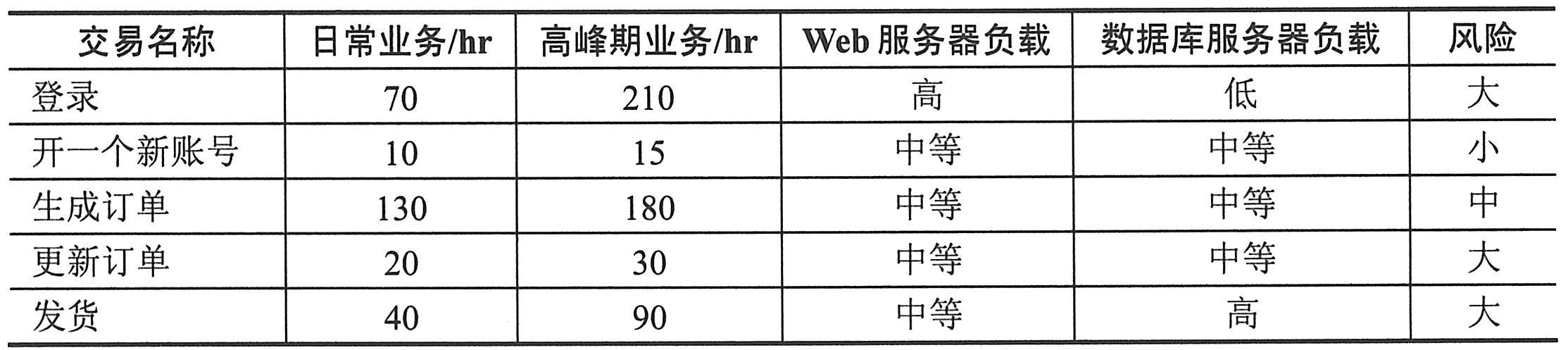
选择重点交易的指标为高吞吐量、高数据库I/O、高商业风险。举例如下表所示,“登录”、“生成订单”以及“发货”为负载压力测试重点。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
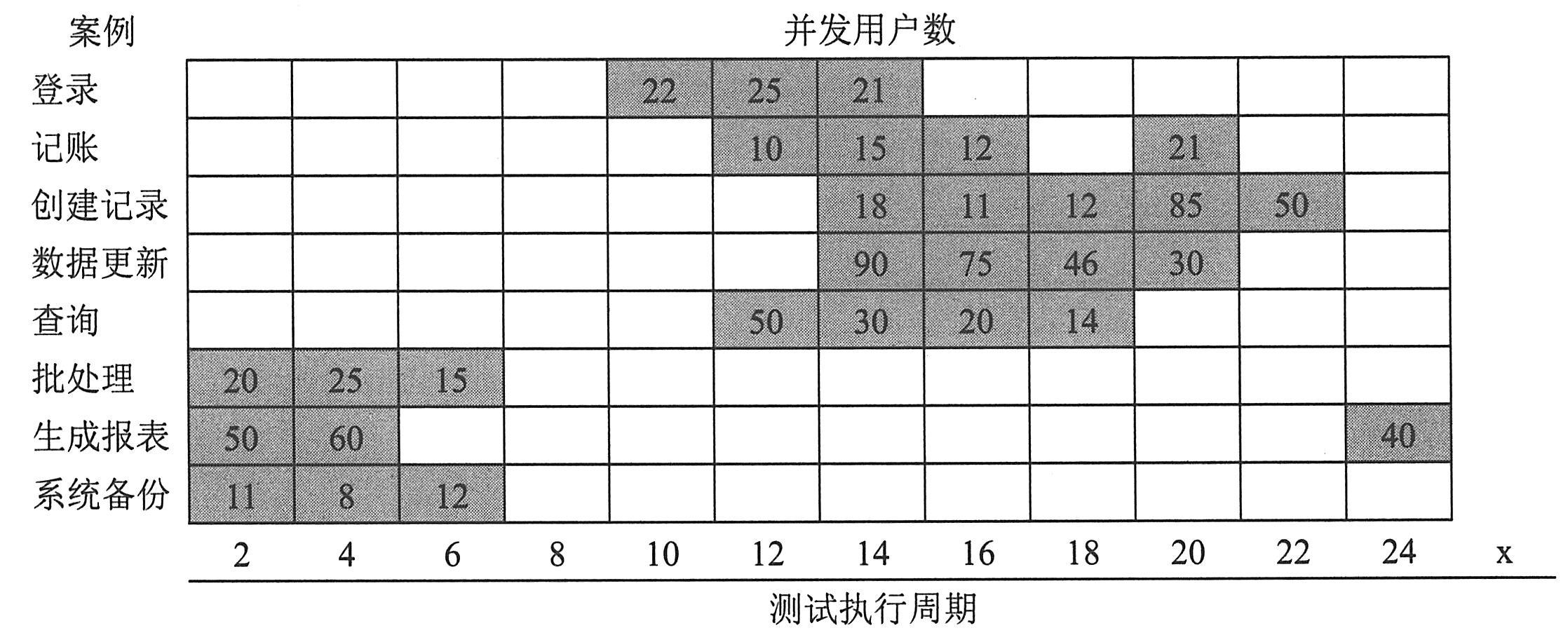
如下表所示为任务频率表,负载压力测试需要模拟不同用户角色压力。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
测试策略一般包括对比测试环境和真实业务测试环境,真实业务操作环境又可能涉及局域网测试环境和机房测试环境等。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
测试内容一般包括并发性能测试、疲劳强度测试、大数据量测试和系统资源监控等。
|
|
|
|
|
|
|
|
测试环境直接影响测试效果,所有的测试结果都是在一定软硬件环境约束下的结果,测试环境不同,测试结果可能会有所不同,特别对于压力负载测试更是如此,因为压力负载测试结果往往是一组和时间有关的值,因此对负载压力测试环境的准备就显得特别的重要。
|
|
|
|
|
|
. 要满足软件运行的最低要求,不一定选择将要部署的环境;
|
|
|
|
|
|
|
|
|
|
|
|
负载压力测试环境准备过程中可以参考测试环境的基本准则,但是又要考虑负载压力测试的特殊性和负载压力测试目的。负载压力测试一般强调“真实”应用环境下的性能表现,从而实现性能评估、故障定位以及性能优化的目的,因此在负载压力测试环境的准备中要注意以下几点:
|
|
|
|
. 如果是完全真实的应用运行环境,要尽可能降低测试对现有业务的影响;
|
|
|
|
. 如果是建立近似的真实环境,要首先达到服务器、数据库以及中间件的真实,并且要具备一定的数据量,客户端可以次要考虑;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. 操作系统的版本(包括各种服务、安装及修改补丁);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
大多数情况下我们强调真实环境下检测系统性能,在实施过程中大家认为这样做会遇到很多阻力,比如真实环境下,不允许负载压力测试为系统带来大量的垃圾数据;测试数据与真实业务数据混在一起无法控制测试结果;负载压力测试如果使服务器宕机,会给系统带来巨大损失等。那么我们应该如何理解“真实环境下检测系统性能”呢?
|
|
|
|
在负载压力测试中我们强调的“真实环境”是指后台服务器与客户端应用要与实际真实应用环境保持一致,同时,这里也包括了与业务有关的软硬件配置环境和数据量环境等,可以看出我们将网络环境排除在外。原因是网络环境缓解了客户端对服务器所造成的并发负载压力,网络规模越大、网络类型越多、网络拓扑越复杂、网络流量越纷繁交织对客户端的并发负载压力缓解程度越大。
|
|
|
|
|
|
这里主要讨论选择测试工具的原则,介绍一些主流负载压力测试工具,同时也涉及到测试工具的缺陷等内容。
|
|
|
|
|
|
古人云“工欲善其事,必先利其器”,进行负载压力性能测试首先应该选择一个合适的测试工具,一个测试工具能否满足测试需求、能否达到令人满意的测试结果,是选择测试工具要考虑的最基本的问题。更进一步可以考虑一些细节问题,比如该工具对于处理扩展的交互(例如一个请求取决于上一个请求的结果)如何;对于处理cookies(cookies对于许多面向会话的J2EE系统是必不可少的)如何;如果J2EE应用程序客户机需要处理一些JavaScript,以进入下一次通信会如何处理;在收集了响应时间数据后,如何对它进行分析;对CPU时间、网络使用、堆大小、分页活动或者数据库活动如何监控等都是选择一个测试工具需要考虑的具体问题。一些高端工具与基本工具往往在一些细节、适用范围以及易用性方面存在差别。比如,顶级的负载测试工具可以模拟多个浏览器,与大多数应用服务器集成,收集多个服务器主机的性能数据(包括操作系统、JVM和数据库统计数字),生成可以在以后用高级的分析工具分析的数据集。
|
|
|
|
当然,测试工具的选择首先应该看是否能够满足基本测试需求,该工具必须可以模拟应用程序客户机,如果应用程序使用一些不常见的浏览器功能组合或者其他非标准客户机技术,那么就排除了相当一部分候选者。具备了基本功能后,可以考虑工具的生产率。一般来说,包含的分析工具越多,可以记录的性能数据类型越多,可以达到的生产率就越高,价格也就越高。不过有些低端负载测试程序是免费的,在预算有限的情况下,“免费”的意义是不言自明的。
|
|
|
|
|
|
|
|
首要要求一定是负载测试程序能够处理应用程序所使用的功能和协议。
|
|
|
|
|
|
这是负载测试程序最基本、且最重要的功能,它有助于确定哪些是负载测试程序以及哪些不是。
|
|
|
|
|
|
如果不能编辑客户机与服务器之间交互的脚本,那么就不能处理除最简单的客户机之外的任何东西。编辑脚本的能力是最基本的,且小的改变不应该要求重新生成脚本。
|
|
|
|
|
|
如果不支持会话或者cookies,就不算是真正的负载压力测试工具,并且不能对大多数J2EE应用程序进行负载测试。
|
|
|
|
|
|
测试程序应该可以让您指定每个脚本由多少个模拟用户运行,包括让您随时间改变模拟用户的数量,因为许多负载测试可以做到从小的用户数量开始,并慢慢增加到更多的用户数量。
|
|
|
|
|
|
每一个脚本都必须定义一个方法来识别成功的交互以及失败和错误模式(错误一般不会有页面返回,而失败可能在页面上得到错误的数据)。
|
|
|
|
|
|
如果测试工具可以检查一些发送给模拟用户的页面,这会很有用,这样可以做到心中有数,以确保测试工作是正确进行的。
|
|
|
|
|
|
可以用不同的工具来分析测试结果,这些工具包括电子表格和可以处理数据的自定义脚本。虽然许多负载测试工具包括大量的分析功能,但是导出数据的能力使您在以任意的方式分析和编辑数据方面具有更大的灵活性。
|
|
|
|
|
|
真实世界的用户不会在收到一页后立即请求另一页,一般在查看一页和下一页之间会有延迟。考虑时间这个标准术语表示在脚本中加入延迟以更真实地模拟用户行为。大多数负载测试程序支持根据统计分布随机生成考虑时间。
|
|
|
|
|
|
用户一般不会使用同样的一组数据,每位用户通常与服务器进行不同的交互。模拟用户应该也这样做,如果在交互的关键点,脚本可以从一组数据中选择数据,则可以更容易地让您的模拟用户表现出使用不同数据的行为。
|
|
|
|
|
|
相对于编写脚本,用浏览器手工运行会话并记录这个会话,然后再编辑会容易得多。
|
|
|
|
|
|
一些应用程序大量使用JavaScript并且需要模拟客户机支持它。不过,使用客户端JavaScript可能会增加对测试系统上系统资源的需求。
|
|
|
|
|
|
得到测试数据只是成功的一半,另一半是分析性能数据。因此测试工具提供的分析工具越多,就越有利于从不同的方面进行数据分析。
|
|
|
|
|
|
基本负载压力测试工具测量客户机/服务器交互中基于客户机的响应时间。如果同时收集其他统计数据(如CPU使用情况和页面错误率)就更好了,有了这些数据,就可以进一步做一些有用的工作,如查看服务器负载上下文中的客户机响应时间和吞吐量统计。
|
|
|
|
|
|
任何负载压力测试工具都不是完美无缺的,在我们的实际使用中经常碰到一些问题,概括起来主要有以下几点:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在实际压力测试过程中,我们通常使用多种工具达到测试目的,如何配合使用多种工具,是否能达到最好的“性能价格比”?测试工程师要发挥最大的主观能动性。
|
|
|
|
|
|
. QALoad——美国Compuware(康博)公司。
|
|
|
|
|
|
①测试接口。DB2,DCOM, ODBC, ORACLE, NETLoad, Corba, QARun, SAP, SQLServer, Sybase, Telnet, TUXEDO, UNIFACE, WinSock, WWW。
|
|
|
|
②预测系统性能。当应用升级或者新应用部署时,负载测试能帮助确定系统是否能按计划处理用户负载。QALoad并不需调用最终用户及其设备,它能够仿真数以千计的用户进行商业交易。通过QALoad,用户可以预知业务量接近投产后的真实水平时端对端的响应时间,以便满足投产后的服务水平要求。
|
|
|
|
③通过重复测试寻找瓶颈问题。QALoad录制/回放能力提供了一种可重复的方法来验证负载下的应用性能,可以很容易地模拟数千个用户,并执行和运行测试。利用QALoad反复测试可以充分地测试与容量相关的问题,快速确认性能瓶颈并进行优化和调整。
|
|
|
|
④从控制中心管理全局负载测试。QALoad Conductor工具为定义、管理和执行负载测试提供了一个中心控制点。Conductor通过执行测试脚本管理无数的虚拟用户。Conductor可以自动识别网络中可进行负载测试的机器,并在这些机器之间自动分布工作量以避免网段超载。从Conductor自动启动和配置远程用户,跨国机构可以进行全球负载测试。在测试过程中,Conductor还可以在负载测试期间收集有关性能和时间的统计数据。
|
|
|
|
⑤验证应用的可扩展性。出于高可扩展性的设计考虑,QALoad包括了远程存储虚拟用户响应时间,并在测试结束后或其他特定时间下载这些资料的功能。这种方法可以增加测试能力,减少进行大型负载测试时的网络资源耗费。QALoad采用轮询法采集响应时间,在无需影响测试或增加测试投资的条件下,就可了解测试中究竟出现了什么情况。
|
|
|
|
在利用QALoad进行测试时,可以有选择地改变硬件或软件的配置,并改变测试步调和负载量。QALoad系统的NetLoad模块帮助建立所需的额外网络流量来模拟真实的产品负载。借助于“NetLoad”,可以在大环境下分配虚拟用户,更好地规划在投产环境中如何让这些应用更好地工作。
|
|
|
|
QALoad引入了“flash”为电子商务应用软件作容量测试。flash测试允许在测试期间增加大量的虚拟用户,来确定压力对底层部件和基础结构的影响。flash测试也可以证明应用投产后其响应时间将不会降低至服务级以下。
|
|
|
|
⑥快速创建仿真的负载测试。准确仿真复杂业务的进行,对于预测电子商务应用软件的功能至关重要。运用QALoad,可以迅速创造出一些实际的安装测试方案,而不需要手工编写脚本或有关应用中间软件的详细知识和协议。
|
|
|
|
对结合了多种传输协议的应用软件进行负载测试是一个巨大的挑战。为了准确仿真这些应用软件产生的流量,QALoad可以捕获多种协议并在同一测试过程中执行它们。基于浏览器的应用经常打开与服务器的多个连接以缩短网页下载时间,导致服务器的额外流量。QALoad能准确地仿真出浏览器与服务器之间的交互,包括多重连接,使负载更加准确。
|
|
|
|
另外,这些应用软件常常包含一些在测试方案中必须申明的动态信息。运用QALoad的ActiveData特征,可以定义脚本参数,以帮助确保应用测试脚本的成功执行。
|
|
|
|
例如,对一些安全或非安全的Web应用软件,ActiveData自动转化为动态信息,如cookies,包括动态Active Serve Page cookies、动态URL名称、服务器导向、动态框架或者其他时期的特定信息。ActiveData for Web有助于保证测试脚本与Web应用在测试过程中保持同步。
|
|
|
|
ActiveData每次自动查找和提出需要的变更建议,使测试脚本正确执行。在脚本执行过程中,脚本中的信息可以被产生的正确信息自动替代。
|
|
|
|
|
|
这些特点应该是负载压力测试工具普遍具备的特点,在后面的负载压力工具介绍中就不再赘述,而是介绍一些除了这些之外的特点。
|
|
|
|
|
|
|
|
|
|
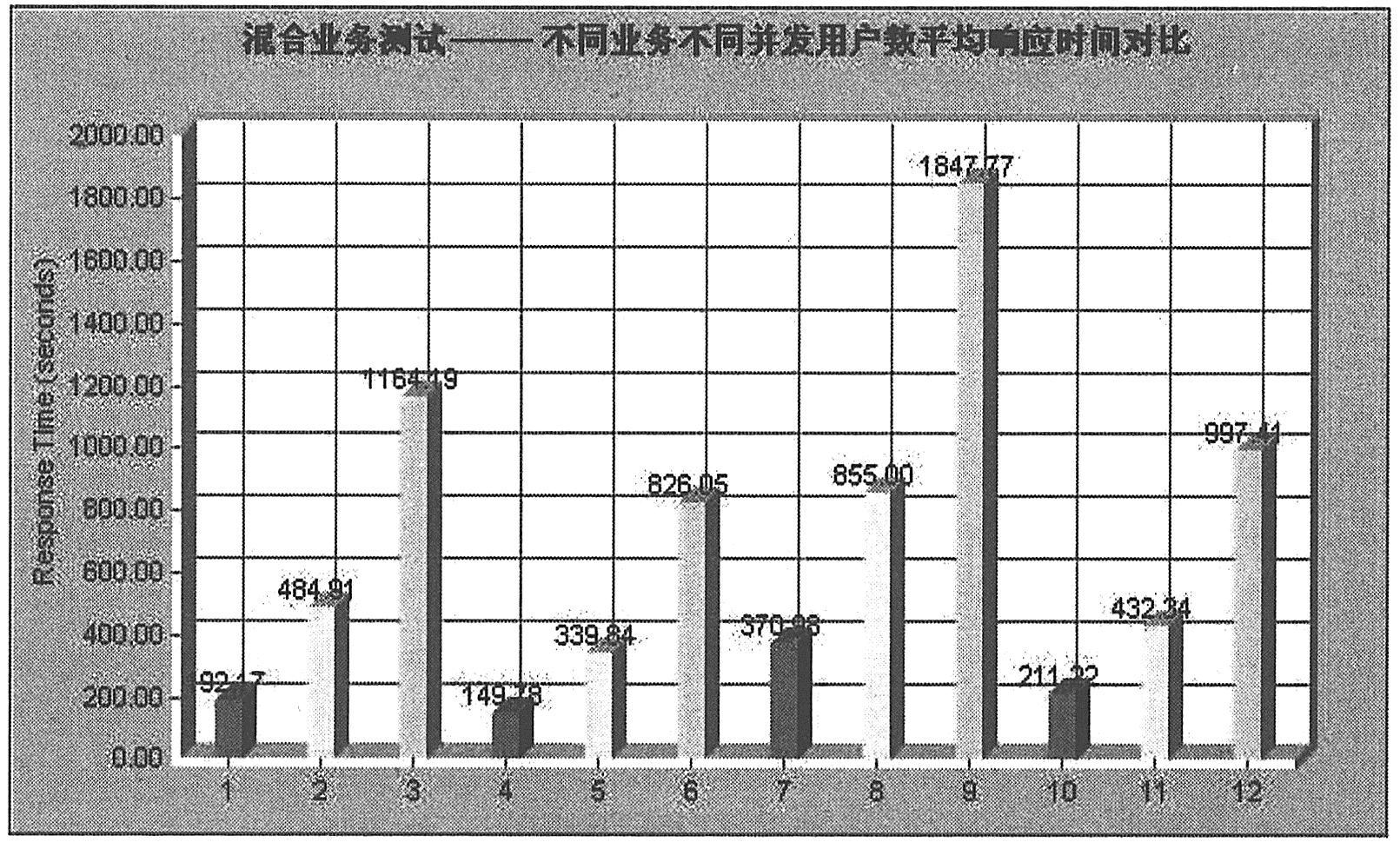
测试结果分析如下图所示,1—2—3表示业务组A,4-5-6表示业务组B,7—8—9表示业务组C,10—11—12表示业务组D,在各个业务组中序号从小到大表示不同的并发用户。
|
|
|
|
|
|
|
|
. LoadRunner——美国Mercury Interactive公司。
|
|
|
|
|
|
①测试接口:支持的协议多且个别协议支持的版本较高;
|
|
|
|
|
|
|
|
④报告可以导出到Word、Excel以及HTML格式。
|
|
|
|
|
|
|
|
. Benchmark Factory——美国Quest软件公司。
|
|
|
|
|
|
|
|
|
|
③可以生成高级脚本,例如脚本中数据池的生成可以采用随机数。
|
|
|
|
|
|
这是一个Microsoft提供的免费的Web负载压力测试工具,应用比较广泛,下面做一个较详细的介绍。
|
|
|
|
WAS可以通过一台或者多台客户机模拟大量用户的活动。WAS支持身份验证、加密和Cookies,也能够模拟各种浏览器类型和Modem速度,它的功能和性能可以与数万美元的产品相媲美。
|
|
|
|
要对网站进行负载测试首先必须创建WAS脚本模拟用户活动。我们可以用下面四种方法之一创建脚本:①通过记录浏览器的活动;②通过导入IIS日志;③通过把WAS指向Web网站的内容;④手工制作。
|
|
|
|
制作WAS脚本是相当简单的,不过要制作出模拟真实用户活动的脚本就有些复杂。如果你已经有一个运行的Web网站,可以使用Web服务器的日志来确定Web网站上的用户点击分布。如果你的应用还没有开始运行,那么只好根据经验作一些猜测了。
|
|
|
|
|
|
①Number of hits:测试间隔内虚拟用户点击页面的总次数;
|
|
|
|
②Requests per second:每秒客户端的请求次数;
|
|
|
|
|
|
④TTFB Avg:从第一个请求发出到测试工具接收到服务器应答数据的第一个字节之间的平均时间;
|
|
|
|
⑤TTLB Avg:从第一个请求发出到测试工具接收到服务器应答数据的最后一个字节之间的平均时间。
|
|
|
|
准备好测试脚本之后,我们可以调整测试配置,以便观察不同条件下的应用性能。如下图所示是WAS的设置界面。
|
|
|
|
|
|
|
|
Stress Level和Stress Multiplier这两项决定了访问服务器的并发连接的数量。如果要模拟的并发连接数量超过100个,可以调整Stress multiplier或使用多个客户机。在负载测试期间WAS将通过DCOM与其他客户机协调。有关在测试中使用多个客户机的更多信息,参见http://webtool.rte.microsoft.com/kb/hkb13.htm。
|
|
|
|
如果网站提供个性化服务,要进行身份验证或使用Cookies,我们还要为WAS提供一个用户目录。WAS中的用户存储了发送给服务器的密码以及服务器发送给客户端的Cookies。增加用户数量并不增加Web服务器的负载。必须提供足够数量的用户以满足并发连接的要求(Stress Level乘以Stress Multiplier)。有关线程、用户和Cookies相互作用的更多信息请参见http://webtool.rte.microsoft.com/Threads/WASThreads.htm。
|
|
|
|
WAS允许设置warmup(热身)时间,一般可以设置为1分钟。在warmup期间WAS开始执行脚本,但不收集统计数据。warmup时间给MTS、数据库以及磁盘缓冲等一个机会来做准备工作。如果在warmup时间内收集统计数据,这些操作的开销将影响性能测试结果。
|
|
|
|
设置页面提供的另外一个有用的功能是限制带宽(throttle bandwidth)。带宽限制功能能够为测试模拟出Modem(14.4K, 28.8K, 56K)、ISDN(64K,128K)以及T1(1.54M)的速度。使用带宽限制功能可以精确地预测出客户通过拨号网络或其他外部连接访问Web服务器所感受的性能。
|
|
|
|
要理解这些不同的设置对应用的影响,有必要了解如何使用WAS收集性能数据。
|
|
|
|
使用WAS,从远程Windows NT和Windows 2000机器获取和分析性能计数器(Performance Counter)是很方便的。加入计数器要用到如下图所示的Perf Counters分支。
|
|
|
|
|
|
|
|
在测试中选择哪些计数器显然跟测试目的有关。虽然下面这个清单不可能精确地隔离出性能瓶颈所在,但对一般的Web服务器性能测试来说却是一个好的开始。
|
|
|
|
①处理器:CPU使用百分比(% CPU Utilization);
|
|
|
|
②线程:每秒的上下文切换次数(Context Switches Per Second(Total));
|
|
|
|
③ASP:每秒请求数量(Requests Per Second);
|
|
|
|
④ASP:请求执行时间(Request Execution Time);
|
|
|
|
⑤ASP:请求等待时间(Request Wait Time);
|
|
|
|
⑥ASP:置入队列的请求数量(Requests Queued)。
|
|
|
|
CPU使用百分比反映了处理器开销。CPU使用百分比持续地超过75%是性能瓶颈存在于处理器的一个明显的迹象。每秒上下文切换次数指示了处理器的工作效率。如果处理器陷于每秒数千次的上下文切换,说明它忙于切换线程而不是处理ASP脚本。
|
|
|
|
每秒的ASP请求数量、执行时间以及等待时间在各种测试情形下都是非常重要的监测项目。每秒的请求数量表示每秒内服务器成功处理的ASP请求数量。执行时间和等待时间之和显示了反应时间,这是服务器用处理好的页面作应答所需要的时间。
|
|
|
|
可以绘出随测试中并发用户数量的增加,每秒请求数量和反应时间的变化图。增加并发用户数量时每秒请求数量也会增加。然而,我们最终会达到这样一个点,此时并发用户数量开始“压倒”服务器。如果继续增加并发用户数量,每秒请求数量开始下降,而反应时间则会增加。要搞清楚硬件和软件的能力,找出这个并发用户数量开始“压倒”服务器的临界点非常重要。
|
|
|
|
置入队列的ASP请求数量也是一个重要的指标。如果在测试中这个数量有波动,某个COM对象所接收到的请求数量超过了它的处理能力。这可能是因为在应用的中间层使用了一个低效率的组件,或者在ASP会话对象中存储了一个单线程的单元组件。
|
|
|
|
运行WAS的客户机CPU使用率也有必要监视。如果这些机器上的CPU使用率持续地超过75%,说明客户机没有足够的资源来正确地运行测试,此时应该认为测试结果不可信。在这种情况下,测试客户机的数量必须增加,或者减小测试的Stress Level。
|
|
|
|
每次测试运行结束后WAS会生成详细的报表,即使测试被提前停止也一样。WAS报表可以从View菜单选择Reports查看。下面介绍一下报表中几个重要的部分。
|
|
|
|
如果这是一个新创建的测试脚本,你应该检查一下报表的Result Codes部分。这部分内容包含了请求结果代码、说明以及服务器返回的结果代码的数量。如果这里出现了404代码(页面没有找到),说明在脚本中有错误的页面请求。
|
|
|
|
页面摘要部分提供了页面的名字,接收到第一个字节的平均时间(TTFB),接收到最后一个字节的平均时间(TTLB),以及测试脚本中各个页面的命中次数。TTFB和TTLB这两个值对于计算客户端所看到的服务器性能具有重要意义。TTFB反映了从发出页面请求到接收到应答数据第一个字节的时间总和(以毫秒计),TTLB包含了TTFB,它是客户机接收到页面最后一个字节所需要的累计时间。
|
|
|
|
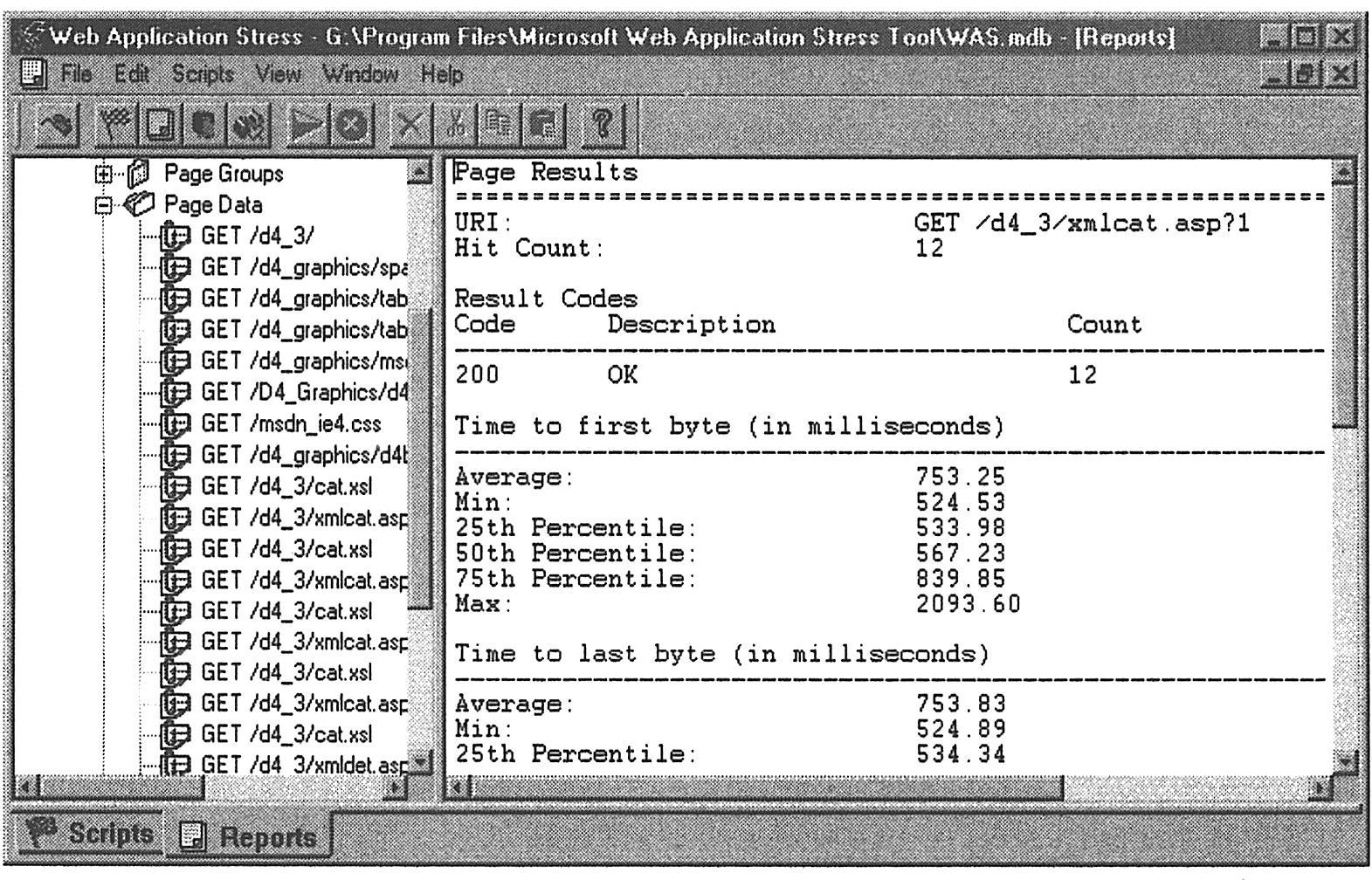
报表中还包含了所有性能计数器的信息。这些数据显示了运行时各个项目的测量值,同时还提供了最大值、最小值、平均值等。报表实际提供的信息远远超过了我们这里能够介绍的内容。为了给你一个有关报表所提供信息种类的印象,摘录了一个报表实例如下图所示。
|
|
|
|
|
|
|
|
. SILK PERFORMER V——美国Segue公司。
|
|
|
|
|
|
|
|
②脚本采用PASCAL,资源消耗较小,支持一些底层访问。
|
|
|
|
|
|
|
|
|
|
协议这个概念大家并不陌生,测试工具中的“协议”指的是工具提供给我们的测试接口,也可以理解为测试类型。LoadRunner提供的测试协议比较全面,例如:
|
|
|
|
|
|
. Client/Server:MS SQL, ODBC, Oracle(2-tier), DB2 CLI, Sybase Ctlib, Sybase Dblib, Windows Sockets及DNS。
|
|
|
|
. 定制:C templates, Visual Basic templates, Java templates, JavaScript及VBScript。
|
|
|
|
. 分布式组件:COM/DCOM, Corba-Java及Rmi-Java。
|
|
|
|
. E-business: FTP, LDAP, Palm, SOAP, Web (HTTP/HTML),及the dual Web/Winsocket。
|
|
|
|
. Enterprise Java Beans:EJB Testing及Rmi-Java。
|
|
|
|
. ERP/CRM:Baan, Oracle NCA, Peoplesoft-Tuxedo, Peoplesoft 8 Web multilingual, SAPGUI, SAP-Web, Siebel (Siebel-DB2CLI, Siebel-MSSQL, Siebel-Web及Siebel-Oracle)。
|
|
|
|
. Legacy:Terminal Emulation (RTE)。
|
|
|
|
. Mailing Services: Internet Messaging (IMAP), MS Exchange (MAPI), POP3及SMTP。
|
|
|
|
. Middleware: Jacada及Tuxedo (6, 7)。
|
|
|
|
. Streaming: MediaPlayer及RealPlayer。
|
|
|
|
. Wireless: i-Mode, VoiceXML及WAP。
|
|
|
|
这里我们要重点讨论的问题是选择测试协议的策略。一个原则性的观点是“客户端与直接压力承受的服务器之间的通信协议是选择测试协议的惟一标准”。例如,有的测试工程师问“我们的系统是B/S运行模式,应该选择什么样的测试协议来测”,我们说这是一个无效问题,为什么呢?从这个问题中我们不能获取任何与通信协议有关的信息,B/S运行模式可以采用http协议,也可以采用TCP/IP, SMTP、FTP等协议,C/S运行模式也是这个道理。选择不同的协议决定了测试的成功与失败。理论知识要适用于实践,必须活学活用。再例如,一个使用非常普遍的系统:B/S运行模式,前端IE浏览器,IE浏览器直接与Web服务器通信(可能多台),Web服务器与后台数据库服务器(可能多台)有数据交互操作,IE浏览器与Web服务器的通信协议采用http,那么,理所当然我们选择的测试协议是http;再灵活一些,如果IE浏览器与Web服务器的通信不仅采用了http协议,而且还有部分业务采用Winsocket,那么必须选择Web/Winsocket双协议;更进一步,有些系统客户端是C/S运行模式和B/S运行模式的混合,为了达到测试目的,就要选择更多的测试协议。可喜的是LoadRunner 7.8版本以后已经能够帮你实现这个愿望了。再来看一种情况:系统的架构是客户端应用程序+Tuxedo消息中间件(或者是其他中间件)+数据库服务器。遇到这种情况,我们一般会选择Tuxedo测试协议,能够有这样的定位选择,BEA公司的产品Tuxedo的市场占有率给测试工具厂商带来的压力显而易见。还要跟大家介绍一种普遍认为最“惨”,也最“酷”的方法,就是利用测试工具提供的编程语言自己编写测试脚本,测试工具提供的使用广泛的测试脚本是CScript、JavaScript及VBScript。但提醒大家的是,要做到真实模拟负载,和相关开发人员的交流至关重要。
|
|
|
|
|
|
|
|
实施负载压力测试时,需要运行系统相关业务,这时需要一些数据支持才可运行业务,这部分数据即为初始测试数据。例如ERP软件运行前财务账套的准备。
|
|
|
|
在初始的测试环境中需要输入一些适当的测试数据,目的是识别数据状态并且验证用于测试的测试案例。在正式的测试开始以前对测试案例进行调试,将正式测试开始时的错误降到最低。在测试进行到关键过程领域时,非常有必要进行数据状态的备份。制造初始数据意味着将合适的数据存储下来,需要的时候恢复它,初始数据提供了一个基线用来评估测试执行的结果。
|
|
|
|
对系统实施负载压力测试的时候,经常会需要准备大数据量、实施独立的测试,或者与并发负载压力相结合的性能测试,这部分数据为业务测试数据。例如飞机订票系统查询订票信息,就需要准备大量的订票记录。又比如测试并发查询业务,那么要求对应的数据库和表中有相当的数据量,以及数据的种类应能覆盖全部业务。
|
|
|
|
在负载压力测试过程中,为了模拟不同的虚拟用户的真实负载,需要将一部分业务数据参数化,这部分数据为参数化测试数据。例如模拟不同用户登录系统,就需要准备大量用户名及相应密码参数数据。
|
|
|
|
还需要考虑特殊系统需要的测试数据,模拟真实环境测试,有些软件特别是面向大众的商品化软件,在测试时常常需要考察在真实环境中的表现。如测试杀毒软件的扫描速度时,硬盘上布置的不同类型文件的比例要尽量接近真实环境,这样测试出来的数据才有实际意义。
|
|
|
|
|
|
|
|
|
|
|
|
. 初始数据提供了一个基线用来评估测试执行的结果;
|
|
|
|
|
|
|
|
|
|
在8.2.3小节,介绍了依靠工具准备测试数据的方法。
|
|
|
|
|
|
下面通过列举两个实例,来了解自己动手编写测试工具的思路。
|
|
|
|
|
|
这个系统不仅能够测试静态HTML页面的响应时间,而且能够模拟真实运行情况测试动态网页(包括ASP、PHP、JSP等)的响应时间,为服务器的性能优化和调整提供数据依据。
|
|
|
|
为了能够模拟大量用户同时访问Web动态页面的情况,必须要解决下面两个问题:
|
|
|
|
. 测试工具需要模拟出大量用户同时访问Web的情况;
|
|
|
|
. 测试工具需要模拟出单个用户访问Web时个性化的请求参数。
|
|
|
|
本性能测试系统主要由两部分构成:性能测试数据文件和性能测试程序。其中,性能测试数据文件包含着用户访问Web的URL请求格式和大量用户访问系统的请求数据(例如用户名和密码等)。实际测试中,性能测试程序将开设多个进程模拟大量用户对Web的访问,每个进程从性能测试数据文件中随机地读出一组访问数据,然后发起对Web服务器的访问,等待Web服务器应答。测试结束后,性能测试程序将给出对于所有请求的平均系统响应时间。由此,本性能测试工具能够真实地模拟大量用户同时访问Web的情况。
|
|
|
|
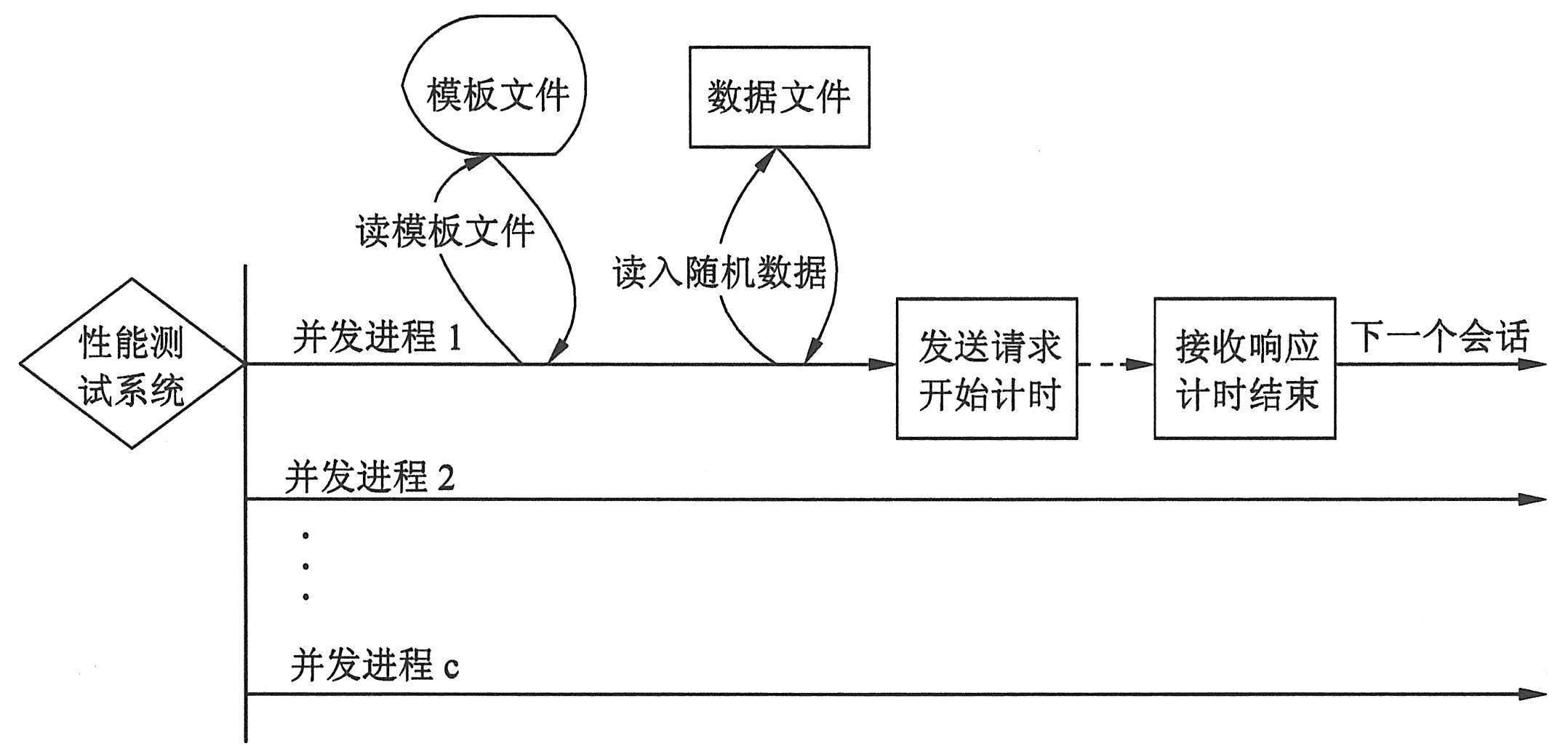
在实际运行的Web应用系统中,用户访问动态页面时传递的query字符串中的参数是互不相同的。为了逼真地模拟实际情况,性能测试系统应该在一段特定的时间内,对待测页面同时发送多个请求,每个请求的query参数互不相同,在发送的同时开始计时,直到收到系统的响应,计时停止,最后对所有请求的响应时间进行分析,就可以得到系统性能的定量估计。系统结构如下图所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
模板文件为纯文本文件,包含单个用户访问Web发送的URL,每行格式如下:
|
|
|
|
GET(POST)http://host:port/path/filename?xxx=@1@&@2@
|
|
|
|
其中GET或者POST表示参数传递的方式,query字符串中的@是本系统特设字符,表示@及其后面的数字需要被数据文件中对应的参数数据所取代。两个@之间为参数序号,只能为数字,在整个模板文件中相同的参数序号代表相同的参数。
|
|
|
|
数据文件是用户访问动态页面时传递的query参数集合,为纯文本文件,参数数据与模板文件中@号及其后面的数字相对应,之间用空格隔开,每组一行。
|
|
|
|
测试Web应用系统时,性能测试程序将开设c个进程,每个进程可以串行地开设n个会话,每个会话模拟一个真实用户,按照模板文件中提供的访问Web系统的格式,从数据文件中读取一组query参数,然后对Web系统发起请求;与此同时,程序开始计时,直到收到系统的响应,计时停止,系统统计接收的字节数,将结果写入结果文件,本次会话结束,这个进程开始一个新的会话,如此循环n次。测试结束后,结果处理程序对结果文件中每个请求的响应时间进行统计分析,给出系统的综合性能评估。
|
|
|
|
从上面的分析可以看出,本系统发送请求的并发度是c,即在测试的时间段内,对Web应用系统同时发送的请求有c个;本系统发送请求的串行度为n,一共可以模拟c×n个用户对系统的访问。
|
|
|
|
|
|
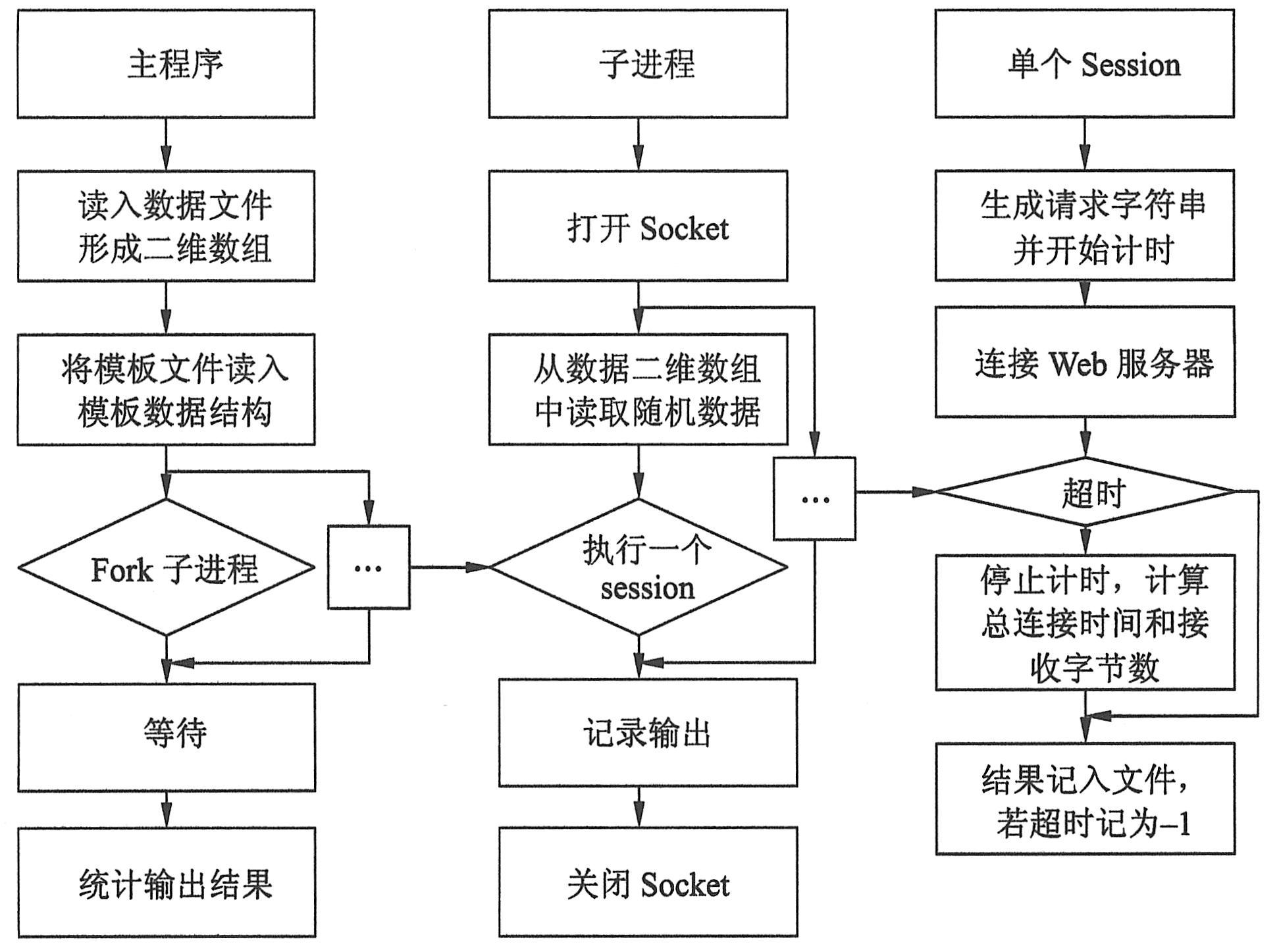
如下图所示,性能测试程序fork出c个进程,每个进程都开设一个Socket,通过Socket向Web服务器发送请求。为了使测试程序能够快速地向服务器发送请求,程序一开始就将数据文件中的所有数据读入内存,数据使用一个二维数组存放。
|
|
|
|
|
|
|
|
模板文件中的请求格式在程序开始时读入模板数据结构中,模板数据结构定义如下:
|
|
|
|
|
|
测试程序运行结束后,生成的结果文件包含着Web服务器对每个请求的响应时间,还包含每个请求返回的字节数。结果文件由结果处理程序处理,计算出Web服务器对所有请求的平均响应时间。
|
|
|
|
|
|
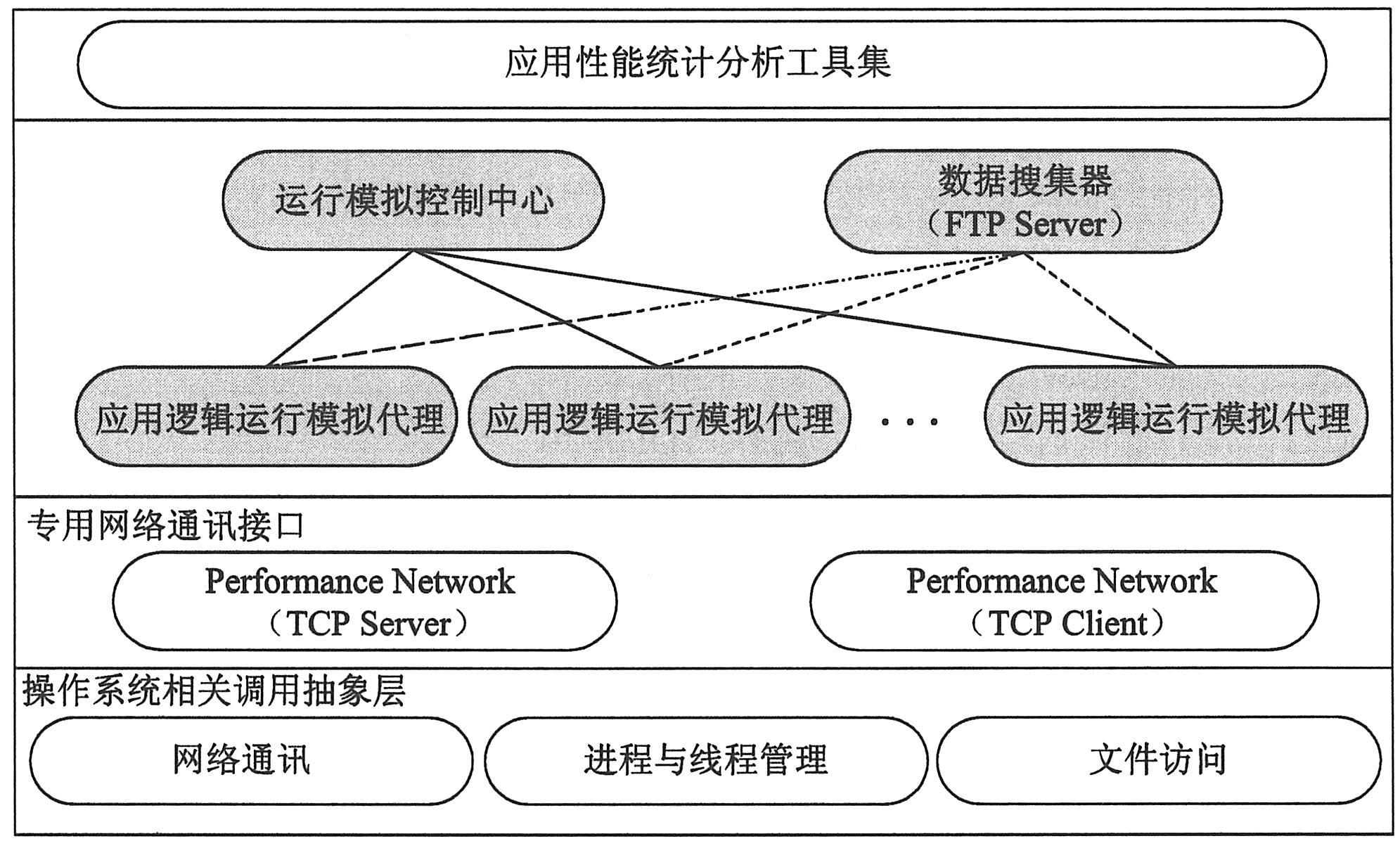
大家知道LoadRunner通过运行脚本模拟的方法仍然与应用系统的实际处理逻辑存在一定的差异,因此其评测结果与应用系统实际使用过程中的性能指标之间仍然存在一定的差距。为了弥补这个缺陷,需要一种适用于特定应用的运行模拟和性能评测方法与支撑环境,来对应用系统的实际性能评测提供有效支持。这里提出的通用应用系统性能评测环境,是通过并行执行分布于不同客户机上的多种类型的实际应用程序代码,模拟一个应用系统在多个客户端并发访问情况下的实际运行情况,同时对应用程序代码的执行状态和结果等信息进行记录;在模拟执行完成之后,对执行记录进行分析,给出被测系统的性能指标。应用系统性能评测环境主要由应用逻辑运行模拟代理(PexpAgent)、模拟控制中心(PexpCmdCenter)、数据搜集器(Data Collector)和统计分析工具等部分组成,其系统结构如下图所示。其中,应用逻辑运行模拟代理负责驱动执行被测系统的应用逻辑代码,并记录每一次执行的状态和性能相关信息。模拟控制中心负责控制整个性能评测过程中的所有运行模拟代理。数据搜集器负责在测量完成之后,接收来自运行模拟代理的性能测量数据。统计分析工具负责对测量获得的性能相关数据进行分析,从而得出被测系统的相关性能数据。在评测过程中,运行模拟代理与控制中心之间通过基于对象传输的专用网络通信接口(Performance Network)进行通信;由于应用系统的实际运行环境各异,评测系统被设计成能够运行在多种操作系统平台上,所有其他组件的下层是操作系统相关调用抽象层,对于不同的操作系统平台,需要实现相应的实际处理对象。
|
|
|
|
|
|
|
|
由于我们的目的是通过模拟真实的并发环境来获取系统的实际性能,在设计与实现上需要充分考虑如下问题,并加以解决:
|
|
|
|
. 应用系统实际处理代码的嵌入方式和响应时间的测定;
|
|
|
|
|
|
|
|
|
|
|
|
做为第三方测试机构,在负载压力测试准备的过程中,经常需要与用户交流,那么交流哪些内容呢?概括如下。
|
|
|
|
|
|
. 系统运行的硬件环境和软件环境,包括客户端、中间件、Web服务器、应用服务器、数据库服务器等;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
测试脚本指Vuser脚本,即虚拟用户回放所使用的脚本。脚本的产生可以采用录制、编写或者录制加编写混合模式,初始生成的脚本经过增强编辑之后,必需再经调试才可用。
|
|
|
|
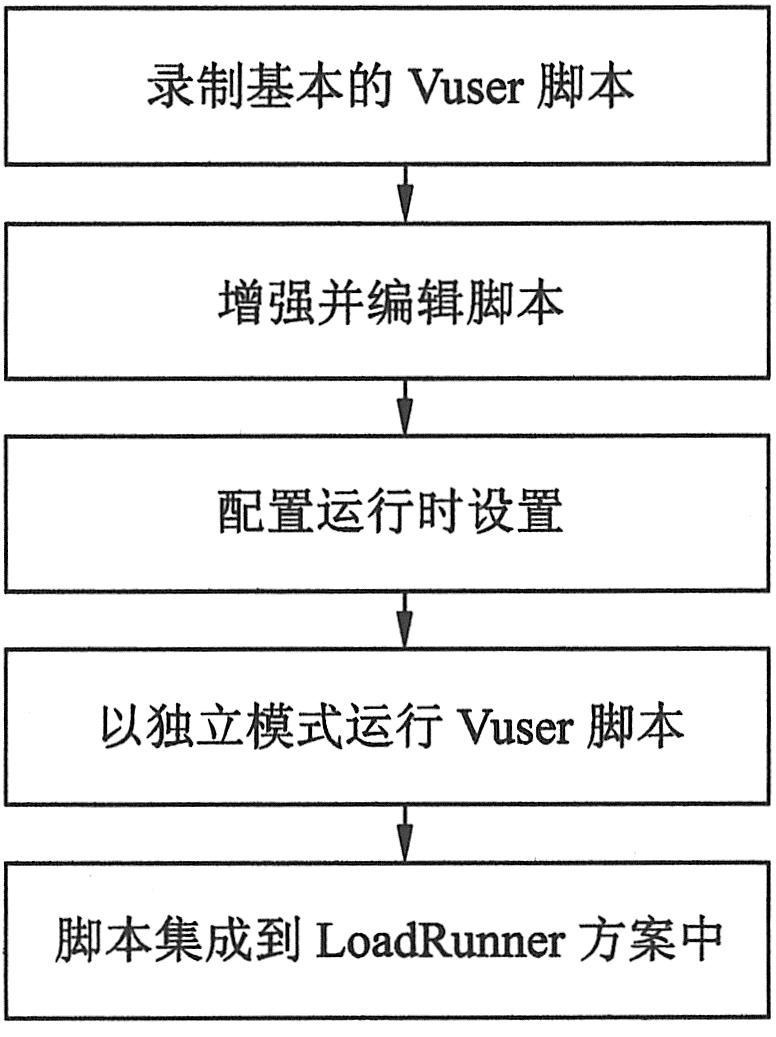
Vuser脚本的结构和内容因Vuser类型的不同而不同。例如,数据库Vuser脚本总是包含三部分,是在一段类似C语言并且包括对数据库服务器的SQL调用的代码中编写的。相反,GUI Vuser脚本只有一个部分,并且是用TSL(测试脚本语言)编写的。下图概述了开发Vuser脚本的过程。
|
|
|
|
|
|
|
|
首先,来了解录制脚本。在一般的测试过程中,录制脚本所占比例较大,测试工具提供了大量录制Vuser脚本的工具,并且可以通过将控制流结构和其他测试工具的API添加到脚本中来增强该基本脚本。然后,配置运行时设置。运行时设置包括迭代、日志和计时信息以及定义Vuser在执行Vuser脚本时的行为。要验证脚本是否能正确运行,请以单独模式运行该脚本。如果脚本运行正确,则将其合并到方案中。
|
|
|
|
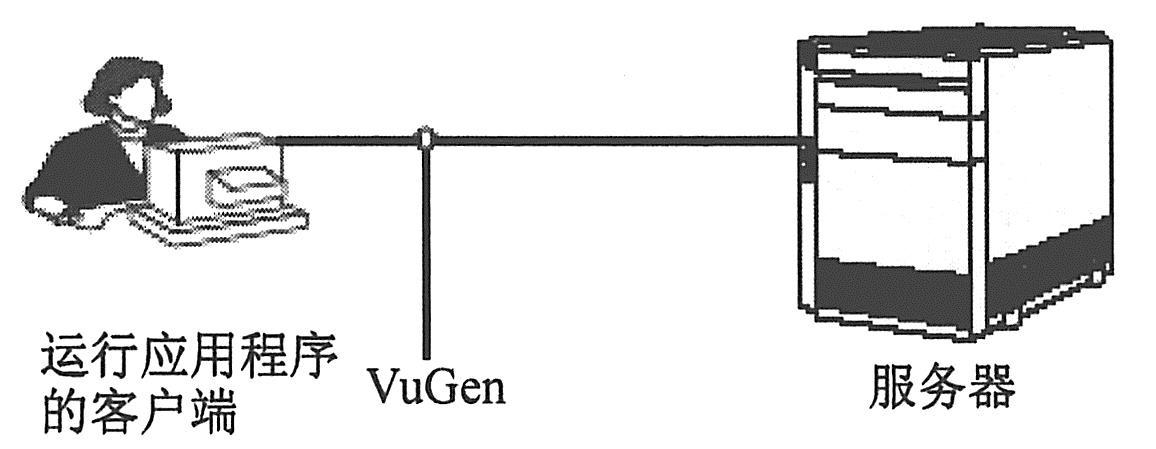
那么,录制哪些内容呢?主要录制用户在客户端应用程序中执行的典型业务流程。测试工具通过录制客户端和服务器之间的活动来创建脚本。例如,在数据库应用程序中,测试工具的脚本生成器(VuGen)会监控数据库的客户端,并跟踪发送到数据库服务器和从数据库服务器接收的所有请求。如下图所示为录制活动创建脚本。
|
|
|
|
|
|
|
|
用VuGen创建的每个Vuser脚本都可以通过执行对服务器API的调用来直接与服务器通信,而不需要依赖客户端软件。这样,便可以使用Vuser来检查服务器性能(甚至在客户端软件的用户界面完全开发好之前)。如下图所示为API调用生成脚本。
|
|
|
|
|
|
|
|
此外,当Vuser与服务器直接通信时,不需要在用户界面中耗费系统资源。这样就可以在一个工作站中同时运行大量Vuser,进而可以使用很少的测试计算机来模拟非常大的服务器负载。
|
|
|
|
测试工具都留有手工编写脚本的入口,例如C script、Java script、VB以及汇编语言等,并且提供相应测试类型的API,测试人员在此环境下可以编程生成脚本。
|
|
|
|
脚本的调试也是非常重要的工作,例如我们要调试C/S脚本,那么应该注意些什么呢?
|
|
|
|
对于C/S结构的脚本,在数据量大时,脚本非常庞大,如果全部看一遍,根本是不可能的。对于这种脚本的调试,应注意以下几个方面。
|
|
|
|
|
|
我们经常会碰到某个表单的编号是记录在另一个表中的,程序通过查询这个表,并加1来获取到这个编号。对于这种问题,可以分解为以下3步(以ORACLE数据库为例)。
|
|
|
|
①获取数据,可使用lrd_ora8_save_col函数。
|
|
|
|
②函数值加1处理,可使用lr_param_increment函数。
|
|
|
|
③替换处理,即把Update中的具体值替换为我们获取并处理好的参数就可以了。
|
|
|
|
|
|
这一过程,我们所关注的,不过是Insert及Update语句。将这些语句中违反数据库约束的地方进行参数化就可以了。而且仅关注这些语句,基本上就可以搞清楚整个程序的处理流程。理清关系,作参数时直接Replace All(录制脚本时注意使用的数据最好有特点,这样替换过程中就不会把不该替换的也替换了)就可以了。
|
|
|
|
|
|
|
|
方案由Vuser组构成,Vuser模拟与应用程序进行交互的实际用户。运行方案时,Vuser会在服务器上生成负载,测试工具会监视服务器和事务性能。Vuser组用于将方案中的Vuser组织成可管理的组。可以创建包含具有共享或相似特征的Vuser的Vuser组。例如,可以为运行相同Vuser脚本的所有Vuser创建Vuser组。
|
|
|
|
|
|
可以为定义的Vuser组中的各个Vuser定义属性。对于每个Vuser,可以分配不同的脚本和负载生成器计算机。
|
|
|
|
|
|
可以设置脚本的运行时设置,采用在控制中心自定义执行Vuser脚本的方式。
|
|
|
|
|
|
在测试执行之前,需要配置方案的负载生成器和Vuser行为,即制定场景。虽然默认设置与大多数环境对应,但是LoadRunner允许修改这些设置以便自定义方案行为。这些设置适用于所有未来的方案运行并且通常只需设置一次。这一类设置适用于方案中所有的负载生成器。如果全局方案设置与单个负载生成器的设置不同,则负载生成器设置将替代它们。
|
|
|
|
可以指出哪些负载生成器将在方案中运行Vuser。例如,如果某个负载生成器不适用于特定方案,可以暂时排除此负载生成器。如果要隔离特定计算机以测试其性能,则禁用负载生成器相当有用。
|
|
|
|
可以为各个负载生成器配置附加设置。可以配置的设置有:状态、运行时文件存储、UNIX环境、运行时配额、Vuser状态、Vuser限制、连接日志(专家模式)、防火墙和WAN仿真。
|
|
|
|
|
|
可以使用终端服务管理器,来远程管理在终端服务器上的、负载测试方案中运行的多个负载管理器。此外,可以使用终端服务器克服只能在基于Windows的负载生成器上运行单个GUI Vuser的局限性。通过为每个GUI Vuser打开一个终端服务器会话,可以在同一应用程序上运行多个GUI Vuser。
|
|
|
|
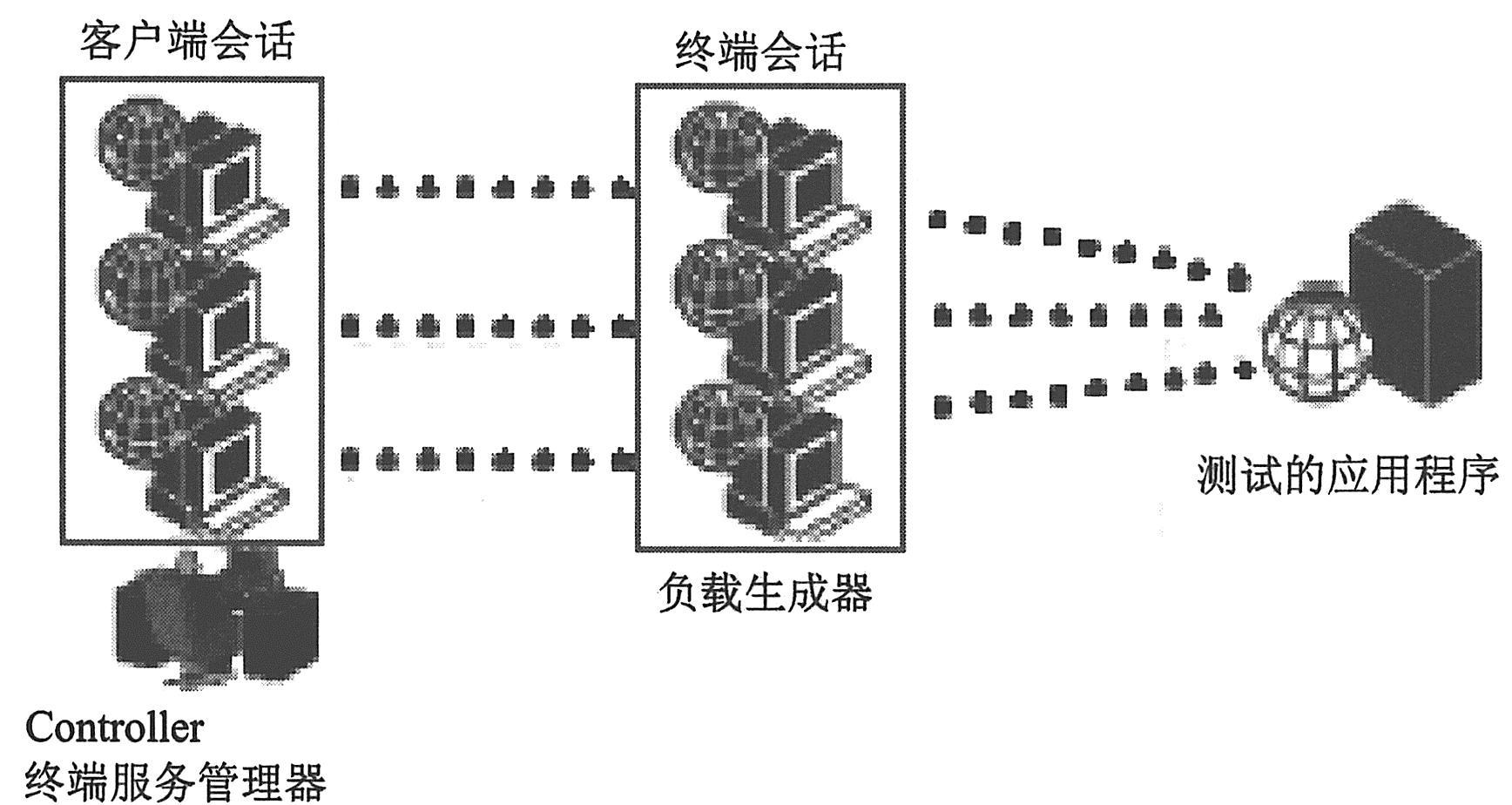
使用终端服务,可以集中管理连接到服务器的每个客户端的计算资源,并为每名用户提供他们自己的工作环境。使用终端服务器客户端,可以通过远程计算机在基于服务器的计算环境中操作。终端服务器通过网络传送应用程序,并通过终端仿真软件显示它们。每个用户会登录并只会看到他们各自的会话,服务器操作系统以透明的方式将该会话独立于其他任何客户端会话进行管理。检查如下图所示的测试工具组件协同工作可以了解测试工具组件在终端会话期间如何协同工作。下图为测试工具组件协同工作不意。
|
|
|
|
|
|
|
|
终端服务器客户端可以同时运行多个终端会话。使用终端服务管理器,可以选择要在方案中使用的终端数量(如果有足够的终端会话在运行)以及每个终端可以运行的最大Vuser数。这样,终端服务管理器便可以在客户端会话间均匀地分配虚拟用户的数量。使用终端服务管理器可以做到以下几点。
|
|
|
|
|
|
|
|
. 使用终端服务管理器在终端服务器上分配Vuser。
|
|
|
|
|
|
可以使用Shunra WAN仿真器在负载测试方案中模拟各种网络基础结构的行为。使用WAN仿真,可以在部署前模拟并测试广域网(WAN)对最终用户响应时间和性能的影响。
|
|
|
|
使用WAN仿真,可以在测试环境中准确地测试实际网络条件下WAN部署产品的点到点的性能。通过引入极为可能发生的WAN影响(如局域网中的滞后时间、包丢失、链路故障和动态路由等影响),可以描绘WAN云图的许多特征,并在单一网络环境中有效地控制仿真。可以在WAN仿真监视报告中观察仿真设置对网络性能的影响。
|
|
|
|
|
|
为Vuser或Vuser组选择了脚本后,可以编辑脚本或查看所选脚本的详细信息。
|
|
|
|
|
|
|
|
运行场景时,会为Vuser组分配负载生成器并执行它们的Vuser脚本。在场景执行期间,将要完成以下工作:
|
|
|
|
|
|
|
|
|
|
可以在无人干预的情况下运行整个场景,或者可以交互地选择要运行的Vuser组和Vuser。场景开始运行时,Controller会首先检查场景配置信息。接着,它将调用已选定与该场景一起运行的应用程序。然后,它会将每个Vuser脚本分配给其指定的负载生成器。Vuser组就绪后,它们将开始执行其脚本。
|
|
|
|
在场景运行时,可以监视每个Vuser,查看由Vuser生成的错误、警告和通知消息以及停止Vuser组和各个Vuser。可以允许单个Vuser或组中的Vuser在停止前完成它们正在运行的迭代,在停止前完成它们正在运行的操作或者立即停止运行,还可以在场景运行时激活其他Vuser。在下面情况下,场景将结束:所有Vuser已完成其脚本、持续时间用完或者终止场景。以下过程概述如何运行场景。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. 在Controller负载生成器计算机中,可以查看输出窗口,联机监视Vuser性能以及查看执行场景的Vuser的状态;.在远程计算机中,可以查看包含活动Vuser的有关信息的代理摘要。
|
|
|
|
|
|
|
|
. “运行时”监视器显示参与场景的Vuser的数目和状态,以及Vuser所生成的错误数量和类型。此外还提供用户定义的数据点图,其中显示Vuser脚本中的用户定义点的实时值。
|
|
|
|
. “事务”监视器显示场景执行期间的事务速率和响应时间。
|
|
|
|
. “Web资源”监视器用于度量场景运行期间Web服务器上的统计信息。它提供关于场景运行期间的Web连接、吞吐量、HTTP响应、服务器重试和下载页的数据。
|
|
|
|
. “系统资源”监视器测量场景运行期间使用的Windows、UNIX、TUXEDO、SNMP和Antara FlameThrower资源。要激活系统资源监视器,必须在运行场景之前设置监视器选项。
|
|
|
|
. “网络延迟”监视器显示关于系统上的网络延迟的信息。要激活网络延迟监视器,必须在运行场景之前设置要监视的网络路径。
|
|
|
|
. “防火墙”监视器用于度量场景运行期间防火墙服务器上的统计信息。要激活防火墙监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “Web服务器资源”监视器用于度量场景运行期间Apache、Microsoft IIS、iPlanet(SNMP)和iPlanet/Netscape Web服务器上的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “Web应用程序服务器资源”监视器用于度量场景运行期间Web应用程序服务器上的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “数据库服务器资源”监视器用于度量与SQL Server、Oracle、Sybase和DB2数据库有关的统计信息。要激活该监视器,必须在运行场景之前设置要监视的度量列表。
|
|
|
|
. “流媒体”监视器用于度量Windows Media服务器、RealPlayer音频/视频服务器及RealPlayer客户端上的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “ERP/CRM服务器资源”监视器用于度量场景运行期间SAP R/3系统服务器、SAP Portal、Siebel Web服务器和Siebel Server Manager服务器的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “Java性能”监视器用于度量Java 2 Platform, Enterprise Edition(J2EE)对象及使用J2EE和EJB服务器计算机的Enterprise Java Bean(EJB)对象的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. “应用程序部署解决场景”监视器用于度量场景运行期间Citrix MetaFrame XP和1.8服务器的统计信息。要激活该监视器,必须在运行场景之前设置监视器选项。
|
|
|
|
. “中间件性能”监视器用于度量场景运行期间TUXEDO和IBM WebSphere MQ服务器上的统计信息。要激活该监视器,必须在运行场景之前设置要监视的资源列表。
|
|
|
|
. 所有的监视器所收集的数据都可以生成该监视器的图。
|
|
|
|
|
|
在负载测试运行过程中,远程性能监视器可以查看特定的图,这些图显示Vuser在服务器上生成的负载的信息。用户在连接到Web服务器的Web浏览器上查看负载测试数据。如下图所示为利用远程性能监视器查看负载测试数据。
|
|
|
|
|
|
|
|
远程性能监视器服务器包含一个用ASP页实现的网站,以及一个包含负载测试图的文件服务器。它与Controller联机组件进行交互,并按相应的许可证处理同时查看负载测试的用户数。
|
|
|
|
|
|
在场景执行期间,Vuser会在执行事务的同时生成结果数据。要在测试执行期间监视场景性能,可以使用联机监视工具。要查看测试执行之后的结果摘要,可以使用下列一个或多个工具。
|
|
|
|
. “Vuser日志文件”包含对每个Vuser运行的场景的完整跟踪。这些文件位于方案结果目录中(在以独立模式运行Vuser脚本时,这些文件放在Vuser脚本目录中)。
|
|
|
|
. “Controller输出”窗口显示有关场景运行的信息。如果场景运行失败,可以在该窗口中查找调试信息。
|
|
|
|
. “Analysis图”有助于确定系统性能并提供有关事务和Vuser的信息。通过合并几个场景的结果或者将几个图合并成一个图,可以对多个图进行比较。
|
|
|
|
. “图数据”视图和“原始数据”视图以电子表格格式显示用于生成图的实际数据。可以将这些数据复制到外部电子表格应用程序,以进行进一步处理。
|
|
|
|
. “报告”实用程序允许查看每个图的摘要HTML报告或各种性能和活动报告。可以将报告创建成Microsoft Word文档,它会自动以图形或表格形式总结和显示测试的重要数据。
|
|
|
|
工具的结果分析功能是有限的,要定位问题测试,工程师的经验和智慧应该起到很大的作用。如何定位问题,“测试实例”部分有案例介绍。
|
|
|
|
|
|
|
|
|
|
|
|
并发用户数是负载压力测试的主要指标,体现了系统能够承受的并发性能。
|
|
|
|
测试重点得到两类并发用户数指标,一类是系统最佳性能的并发用户数,另一类是系统能够承受的最大并发用户数,这两类指标在某种情况下有可能重叠。
|
|
|
|
|
|
该指标描述交易执行的快慢程度,这是用户最直接感受到的系统性能,也是故障定位迫切需要解决的问题。
|
|
|
|
|
|
指每秒钟能够成功执行的交易数,描述系统能够提供的“产量”,用户可以以此来评估系统的性能价格比。
|
|
|
|
|
|
指每秒通过的字节数,以及通过的总字节数。此指标在很大程度上影响系统交易的响应时间,形成响应时间的“拐点”。
|
|
|
|
|
|
|
|
|
|
资源占用主要涉及服务器操作系统资源占用、数据库资源占用、中间件资源占用等内容,下面分别论述。
|
|
|
|
|
|
通过《负载压力测试指标》章节的讨论,可以将服务器操作系统资源占用监控指标概括为以下几个方面:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. Memory:内存使用情况可能是系统性能中最重要的因素。如果系统“页交换”频繁,说明内存不足。“页交换”是使用称为“页面”的单位,将固定大小的代码和数据块从RAM移动到磁盘的过程,其目的是为了释放内存空间。尽管某些页交换使Windows 2000能够使用比实际更多的内存,也是可以接受的,但频繁的页交换将降低系统性能。减少页交换将显著提高系统响应速度。要监视内存不足的状况,请从以下的对象计数器开始。
|
|
|
|
①Available Mbytes:可用物理内存数。如果Available Mbytes的值很小(4MB或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
|
|
|
|
②page/sec:表明由于硬件页面错误而从磁盘取出的页面数,或由于页面错误而写入磁盘以释放内存空间的页面数。一般如果pages/sec持续高于几百,那么应该进一步研究页交换活动。有可能需要增加内存,以减少换页的需求(你可以把这个数字乘以4k就得到由此引起的硬盘数据流量)。pages/sec的值很大,不一定表明内存有问题,而可能是运行使用内存映射文件的程序所致。
|
|
|
|
③page read/sec:页的硬故障,page/sec的子集,为了解析对内存的引用,必须读取页文件的次数。阈值为>5,越低越好。大数值表示磁盘读而不是缓存读。
|
|
|
|
. 由于过多的页交换要使用大量的硬盘空间,因此有可能导致页交换内存不足与页交换的磁盘瓶颈混淆。因此,在研究内存不足不太明显的页交换的原因时,必须跟踪如下的磁盘使用情况计数器和内存计数器:
|
|
|
|
. Physical Disk\ %Disk Time。
|
|
|
|
. Physical Disk\ Avg.Disk Queue Length。例如,包括Page Reads/sec和% Disk Time及Avg.Disk Queue Length。如果页面读取操作速率很低,同时%Disk Time和Avg.Disk Queue Length的值很高,则可能有磁盘瓶颈。而如果队列长度增加的同时页面读取速率并未降低,则内存不足。要确定过多的页交换对磁盘活动的影响,请将Physical Disk\ Avg.Disk sec/Transfer和Memory\ pages/sec计数器的值增大数倍。如果这些计数器的计数结果超过了0.1,那么页交换将花费10%以上的磁盘访问时间。如果长时间发生这种情况,那么可能需要更多的内存。
|
|
|
|
. Page Faults/sec:每秒钟软性页面失效的数目(包括有些可以直接在内存中满足而有些需要从硬盘读取),而page/sec只表明数据不能在指定内存中立即使用。
|
|
|
|
. Cache Bytes:文件系统缓存(File System Cache),默认情况下为50%的可用物理内存。如果怀疑有内存泄露,请监视Memory\ Available Bytes和Memory\ Committed Bytes,以观察内存行为,并监视可能泄露内存进程Process\Private Bytes、Process\Working Set和Process\Handle Count。如果怀疑是内核模式进程导致了泄露,则还应该监视Memory\Pool Nonpaged Bytes、Memory\ Pool Nonpaged Allocs和Process(process_name)\ Pool Nonpaged Bytes。
|
|
|
|
. Pages per second:每秒钟检索的页数。该数字应少于每秒1页。
|
|
|
|
. Page Faults/sec:将进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
|
|
|
|
. Work set:处理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在内存中,当自由内存少于一个特定的阈值时,页就会被清除出内存。
|
|
|
|
. Inetinfo:Private Bytes。此进程所分配的无法与其他进程共享的当前字节数量。如果系统性能随着时间而降低,则此计数器可以是内存泄漏的最佳指示器。
|
|
|
|
. Processor:监视“处理器”和“系统”对象计数器可以提供关于处理器使用的有价值的信息,帮助决定是否存在瓶颈。
|
|
|
|
. %Processor Time:被处理器消耗的处理器时间数量。如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。
|
|
|
|
. %User Time:表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接、水平分割大表格等方法来降低该值。
|
|
|
|
. %Privileged Time:(CPU内核时间)是在特权模式下处理线程执行代码所花时间的百分比。如果该参数值和“Physical Disk”参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。另外设置“Tempdb in RAM”,减低“max async IO”,“max lazy writer I/O”等措施都会降低该值。此外,跟踪计算机的服务器工作队列当前长度的Server Work Queues\ Queue Length计数器会显示出处理器瓶颈。队列长度持续大于4,则表示可能出现处理器拥塞。此计数器是特定时间的值,而不是一段时间的平均值。
|
|
|
|
. %DPC Time:越低越好。在多处理器系统中,如果这个值大于50%并且“Processor:%Processor Time”非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。
|
|
|
|
. Context Switches/sec:如果决定要增加线程字节池的大小,应该同时监视实例化inetinfo和dllhost进程这两个计数器。增加线程数可能会增加上下文切换次数,这样性能不会上升,反而下降。如果多个实例的上下文切换值非常高,就应该减小线程字节池的大小。
|
|
|
|
. %Disk Time:指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果只有%Disk Time比较大,而CPU和内存都比较适中,硬盘可能会是瓶颈。
|
|
|
|
. Avg.Disk Queue Length:指读取和写入请求(为所选磁盘在实例间隔中列队)的平均数。该值应不超过磁盘数的1.5~2倍。要提高性能,可增加磁盘。注意,一个Raid Disk实际有多个磁盘。
|
|
|
|
. Average Disk Read/Write Queue Length:指读取(写入)请求(列队)的平均数。.Disk Reads(Writes)/s:物理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大允许读取次数。
|
|
|
|
. Average Disksec/Read:指以秒计算的在此盘上读取数据的所需平均时间。.Average Disk sec/Transfer:指以秒计算的在此盘上写入数据的所需平均时间。.Bytes Total/sec:为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽进行比较。
|
|
|
|
|
|
通过《负载压力测试指标》章节的讨论,可以将数据库资源占用监控指标概括为:
|
|
|
|
|
|
|
|
|
|
. 共享内存中物理日志和逻辑日志的缓冲区的使用率。
|
|
|
|
. 磁盘的数据块使用情况以及被频繁读写的热点区域。
|
|
|
|
|
|
|
|
|
|
|
|
下面以SQL Server数据库性能计数器为例来分析。
|
|
|
|
. Access Methods:用于监视数据库逻辑页访问方法。
|
|
|
|
. Full Scans/sec:每秒钟不受限的完全扫描数。可以是基本表扫描或全索引扫描。如果这个计数器显示的值比1或2高,应该分析查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
|
|
|
|
. Page splits/sec:由于数据更新操作引起的每秒页分割的数量。
|
|
|
|
. Buffer Manager:监视SQL Server如何使用内存存储数据页、内部数据结构和过程高速缓存。计数器在SQL Server从磁盘读取数据库页和将数据库页写入磁盘时监视物理I/O。监视SQL Server所使用的内存和计数器,有助于确定是否由于缺少可用物理内存存储高速缓存中经常访问的数据,而导致瓶颈存在。如果是这样,SQL Server必须从磁盘检索数据,以及考虑是否可通过添加更多内存,或使更多内存可用于数据高速缓存或SQL Server内部结构来提高查询性能。
|
|
|
|
. Disk I/O:SQL Server从磁盘读取数据的频率。与其他操作相比,例如内存访问,物理I/O会耗费大量时间。尽可能减少物理I/O可以提高查询性能。
|
|
|
|
. Page Reads/sec:每秒钟发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理I/O的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。
|
|
|
|
. Page Writes/sec:每秒执行的物理数据库写的页数。
|
|
|
|
. Buffer Cache Hit Ratio:在“缓冲池”(Buffer Cache/Buffer Pool)中没有被读过的页占整个缓冲池中所有页的比率。可在高速缓存中找到,而不需要从磁盘中读取的页的百分比。这一比率是高速缓存命中总数除以自SQL Server实例启动后对高速缓存的查找总数。经过很长时间后,这一比率的变化很小。由于从高速缓存中读数据比从磁盘中读数据的开销要小得多,一般希望这一数值高一些。通常,可以通过增加SQL Server可用的内存数量来提高高速缓存命中率。计数器值依应用程序而定,但比率最好为90%或更高。增加内存直到这一数值持续高于90%,表示90%以上的数据请求可以从数据缓冲区中获得所需数据。
|
|
|
|
. Lazy Writes/sec:惰性写进程每秒写的缓冲区的数量。其值最好为0。
|
|
|
|
. Cache Manager:对象提供计数器,用于监视SQL Server如何使用内存存储对象,如存储过程、特殊和准备好的Transact-SQL语句以及触发器。
|
|
|
|
. Cache Hit Ratio:Cache可以包括Log Cache, Buffer Cache以及Procedure Cache,是一个总体的比率,是高速缓存命中次数和查找次数的比率之和。其对查看SQL Server高速缓存对于系统性能提升如何有效,是一个非常好的计数器。如果这个值持续低于80%,就需要增加更多的内存。
|
|
|
|
. Latches:用于监视称为“闩锁”的内部SQL Server资源锁。监视闩锁以明确用户活动和资源使用情况,有助于查明性能瓶颈。
|
|
|
|
. Average Latch Wait Time(ms):一个SQL Server线程必须等待一个闩的平均时间,以毫秒为单位。如果这个值很高,系统可能正经历严重的竞争问题。
|
|
|
|
. Latch Waits/sec:在闩上每秒的等待数量。如果这个值很高,表明系统正经历严重的竞争问题。
|
|
|
|
. Locks:提供有关个别资源类型上的SQL Server锁的信息。锁加在SQL Server资源上(如在一个事务中进行的行读取或修改),以防止多个事务并发使用资源。例如,如果一个排它锁被一个事务加在某一表的某一行上,在这个锁被释放前,其他事务都不可以修改这一行。应尽可能少使用锁,可提高并发性,从而改善性能。可以同时监视Locks对象的多个实例,每个实例代表一个资源类型上的一个锁。
|
|
|
|
. Number of Deadlocks/sec:导致死锁的锁请求的数量。
|
|
|
|
. Average Wait Time(ms):线程等待某种类型的锁的平均等待时间。
|
|
|
|
. Lock Requests/sec:每秒钟某种类型的锁请求的数量。
|
|
|
|
. Memory manager:用于监视总体的服务器内存使用情况,以估计用户活动和资源使用,有助于查明性能瓶颈。监视SQL Server实例所使用的内存,有助于确定是否由于缺少可用物理内存存储高速缓存中经常访问的数据而导致瓶颈存在。如果是这样,SQL Server必须从磁盘检索数据,以及考虑是否可以通过添加更多内存,或使更多内存可用于数据高速缓存或SQL Server内部结构,来提高查询性能。
|
|
|
|
. Lock blocks:服务器上锁定块的数量,锁是加在页、行或者表这样的资源上。通常不希望看到此值增长。
|
|
|
|
. Total Server Memory:SQL Server服务器当前正在使用的动态内存总量。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. %File Cache Hits:是全部缓存请求中缓存命中次数所占的比例,反映了IIS的文件缓存设置的工作情况。对于一个由大部分静态网页组成的网站,该值应该保持在80%左右。File Cache Hits是文件缓存命中的具体值,而File CacheFlushes是自服务器启动之后文件缓存刷新次数,如果刷新得太慢,会浪费内存;如果刷新得太快,缓存中的对象会太频繁地丢弃生成,起不到缓存的作用。通过比较File Cache Hits和File Cache Flushes可得出缓存命中率与缓存清空率的比率。通过观察这两个值,可以得到一个适当的刷新值(参考IIS的ObjectTTL、MemCacheSize和MaxCacheFileSize设置)。
|
|
|
|
|
|
①Bytes Total/sec:显示Web服务器发送和接收的总字节数。低数值表明该IIS正在以较低的速度进行数据传输。
|
|
|
|
②Connection Refused:数值越低越好。高数值表明网络适配器或处理器存在瓶颈。
|
|
|
|
③Not Found Errors:显示由于被请求文件无法找到而导致的服务器无法回应的请求数(HTTP状态代码404)。
|
|
|
|
|
|
这里主要讨论故障分析内容以及优化调整设置内容,同时还与读者分享故障分析的经验与实例。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
交易的响应时间如果很长,远远超过系统性能的需求,表示耗费CPU的数据库操作。例如排序,执行aggregate functions(例如sum、min、max、count)等较多,可考虑是否有索引以及索引建立得是否合理。尽量使用简单的表链接、水平分割大表格等方法来降低该值。
|
|
|
|
|
|
测试工具可以模拟不同的虚拟用户来单独访问Web服务器、应用服务器和数据库服务器,这样,就可以在Web端测出的响应时间减去以上各个分段测出的时间,就可以知道瓶颈在哪里并着手调优。
|
|
|
|
|
|
UNIX资源监控(NT操作系统同理)中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈,也可能是内存访问命中率低。“Swap in rate”和“Swap out rate”也有类似的解释。
|
|
|
|
|
|
UNIX资源监控(NT操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。合理使用的范围在60%~70%。
|
|
|
|
|
|
Tuxedo资源监控中指标队列中的字节数(Bytes on queue),队列长度应不超过磁盘数的1.5~2倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
|
|
|
|
|
|
SQL Server资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。注意该参数值是从SQL Server启动后,就一直累加记数,所以运行经过一段时间后,该值将不能反映系统当前值。
|
|
|
|
|
|
针对上述故障分析的重点内容,需要做相应的优化调整,建议如下。
|
|
|
|
|
|
|
|
|
|
③考虑在其他体系上设计系统,例如增加前置机、设置并行服务器等。
|
|
|
|
|
|
①内存的优化包括操作系统、数据库、应用程序的内存优化;
|
|
|
|
|
|
|
|
|
|
⑤调整数据块缓冲区大小(用数据块的个数表示)是一个重要内容;
|
|
|
|
|
|
|
|
①磁盘读写进度对数据库系统是至关重要的,数据库对象在物理设备上的合理分布能改善性能。
|
|
|
|
|
|
③通过把日志和数据库对象分布在独立的设备上,可以提高系统的性能。
|
|
|
|
④把不同的数据库放在不同的硬盘上,可以提高读写速度。建议把数据库、回滚段、日志放在不同的设备上。
|
|
|
|
⑤把表放在一块硬盘上,把非簇的索引放在另一块硬盘上,保证物理读写更快。
|
|
|
|
|
|
|
|
②并行操作资源限制的参数(并发用户的数目、会话数)。
|
|
|
|
|
|
|
|
|
|
①可以通过数组接口来减少网络呼叫。不是一次提取一行,而是在单个往来往返中提取10行,这样做效率较高。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
当在合理的加载下出现这些类型的问题时,则表示可能有基础性的设计问题,比如说:算法问题,低效的数据库应用程序交互作用等,这些都不是通过简单升级硬件以及调整系统配置就可以解决的问题,此时软件的故障定位和调优将占有更重要的地位。
|
|
|
|
|
|
目前Web开发者开始提供可定制的Web网站,例如,像搜索数据之类的任务,现在可以由服务器执行,而无需客户干预。然而,这些变革也导致了一个结果,这就是许多网站都在使用大量的未经优化的数据库调用,从而使得应用性能大打折扣。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
优秀的网站设计都会关注这些问题。然而,与静态页面的速度相比,任何数据库调用都会显著地影响Web网站的响应速度,这主要是因为在发送页面之前必须单独地为每个访问网站的用户进行数据库调用。
|
|
|
|
这里提出的性能优化方案正是基于以下事实:访问静态HTML页面要比访问那些内容依赖于数据库调用的页面要快。它的基本思想是:在用户访问页面之前,预先从数据库提取信息,写入存储在服务器上的静态HTML页面。为了保证这些静态页面能够及时地反映不断变化的数据库数据,必须有一个调度程序管理静态页面的生成。
|
|
|
|
当然,这种方案并不能够适应所有的情形。例如,如果是从持续变化的大容量数据库提取少量信息,这种方案是不合适的。
|
|
|
|
每当该页面被调用时,脚本就会提取最后的更新时间并将它与当前时间比较。如果两个时间之间的差值大于预定的数值,更新脚本就会运行,否则,该ASP页面把余下的HTML代码发送给浏览器。
|
|
|
|
如果每次访问ASP页面的时候都要提供最新的信息,或者输出与用户输入密切相关,这种方法并不实用,但这种方法可以适应以固定的时间间隔更新信息的场合。
|
|
|
|
如果数据库内容由客户通过适当的ASP页面更新,要确保静态页面也能够自动反映数据的变化,我们可以在ASP页面中调用Update脚本。这样,每当数据库内容改变时,服务器上也有了最新的静态HTML页面。
|
|
|
|
另一种处理频繁变动数据的办法是借助Microsoft SQL Server 7.0或以上版本的Web助手向导(Web Assistant Wizard),这个向导能够利用Transact-SQL、存储过程等从SQL Server数据生成标准的HTML文件。
|
|
|
|
Web助手向导能够用来定期地生成HTML页面。正如前面概要介绍的方案,Web助手可以通过触发子更新HTML页面,比如在指定的时间执行更新或者在数据库数据变化时执行更新。
|
|
|
|
SQL Server使用名为sp_makewebtask的存储过程创建HTML页面,它的参数是目标HTML文件的名字和待执行存储过程的名字,查询的输出发送到HTML页面。另外,也可以选择使用可供结果数据插入的模板文件。
|
|
|
|
万一用户访问页面的时候正好在执行更新,我们可以利用锁或者其他类似的机制把页面延迟几秒钟。
|
|
|
|
我们对纯HTML加调度ASP代码和普通的ASP文件进行了性能测试。普通的ASP文件要查找5个不同的表为页面提取数据。为了和这两个文件相比较,对一个只访问单个表的ASP页面和一个纯HTML文件也进行了测试。测试结果如下表所示。
|
|
|
|
|
|
|
|
其中TTFB是指“Total Time to First Byte”, TTLB是指“Total Time to Last Byte”。
|
|
|
|
测试结果显示,访问单个表的ASP页面的处理时间是720.5ms,而纯HTML文件则为427ms。普通的ASP文件和纯HTML加调度ASP代码的输出时间相同,但它们的处理时间分别为3633.67ms和1590ms。也就是说,在这个测试环境下我们可以把处理速度提高43%。
|
|
|
|
如果我们要让页面每隔一定的访问次数进行更新,比如100次,那么这第100个用户就必须等待新的HTML页面生成。不过,这个代价或许不算太高,其他99个用户获得了好处。
|
|
|
|
静态页面方法并不能够适合所有类型的页面。例如,某些页面在进行任何处理之前必须要有用户输入。但是,这种方法可以成功地应用到那些不依赖用户输入却进行大量数据库调用的页面,而且这种情况下它将发挥出更大的效率。
|
|
|
|
在大多数情况下,动态页面的生成将在相当大的程度上提高网站的性能,而且无须在功能上有所折衷。虽然有许多大的网站采用了这个策略来改善性能,但也有许多网站完全由于进行大量没有必要的数据库调用,而表现出很差的性能。
|
|
|
|
|
|
数据库服务器性能问题主要表现在某些类型操作的响应时间过长、同一类型事务的并发处理能力差和锁冲突频繁发生等方面。应该说,这些问题是数据库服务器性能不佳的典型表现。由于造成上述情况的原因众多,需要分情况加以分析。
|
|
|
|
|
|
响应时间(Response Time, RT)是系统完成事务执行准备后所采集的时间戳和系统完成待执行事务后所采集的时间戳之间的时间间隔,是衡量特定类型应用事务性能的重要指标,标志了用户执行一项操作大致需要多长时间。响应时间过长意味着用户完成执行一项命令需要等待相当长的时间。实践表明,通常情况下用户能够接受的响应时间最大为200 ms。不仅如此,响应时间过长也是造成系统锁冲突严重的重要原因之一。
|
|
|
|
造成响应时间过长的原因非常复杂,通常可以从以下几个方面考虑。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据库服务器负载过重不可避免地会造成响应时间过长。这标志着当前服务器系统的硬件条件不能满足实际用户对性能的需要。服务器负载过重主要表现在CPU使用率高、内存占用率大、I/O与页面交换频繁发生等方面。由于服务器系统本身一般都提供性能监控程序,定位服务器性能问题相对比较容易。解决这类问题的方法一般是升级服务器硬件,提高数据库服务器本身的处理能力。但是,通过升级服务器硬件获得的性能提升是很有限的,并且对于某些诸如算法复杂度过高等问题根本无法解决。
|
|
|
|
|
|
糟糕的数据库设计是导致单一事务响应时间过长的最重要原因。通常,数据库设计在系统开发初期进行,此时,数据库设计人员往往对数据的实际规模和特性没有足够的了解。在数据库设计方面,对响应时间影响较大的因素有数据库表的规模、索引的使用、数据的分布、查询优化等。其中索引的使用极大影响事务执行的响应时间。实际上,很多情况下应用程序在访问大规模数据库表时的确没有使用索引。造成这种情况的原因通常是开发人员的疏忽,也有用户的需求变化过多,某些数据库字段不适合建立索引的情况。在这里需要特别指出的是,对组合索引进行查询时,查询条件中字段的顺序与数据库设计的索引字段顺序要一致。如果顺序颠倒,组合索引根本不能被数据库使用。例如,表A(field1, field2, field3),有组合索引index(field1, field2),诸如
|
|
|
|
SELECT * FROM A WHERE((field2=condition2)AND(field1=condition1))和SELECT * FROM A WHERE(field2=condition2)的查询无法使用index索引。此外,并非增加索引就一定能够提高单一事务执行的响应时间。过多的索引使用将极大地增加插入操作(INSERT)的花费,从而使响应时间变长。
|
|
|
|
数据库表规模过大,是指单一数据库表的记录数在百万行以上,对这类表直接进行检索而不采取必要的优化手段,必然造成单一查询响应时间过长。如果数据库表的规模一再增大,使用索引也不能很有效地解决响应时间过长的问题。对此类问题,可能的解决办法是对数据进行分布,使查询能够并行执行或缩小查询的范围。目前,主流关系数据库管理系统都提供表分区(分段)存储,以使得软件开发人员比较容易地实现数据分布。
|
|
|
|
查询优化对响应时间的影响也不容忽视,尽管优化活动由数据库管理系统完成。实际上一条结构化查询语句(SQL)的写法有很多种,不同的写法可能有不同的响应时间,这一差别可能非常大。如果开发人员在软件编写过程中恰好使用了执行效率低的SQL语句,其响应时间自然就会变长。目前,某些独立软件开发商已经注意到这种情况,并开发了相应的软件帮助应用软件开发人员找到执行最快的SQL语句的写法。但是,由于数据库本身是动态变化的,执行最快的SQL语句也可能变化,所以这种方法也是有局限性的。
|
|
|
|
|
|
事务粒度过大指单一数据库事务执行过程中,需要以某种并发控制机制访问多个数据库资源。通常采用的并发控制机制是互斥锁或者共享锁。这种大粒度事务的执行由于要访问多个数据库资源(如数据库表),本身就需要消耗相当长的时间。此外,由于通常事务在执行的时候会对数据库资源进行加锁,这类事务也对其他访问该资源的用户造成影响。由于这类事务通常使用的锁数量都在两个以上,如果不合理地进行控制,极容易造成死锁。因此,在应用软件设计过程中,应该尽量消除大粒度事务。
|
|
|
|
|
|
批任务是指一次操作将对数据库中大量数据进行互斥访问的数据库事务。这种类型的事务通常将更新同一个数据库表中的数千项乃至更多的数据。由于这类任务把所有操作放置在同一个数据库事务中,所访问的资源在其执行过程中始终被锁定,必然会对其他普通事务造成访问影响。此外,由于这类任务本身将对数据库服务器造成巨大的负担,使得服务器负载加重,从而影响独立事务的响应时间。通常情况下,批任务推荐在系统具有较长空闲时完成(如晚上),这样可以保证不对独立事务造成影响。如果由于业务的要求,批任务必须与独立事务混合运行,则必须对其加以改造,以减轻对其他事务的影响。
|
|
|
|
|
|
并发处理能力差是指应用系统在执行同一类型事务的多个实例时,不能获得与执行实例数量相当的吞吐量,而是大大低于理论值。一般来说,这类问题都是由于互斥访问造成的,即并发执行中的某个实例以互斥方式对资源进行访问,造成了其他同类型用户必需等待该实例释放锁定资源后才能执行。应该指出,由于某些资源必须以互斥的方式进行访问,某些类型的事务在同一时间是只能有一个进行执行的。对于并发处理能力差的问题,可能的解决方法有,降低同一类型事务中锁的粒度、优化应用逻辑以缩短单一类型事务响应时间等。
|
|
|
|
|
|
锁冲突是每个以关系数据库为核心的信息系统必须解决的问题。这里的锁冲突是指同一类型或不同类型事务在并发执行的情况下,由于资源互斥而相互影响,造成一个或多个事务无法正常执行的情况,包括资源锁定造成的数据库事务超时和死锁两个方面。
|
|
|
|
|
|
资源锁定导致的数据库事务超时,其原因是多方面的,其中,批任务影响其他类型独立事务的情况占有相当大的比重。此外,某些改造过的批任务由于频繁对特定资源进行锁定,也会对独立事务造成相当大的影响。如果在设定时间内,数据库服务器由于资源锁定没有能够完成客户端发出的操作请求,数据库服务器将通知被锁定的客户端该操作超时。
|
|
|
|
某些大粒度事务在并发执行的实例较多时也会造成同类或不同事务的数据库超时。
|
|
|
|
此外,应用系统如果没有健壮的异常处理机制,很可能造成锁资源不被释放(即,开始的事务既没有提交也没有回滚)。当这种错误发生时,必然造成资源被长久锁定。对此类问题,应用系统在开发的过程中需要采取一套完善的异常处理机制,确保资源不被长期锁定。
|
|
|
|
|
|
由于数据库死锁可以看作进程间死锁的一种特殊情况,我们可以采取与处理操作系统死锁相类似的方法解决数据库死锁的问题。造成死锁必须具备下述条件(Coffman et al 1971):
|
|
|
|
①互斥条件。每一个资源或者被分配给特定的进程,或者可用。
|
|
|
|
②持有并等待条件。被授权持有资源较早的进程可以请求新的资源。
|
|
|
|
③不可取代原则。事先被赋予的资源不能够从该进程被强制取走,它们必须被所持有的进程明确释放。
|
|
|
|
④环等待条件。必须存在两个或者多个进程的环形链,其中每一进程都等待由环形链的下一个成员所持有的资源。
|
|
|
|
由于软件开发人员对资源争用可能造成的死锁问题往往没有充分考虑,而目前主流数据库管理系统主要采用乐观的并发控制算法,导致应用系统实际使用过程中频繁发生死锁。应该说明,同类型数据库事务的不同实例之间由于访问资源的顺序一致,通常情况不会发生死锁;不同类型事务之间如果没有按照一个统一的契约进行并发访问,将极容易形成死锁。因此,在确保应用系统功能的前提下,制定一个不同事务之间进行并发访问的原则,就可以有效消除环等待,减少死锁发生的可能性。
|
|
|
|
针对数据库的性能问题,一般应采用什么样的解决办法呢?
|
|
|
|
在对数据库服务器常见性能问题进行充分研究的基础上,我们制定了一套适用于解决已发布系统性能问题的通用方法,步骤如下:
|
|
|
|
|
|
|
|
|
|
④对规模较大的数据或者无法通过一般优化解决的锁冲突进行分布。
|
|
|
|
必须指出,解决数据库性能问题是一个迭代和往复的过程,通常需要在各种条件的矛盾之间寻求最佳的平衡点。
|
|
|
|
|
|
对数据库服务器软件、操作系统、网络环境乃至客户端等各类处理单元的性能相关信息进行监视并记录,是发现数据库性能问题的基础。这一步骤的作用是搜集与数据库服务器性能表现密切相关的数据,作为分析性能问题的基础。由于各个处理单元的状态是随着时间的推移而动态变化的,性能数据的监视与采集必须尽可能详细地记录下所有时间点上各个处理单元的状态信息。为此,我们采取对各个采样时间点的处理单元状态信息进行快照方式,来对性能相关数据进行监控和记录,相邻采样时间点之间的间隔越小,状态信息就越准确。
|
|
|
|
在各类监视活动中,对数据库服务器软件性能属性的监视是整个活动的重点,主要集中在数据库会话的状态信息、执行的结构化查询语句和锁使用情况等方面。其中,状态信息代表了单一数据库会话在其生命周期中的状态变化情况,包括在哪一个时间点开始一个事务,在哪一个时间点被其他会话锁定,何时超时等。执行的结构化查询语句代表单一数据库会话在其生命周期中执行的所有数据库操作。锁使用情况代表整个数据库服务器的锁资源使用和变化情况。此外,顺序扫描、高代价查询等属性也是代表数据库服务器性能的重要数据。
|
|
|
|
|
|
通过对数据库锁使用情况和SQL语句的执行历史进行分析,可以发现一个事务同时占用大量数据库锁的应用逻辑事务。通常这类事务都属于批任务。由于批任务本身的特性,决定了在其整个执行过程中,必然消耗大量资源,最好将其放置在系统具有充分空闲时间时进行。
|
|
|
|
|
|
如果应用系统锁冲突频繁发生,那么该系统的性能表现不可能令人满意。导致这种问题的原因非常复杂,主要表现在事务粒度过大、响应时间过长、异类事务互相影响并形成死锁等情况。通过对数据库锁使用情况信息的分析,可以定位发生锁冲突的各个会话;在此基础上对发生锁冲突的会话各自的执行状态变化和结构化查询语句进行分析,可以定位发生锁冲突的应用逻辑源程序。如果造成锁冲突的是同种或者异种普通事务,必须对其本身特性加以分析,确定是否本身粒度过大,数据访问是否存在瓶颈等。对这类事务的优化相对较难,一般需要开发人员的经验和对应用逻辑本身特性的了解。
|
|
|
|
|
|
数据分布的主要目的是,通过数据库服务器的并行执行特性,使得单一事务的执行具有较短的响应时间和不同类的事务之间影响相对缩小。在缩短响应时间方面,这种方法主要适用于对规模较大的数据库表进行访问的情况。它不仅使得特定的查询可以并行执行,而且有可能改变结构化查询语句的执行计划,缩小查询进行的范围。此外对于异类事务之间,或者同类事务的不同实例锁冲突频繁的问题,可以通过数据分布加以解决。
|
|
|
|
数据库性能问题通常表现在响应时间过长,并发处理能力差和锁冲突严重等方面,其原因是多方面的。本书提出的通过监视并记录应用系统处理单元性能相关数据,来定位性能问题的方法,可以帮助开发人员有效发现系统中存在的主要性能问题。必须指出,解决数据库性能问题是一个迭代和往复的过程,通常需要在各种条件的矛盾之间寻求合理的平衡点。
|
|
|
|
|
|
下面将以Oracle为例,讨论数据库优化的一些方法,对于其他的数据库,由于其实现的机制以及特性可能与Oracle不同,那么优化的方法也会有所不同,大家可以参照其手册,进行分析。
|
|
|
|
虽然这些方法属于数据库开发人员或者数据库管理人员优化系统的方法,但是如果测试人员了解这些方法,就可以更好地分析、定位数据库性能问题,制定有针对性的测试用例。
|
|
|
|
Oracle与提高性能有关的特性主要包括:索引、并行执行、簇与散列簇、分区、多线程服务器以及同时读取多块数据等。下面分别进行介绍。
|
|
|
|
这里列出了Oracle配置的关键参数以及其使用方法。
|
|
|
|
①max_dspatchers:指定了系统允许同时进行的调度进程的最大数量。
|
|
|
|
②max_shared_servers:指定了系统允许同时进行的共享服务器进程的最大数量。如果系统中出现的人为死锁过于频繁,那么管理员应该增大这个参数的值。
|
|
|
|
③parallel_adaptive_multi_user:当该参数的值为true时,系统将启动一个能提高使用并行执行的多用户系统性能的自适应算法。这个算法将根据查询开始时的系统负载自动降低查询请求的并行度。
|
|
|
|
④parallel_automatic_enabled:如果将该参数的值设置为true,那么Oracle将确定控制并行执行的参数的默认值。
|
|
|
|
⑤parllel_broadcast_enabled:该参数允许管理员提高散列连接和合并连接操作的性能,在这样的连接操作中,系统将一个大尺寸的结果集与一个小尺寸的结果集连接在一起(在合并操作中,数据的尺寸是根据字节数而不是记录数确定的)。
|
|
|
|
⑥parllel_execution_message_size:这个参数指定了系统并行执行时的消息尺寸(在Oracle的旧版本中,这个概念是指并行查询、PDML、并行恢复和并行复制数据等)。
|
|
|
|
⑦parllel_max_servers:指定了实例能同时运行的并行执行进程和并行恢复进程的最大数量。随着用户需求的增长,在创建实例时,为这个参数设置的值将不再能满足用户需求,所以应当增大这个参数的值。
|
|
|
|
⑧ parllel_min_percent:系统将联合使用parllel_max_servers、parllel_min_servers和该参数。这个参数允许指定并行执行进程(即参数parllel_max_servers之值)的最小百分比。
|
|
|
|
⑨parllel_min_servers:这个参数指定了实例并行执行进程的最小数量。其值就是实例启动时Oracle创建的并行执行进程数。
|
|
|
|
⑩parllel_threads_per_cpu:指定了实例默认的并行度和并行自适应以及负载平衡算法。它指明了并行执行过程中一个CPU能处理的进程或线程数。
|
|
|
|
?partition_view_enabled:指定了优化器是否使用分区视图。Oracle推荐用户使用分区表(这是在Oracle8之后引入的)而不是分区视图。分区视图只是为了提供Oracle的后向兼容性。
|
|
|
|
?revovery_parallelism:这个参数指定了恢复数据库系统时使用的进程数。
|
|
|
|
|
|
在数据库系统中,索引是一种可选结构,其目的是提高数据访问速度。利用索引可提高用户访问数据的速度,或直接从索引中独立检索数据。如果对索引的配置和使用进行了优化,那么索引能大大降低数据文件的I/O操作并提高系统性能。
|
|
|
|
但是在为一个表创建索引之后,Oracle将自动维护这个索引。当用户在表中插入、更新或删除记录时,系统将自动更新与该表相关的索引。一个表可以有任意数量的索引,但一个表的索引越多,用户在该表中插入、更新或删除记录时所造成的系统开销也越大。其原因是无论何时更新表,系统都必须更新与之相关的索引。
|
|
|
|
索引是建立在表的一个或多个字段之上的。索引的作用大小取决于该字段或字段集的选择性。所谓选择性,是指索引能降低数据集中的程度。如果表中与某个索引相关的字段值各不相同,那么该索引就有很好的选择性。一个选择性很差的索引的例子,是基于字段值仅为true/false的字段创建的索引,因为表中很多记录该字段的字段值都相同。一个索引可能只能帮助管理员降低检索的记录数,而不能惟一地确定一条记录。例如:如果为一个表的LastName字段创建了一个索引,现在用户需要搜索John Smith,那么这个索引将返回LastName字段值为Smith的所有记录,因而用户还不得不在返回的记录中搜索含John的记录。索引的选择性越好,就越有助于降低返回记录的数量,从而提高数据访问速度。下面介绍有效创建和使用索引的技巧和方法。
|
|
|
|
|
|
索引的主要作用之一就是降低系统处理的数据量。对CPU使用和等待完成I/O操作的时间上,I/O操作引起的系统开销都是非常昂贵的。降低I/O操作可提高系统性能和处理能力。如果不使用索引,那么为了找到特定的数据,系统将不得不扫描表中的所有数据。
|
|
|
|
|
|
|
|
如果不使用索引,系统必须扫描整个emp表并检查表中每条记录的employee_id字段的值。如果emp表很大,那么这个操作可能意味着数量巨大的I/O读写和很长的处理时间。
|
|
|
|
如果为emp表的employee_id字段创建了索引,那么系统将遍历该索引并找到用户所查询记录的ID。找到记录ID之后,只需一条额外的I/O操作就能检索到用户所需的数据。
|
|
|
|
用于说明这个问题的最好例子,是只需查找一条记录的情况。在表的每条记录中,类似employee_id这样的字段的值可能在整个表中都是惟一的。这意味着查询结果值返回一条记录,这种查询的效率是非常高的。
|
|
|
|
在某些情况下,索引必须返回大量数据。如下面的例子:
|
|
|
|
|
|
这个查询语句很可能返回大量数据,因为索引操作返回了大量记录的ID,并且系统必须独立访问这些记录的ID,所以这种情况下,不使用索引可能比使用索引的效率更高,直接进行表扫描可能效率更高。不同情况下,采用哪种查寻方法更好,很大程度上取决于表的数据量和组织形式。
|
|
|
|
对于不同的数据,在某些情况下位图索引可能非常有用,而在另外一些情况下,使用位图索引可能没有任何好处。
|
|
|
|
|
|
如果对表创建了索引,那么更新、插入和删除表中的记录都将导致额外的系统开销。在系统提交这些操作之前,系统将会更新所有与该表相关的索引。这可能需要花费很长时间,并额外增加一定的系统开销。
|
|
|
|
|
|
在某些情况下,表中的某些字段的选择性可能很低。开发人员没必要为所有表创建索引,实事上,在某些情况下索引引起的问题比解决的问题更多。在很多情况下,需要反复试验,才能确定一个索引是否有助于提高系统性能。
|
|
|
|
但是,位图索引能在字段选择性不高的情况下工作得很好。一个位图索引可以和其他位图索引联合使用,以降低系统检索的数据集。对于某些值为true/false、yes/no或其他小范围数据的字段,建立位图索引是非常合适的。请记住:位图索引所占用的空间,是随着与该索引相关的字段的不同值的数量的增加而增加的。
|
|
|
|
如果决定创建一个索引,那么确定为哪些字段创建索引是非常重要的。对于不同的表,可能会选择一个或多个字段创建索引。可使用如下方法来确定在哪些字段上创建索引:
|
|
|
|
①选择那些最常出现在where子句中的字段。经常被访问的字段最可能受益于索引。
|
|
|
|
|
|
③必须注意索引导致的查询语句性能的提高与更新数据时性能的降低之间的平衡。
|
|
|
|
④经常被修改的字段不适合创建索引,其原因是,更新索引将增加系统开销。
|
|
|
|
在某些情况下,使用复合索引的效率可能比使用简单索引的效率更高。下面的一些例子说明了应当在何种情况下使用复合索引。
|
|
|
|
①某两个字段单独来看都不具有惟一性,但结合在一起却有惟一性,那么这种情况下,复合索引将工作得很好。例如:A字段和B字段都几乎没有惟一性值,但绝大多数情况下,字段A和B的某个特定组合却具有惟一性特点。那么在检索数据时,可在where子句重视and操作符来将这两个字段连接在一起。
|
|
|
|
②如果select语句中的所有值都位于复合索引中,那么Oracle将不会检索表,而直接从索引中返回数据。
|
|
|
|
③如果多个查询语句的where子句中作为查询条件的字段都不相同,但返回的记录相同,那么应当考虑利用这些字段创建一个复合索引。
|
|
|
|
在创建索引之后,开发人员应当定期利用SQL TRACE工具或EXPLAIN PLAN来察看用户查询是否充分利用了索引。很有必要花费一定精力来试验使用索引和未使用索引在效率上的差别,以判断索引所耗费资源是否物有所值。
|
|
|
|
应该删除那些不经常使用的索引。可使用alter index monitoring usage语句来跟踪索引的使用情况。还可以从系统表all_indexes、user_indexes和dba_indexes中查询用户访问索引的频率。
|
|
|
|
如果为一个不适合创建索引的字段或表创建了索引,那么这可能会导致系统能力的下降。而如果创建的索引合理,那么这将降低系统的I/O操作并加快访问速度,从而大大提高系统性能。
|
|
|
|
|
|
Oracle9i的并行执行特性就是Oracle旧版本中读者熟知的并行查询选项。而在Oracle9i中,这个特性已内嵌在Oracle RDBMS中。
|
|
|
|
为什么要实现并行执行?RDBMS的绝大多数操作都可分为以下3类:
|
|
|
|
①被CPU限制的操作:这类操作的速度和单CPU运行速度一样。通过并行化操作,多个CPU可并行处理系统负载,因此可以更快完成该操作。
|
|
|
|
②被I/O限制的操作:这类操作花费了绝大部分时间等待系统完成I/O操作。当系统中同时出现多个I/O请求时,绝大多数raid控制器将很好地工作。另外,当一个线程需要等待完成I/O操作时,可充分利用CPU来处理另一线程的CPU部分。
|
|
|
|
③被竞争限制的操作:并行处理不能改善由资源竞争所限制的操作。
|
|
|
|
对表扫描而言,系统花费在等待数据从磁盘返回的时间常常比处理数据所花费的时间还长。通过并行机制,可用多个服务器进程处理查询操作,从而弥补了系统在这方面的问题。当一个进程在等待I/O操作时,CPU可执行另一个进程。如果数据库系统运行在对称多处理器(Symmetric Multiprocessor, SMP)计算机、计算机群集或大规模并行处理(Massive Parallel Processing, MMP)计算机上,那么开发人员可充分利用并行处理机制的优势。
|
|
|
|
并行执行使Oracle的某些功能由多个服务器进程协同处理成为可能。这些功能包括查询、创建索引、加载数据和恢复数据库。所有这些功能都遵循一个共同规则,即充分利用CPU资源。
|
|
|
|
|
|
并行查询处理允许多个服务器进程以并行方式处理某些Oracle语句。
|
|
|
|
并行查询操作将该查询分为几个不同的部分,每部分由不同的服务器进程进行处理。这些进程称为查询服务器。一个被称为“查询协调者”的进程负责调度这些查询服务器。系统将一个SQL语句和一个并行度提交给查询协调进程,而协调进程则负责将该查询分配给查询服务器,并将每个查询服务器返回的结果组合成一个整体。并行度是指分配给该查询的查询服务器数量。Oracle服务器能对连续、排序以及表扫描操作实现并行执行。
|
|
|
|
在多处理器或并行处理计算机上,并行查询操作是非常有效的;在单处理器计算机上,如果大部分时间都花在了等待系统完成I/O操作上,那么使用并行查询也是非常有效的。具有足够I/O带宽的系统,尤其是使用磁盘阵列的系统,都能够从并行查询操作中受益。
|
|
|
|
如果通常情况下系统CPU的使用率达到了100%,并且系统中只有少量磁盘驱动器,那么使用并行查询是没什么意义的。同样,如果系统的内存非常紧张,那么并行查询也没有多大意义。
|
|
|
|
在并行查询中,合理的I/O分布和并行度是最需要调整的两个方面。对并行度的调整一方面需要反复的试验,另一方面还需要一定的分析。应当首先根据如下一些因素考虑并行度。
|
|
|
|
①计算机的CPU能力:CPU的数量和能力将影响系统能运行的查询进程数量。
|
|
|
|
②系统处理大量进程的能力:一些操作系统能处理很多并发进程,而另一些操作系统则没有这方面的能力。
|
|
|
|
③系统负载:如果系统现在的运行已经达到了极限,那么对并行度的调整不会有太大效果。如果系统运行已达其能力极限的90%,那么太多的查询进程将使系统不堪重负。
|
|
|
|
④系统处理的查询数量:如果系统的大部分操作是更新操作,但仍有少量的重要查询存在,那么开发人员可能希望系统运行多个查询进程。
|
|
|
|
⑤系统的I/O能力:如果磁盘上的数据是分片或是使用磁盘阵列存储的,那么系统能够处理多个并行查询。
|
|
|
|
⑥操作类型:系统是否需要处理很多的全表扫描或排序?并行查询服务器非常有助于这类操作。
|
|
|
|
这些因素对系统采用的查询并行度有一定影响。下面是关于并行度的另一些建议。
|
|
|
|
①诸如排序之类的,需要大量CPU资源的操作应当采用较低的并行度。其原因是这类受限于CPU的操作已经充分利用了CPU,而不需等待系统的I/O操作。
|
|
|
|
②诸如全表扫描之类的,需要大量磁盘I/O的操作,应当采用较高的并行度。需要等待磁盘I/O的操作越多,系统就越能受益于并行操作。
|
|
|
|
③如果系统中有大量的并发进程,那么应当采用较低的并行度。因为太多的进程将使系统不堪重负。
|
|
|
|
在确定使用并行操作之后,读者可通过查询动态性能视图V$PQ_SYSSTAT来监控系统。
|
|
|
|
|
|
并行查询的另一个特征是以并行方式创建索引的能力。通过这个特性,系统用于创建索引的时间将大大减少。类似于并行查询操作,并行创建索引操作也有两组查询服务器。其中一组查询服务器的功能是扫描需要创建索引的表,以获得ROWID和与索引相关的字段值;另一组查询服务器则对第一组查询服务器所得到的值进行排序,并将排序后的结果传递给协调进程。而协调进程再根据这些排序之后的条目创建B树索引。
|
|
|
|
|
|
通过使用多个并发会话同时往同一个表中写数据,可实现数据加载的并行化。对于不同的系统配置,通过并行方式加载数据,可以提高数据加载性能。因为加载数据不仅需要大量的CPU资源而且还需要大量的I/O操作,所以并行化数据加载将提高数据加载的性能。并行化数据加载将通过多个直接加载器进程实现。
|
|
|
|
并行加载数据是非常有用的,特别是在数据加载时间很紧张的环境中尤其如此。通过将每个输入文件放置在不同的卷上,可提高并行加载数据的性能。并行查询操作中所有的通用调整原则都是用于并行加载数据操作的。
|
|
|
|
|
|
并行恢复是并行查询选项的一个非常重要的特性。在评估Oracle和测试软硬件时,需要有意地使系统崩溃,以检验系统的可恢复性。通过使用并行恢复选项,恢复数据库和实例的时间将大大缩短。当被恢复的系统有很多磁盘并支持异步I/O操作时,系统恢复所用的时间将会大大缩短。对于只有很少磁盘的小系统或不支持异步I/O的系统,采用并行方式恢复系统是不明智的。在并行恢复方式中,一个进程负责从重做日志中读取和调度重做入口,并将这些入口传递给恢复进程。而恢复进程则负责将用户对数据库所作的修改写进数据库中。
|
|
|
|
总之,在平衡操作负载方面并行查询选项是非常有用的,当其他进程在等待系统完成I/O操作时,并行查询可使CPU转而处理其他进程,从而充分利用系统的CPU资源。对于多处理器计算机,使用并行查询是非常有用的,但这并不是说并行查询不能用于单处理器计算机。
|
|
|
|
|
|
簇(cluster),有时被称为索引簇,是Oracle数据库中用于存储表的一种方法。在一个簇中,系统将多个相关的表存储在一起,以缩短用户访问相关记录的时间。只有当这些相关表经常被同时访问时,才适合使用簇。对用户和应用程序而言,簇的存在是透明的,簇只影响数据的存储方式。
|
|
|
|
在某些情况下使用簇是非常有利的,而在另外一些情况下,使用簇却可能非常不利。应当仔细考虑簇是否有助于提高系统性能。一般而言,如果集中存放的数据主要用于连接表中,那么使用簇是很好的。如果两个表存放了相关数据,并且这两个表经常被同时访问,那么通过使用簇可将相关数据预装入SGA中,从而提高用户访问数据的性能。因为开发人员经常同时使用这两个表,所以在用户访问其中一个表时,将另一个表的数据也放入SGA中,可大大缩短用户访问数据的时间。如果一般情况下开发人员不会同时使用这些信息,那么簇将不能提高系统性能,并且这种情况下,簇实际上会导致系统性能的轻微下降,其原因是额外的表信息将占据更多的SGA空间。簇的另一个不足之处在于,当用户执行insert语句时将降低系统性能。引起性能下降的原因是簇在使用存储空间上采用的方法更加复杂,并且系统需要将多个表存储在同一个数据块中。簇表比单个表占用了更多的存储空间,这将导致系统扫描更多的数据。另外如果系统经常对这些表中的某一个表作全表扫描,那么不应当为这些表创建簇。因为如果创建了簇,那么额外数据将占用SGA的部分空间并导致额外的I/O操作,这两方面的原因都会降低系统性能。
|
|
|
|
|
|
散列簇和簇非常相似,但散列簇采用散列函数而不是索引访问簇键。散列簇根据散列函数的计算结果保存数据。散列函数是一个数学函数,这个函数根据散列键的值来确定簇中的数据块。
|
|
|
|
尽管可以以类似于索引簇的方式创建散列簇,但不必为所有表创建散列簇。实际上,更经常做的是为一个单独的表创建散列簇,以利用散列簇的特性。通过使用散列索引,系统只需一次I/O操作,系统就能检索到用户所需数据,如果使用B索引,系统需要多次I/O操作才能检索到需要的数据。适合创建散列簇的表应具有以下特征:
|
|
|
|
|
|
|
|
|
|
|
|
一个适合于创建散列簇的典型例子是一个用于存储零件信息的表。通过建立一个关于零件号的散列键值,用户对该表的访问将非常有效而且非常快。任何时候,如果系统中有一个静态的表,其中的一个或多个字段的值具有惟一性特征,那么可考虑为这样的表创建散列簇。
|
|
|
|
和索引簇一样,使用散列簇既有优点也有不足。当用户使用关于簇键的等式查询检索数据时,散列簇具有很高的效率。如果用户不是根据簇键值检索数据,那么这个查询就不能被散列化。这就像在索引簇中见到的那样,当在散列簇表中使用insert语句时,将降低系统性能。
|
|
|
|
|
|
当系统执行表扫描时,Oracle具备同时读取多个数据块的能力,这种能力提高了系统的I/O速度。通过同时读取多块数据,Oracle能够从磁盘上读取更大的数据块,从而避免了对磁盘上数据进行搜索的操作。通过降低磁盘搜索和读取更大的数据块,可以降低系统的I/O开销和CPU开销。
|
|
|
|
Oracle的这个特性被称为多块读取。只有对于连续数据块,多块读取特性才有助于提高系统性能。通常情况下,一个盘区内的数据块都是连续的。如果数据存放在多个小盘区上,那么多块读取的性能将会降低。
|
|
|
|
Oracle初始化参数db-file-multiblock-read-count指定了一次多块读取能读取的数据量。因为这个参数几乎不会导致系统性能的下降,所以一般情况下,都将这个参数的值设置得很高。I/O的尺寸取决于初始化参数db-file-multiblock-read-count和db-block-size的值。
|
|
|
|
为了充分发挥多块读取数据的优势,应当尽量配置自己的系统以使数据库的块尽可能都是连续的。为了做到这一点,应当使用优化尺寸的盘区来创建数据库。盘区的尺寸应当远大于一次多块读取操作所读取的数据的尺寸。
|
|
|
|
|
|
分区(partition)这一特性的目的是允许大尺寸表或索引分解成小的更容易管理的部分,即分区。与原来的表或索引相比,因为分区变小了,所以系统访问分区的速度更快、效率也更高,可将分区想象成表或索引被分解之后的多个小尺寸的表或索引。系统可单独访问这些小尺寸的表或索引,也可以以组或整体方式访问之。
|
|
|
|
可使用多种分区方案来创建分区。这些方案确定了如何将数据分解成分区。可使用如下一些方案。
|
|
|
|
. Range Partitioning:这种方案根据数据的范围,比如月、年等对表中的数据进行分区。
|
|
|
|
. List Partitioning:这种方案和Range Partitioning分区方案很类似,但这种方案是按照数据的值,而不是数据的范围来进行划分的。
|
|
|
|
. Hash Partitioning:这种分区方案使用散列函数来实现对数据的自动分区。
|
|
|
|
. Sub-Partitioning:这种方法就是开发人员熟悉的复合分区方法。这种方法允许开发人员同时使用多种分区方案。
|
|
|
|
|
|
. 对能被分区的大尺寸表进行扫描时,分区可降低I/O操作和CPU的使用率。
|
|
|
|
|
|
. 能以删除分区的方式删除数据,而不必使用select语句来删除大量数据。
|
|
|
|
|
|
|
|
|
|
|
|
用户可通过专用服务器进程连接到Oracle实例,也可以通过多线程服务器进程连接到Oracle实例。因为每一个专用服务器进程都将占用大量内存资源和系统资源,所以有必要对多用户连接采用多线程服务器进程。
|
|
|
|
多线程服务器进程允许多个用户使用一定数量的共享服务器进程。所有对共享服务器的请求都必须经过调度进程,这个过程对SGA大缓冲池中的用户对共享服务器进程的请求进行排队。当系统处理完用户请求后,系统通过SGA中的大缓冲池将请求结果返回给调度进程。
|
|
|
|
因为共享服务器进程使用共享缓冲池对用户请求进行排队并返回数据,从而大大减少CPU和内存的使用。然而,正如读者所猜想的那样,多线程服务器也会增加系统开销。这就是为什么执行需要很长时间的批处理作业时,使用专用服务器的原因。
|
|
|
|
对配置和调整多线程服务器,需要调整参数文件中的参数。还应当小心监控系统的大缓冲池,以确保系统的运行没有超出分配给它的内存空间。
|
|
|
|
应当尽量监控只有少量用户的共享会话所使用的内存。监控结果将会告知共享会话使用了多少内存。利用这些数据,就能估算所有会话总共需要多少内存。可通过下面的SQL语句获得这些信息:
|
|
|
|
|
|
上面语句的输出结果告诉开发人员使用了多少内存。将使用的总内存量除以连接数,就可确定每个会话使用的内存数量。然后就可从每个会话使用的内存量来推算为了支持系统的所有会话,需要为系统的大缓冲池分配多大内存空间。
|
|
|
|
如果认为大缓冲池的内存太少,那么可通过调整初始化参数large_pool-size来增加大缓冲池的内存空间。请记住:除多线程服务器之外,系统还使用大缓冲池来执行并行查询操作。
|
|
|
|
初始化参数mts_dispatchers决定了每个网络协议使用的调度进程的数量。通过提高这个参数的值,可能会看到用户会话的性能得到了提高,其原因是用户会话不再需要等待可用调度进程。
|
|
|
|
除前面讨论的参数之外,还有如下一些参数与多线程服务器有关。
|
|
|
|
. mts_max-dispatcher:实例能创建的调度进程的最大数量。这里的调度进程包括所有网络协议的调度进程。
|
|
|
|
. mts_servers:实例刚启动时的共享服务器进程数。如果将这个参数设置为0,那么Oracle将不会是用共享服务器进程。为了满足系统需要,共享服务器进程的数量将会动态增长。
|
|
|
|
. mtx_max_servers:这个参数指定了实例中允许运行的共享服务器进程的最大数量。
|
|
|
|
如果应用程序能利用簇和索引的优势,那么簇和索引将有助于提高系统性能。如果应用程序使用了索引而又需要频繁更新数据,那么这样的索引将会降低系统性能,其原因是在数据更新的同时,系统也需要更新索引。同样地,如果用户的数据访问模式使用了簇,那么簇将会有助于提高系统性能;反之,簇将会成为系统的负担。
|
|
|
|
Oracle并行查询选项和并行服务器选项能极大地提高系统性能。通过将查询分配成多个服务器进程,并行查询选项提供了一种提高系统CPU使用率的机制。并行服务器为开发人员提供了一个健壮的可升级的服务器群集功能,这个特性不仅能提高系统性能,还为系统提供了立即排除错误的能力。应用程序和需求将决定这些特性是否有助于提高系统性能。在调整系统时,非常重要的一点是需要注意调整系统所冒的风险。在前面的内容介绍中,我们讨论了不同的系统调整主体,例如共享内存池的尺寸和数据块缓冲区等。提高共享内存池和数据库缓冲区的尺寸将会提高缓冲区的命中率,但这样的调整也存在着损害系统性能的风险。然而,如果读者对某些系统特性配置得不正确,那么它们对系统性能造成的负面影响会更大。任何时候调整系统,都应当预先估计该调整所面临的风险,特别是在没经过详细测试就对生产系统进行调整时更是如此。
|
|
|
|
如果对系统需要调整的方面和该调整所影响的方面进行了仔细考虑,并对应用程序的数据访问模式有深入的了解,那么可以将调整面临的风险降到最小。应当仔细考虑对系统所作的修改将会对系统造成的影响,并尽量了解系统修改对应用程序的影响。只有这样,才能在优化系统性能的同时,将系统调整的风险降到最低。
|
|
|
|
|
|
一般情况下,在测试的标志性阶段或者测试结束时需要出具测试报告,测试报告是整个测试的总结,其主要作用是描述测试结果。测试报告的格式可以不拘一格,但需要验证是否包括以下关键内容:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|