|
|
知识路径: > 数据库技术 > 事务管理 > 数据库的并发控制 > 封锁协议 >
|
|
考试要求:掌握
相关知识点:20个
|
|
|
|
|
|
|
封锁对象的大小称为封锁的粒度。封锁的对象可以是逻辑单元(如属性、元组、关系、索引项、整个索引直至整个数据库),也可以是物理单元(如数据页或索引页)。
|
|
|
|
封锁粒度与系统的并发度和并发控制的开销密切相关。封锁的粒度越大,并发度越小,但系统开销也就越小;封锁的粒度越小,并发度越高,但系统开销也就越大。
|
|
|
|
选择封锁粒度时必须同时考虑封锁对象和并发度两个因素,对系统开销与并发度进行权衡,以求得最优的效果。一般说来,需要处理大量元组的用户事务可以以关系为封锁对象;需要处理多个关系的大量元组的用户事务可以以数据库为封锁对象;而对于一个处理少量元组的用户事务,可以以元组为封锁对象以提高并发度。
|
|
|
|
多粒度(multiple granularity)机制是指通过允许各种大小的数据项并定义数据粒度的层次结构,其中小粒度数据项嵌套在大粒度数据项中。对此,可以构造一个粒度层次图,粒度层次图像一棵倒置的树,故也称多粒度树。
|
|
|
|
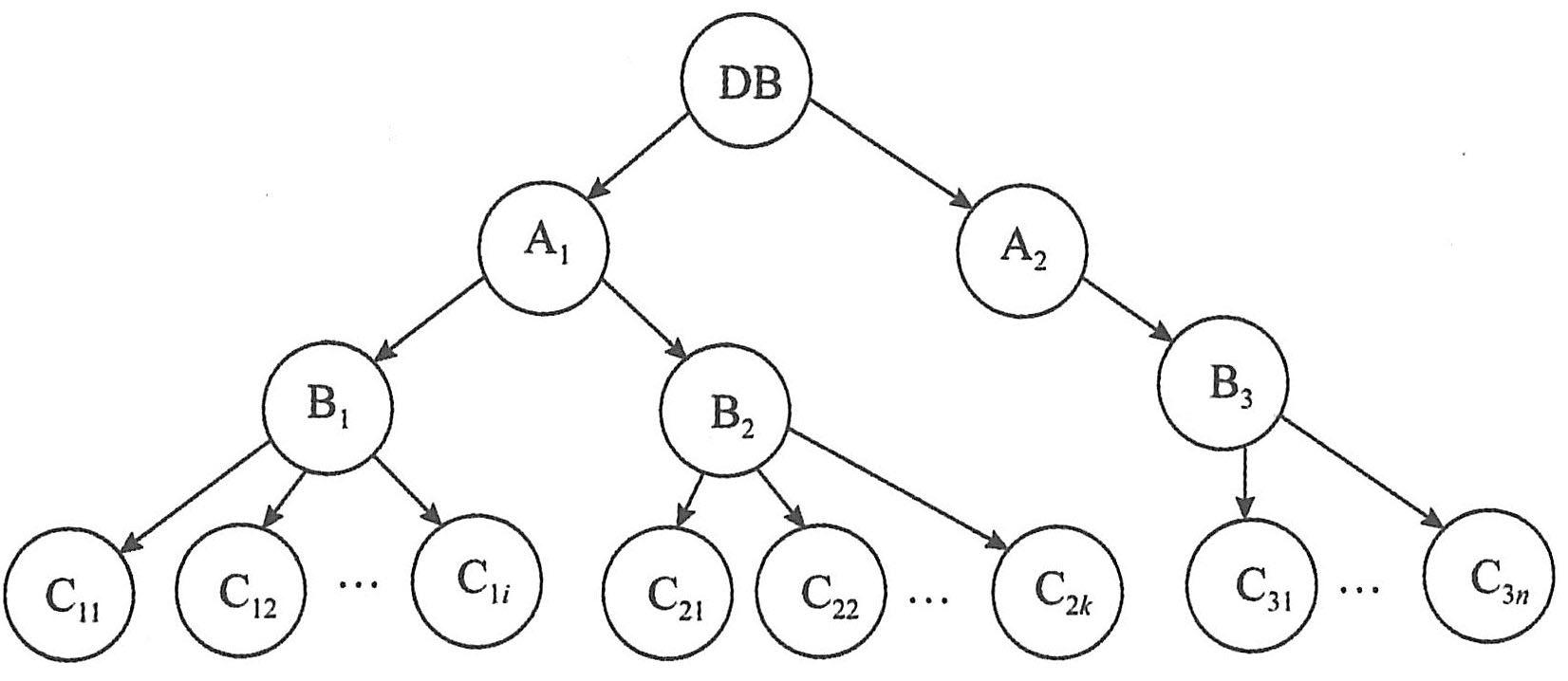
例如,考虑一个由四层结点构成的多粒度树,该粒度树包括:根结点、区域类型结点、文件类型结点和记录类型结点,如下图所示。
|
|
|
|
|
|
|
|
最高层是根结点,表示整个数据库,其下的结点是区域类型结点,而数据库是由这些区域组成。
|
|
|
|
第二层是区域类型结点,每个区域类型结点又以文件类型结点作为其子结点,每个区域是由这些文件类结点组成,任何文件都不能处于一个以上的区域中。
|
|
|
|
第三层是文件类型结点,文件类型结点下的是记录类型结点,文件是由作为其子结点的记录组成。
|
|
|
|
|
|
粒度树中的每个结点都可以单独加锁(共享锁或排它锁)。当一个事务对结点加锁时,那么该事务也可以同样类型的锁隐含地封锁该结点的全部后代结点。
|
|
|
|
例如,假设事务T1显式地对上图中的文件结点B2加排它锁,若事务T2要求封锁文件结点B2的后代结点C23,请分析加锁是否成功?
|
|
|
|
分析:由于事务T1显式地对文件结点B2加排它锁,则意味着事务T1隐含地对B2的后代结点C21,C22,…,C2k,加排它锁。当T2要求封锁文件结点B2的后代结点C23时,由于T1已显式地对结点B2加排它锁,意味着结点C23也加了排它锁。当事务T2发出封锁C23命令时,由于C23并没有显式加锁,系统必须从根结点到结点C23开始搜索,如果发现该路径上的某个结点的锁与要加锁的锁类型不相容,T2就必须延迟(等待)。
|
|
|
|
采用多粒度树的好处是:减少对后代结点加锁的系统代价。从上例可见,由于事务T1显式地对文件结点B2加排它锁,这样事务T1不用挨个对其后代记录结点C21,C22,…,C2k,加排它锁,从而减少了事务T1对记录结点C21,C22,…,C2k加锁的系统代价。
|
|
|
|
|
|
意向锁是与共享锁和排它锁相关联的另一种锁。假如一个结点加了共享型意向锁(IS),那么将在树的较低层进行显式封锁,可以加共享锁,但不能加排它锁;假如一个结点加了排它型意向锁(IX),那么将在树的较低层进行显式封锁,可以加排它锁或共享锁;若一个结点加了共享排它型意向锁(SIX),则以该结点为根的子树被显式地加共享锁。这些锁类型的相容函数矩阵如下图所示。
|
|
|
|
|
|
|
|
|
|
多粒度封锁协议(multiple-granularity looking protocol)允许多粒度树中的每个结点被独立地加锁,对某结点加锁意味着该结点的所有后代结点也被加了同类型的锁。
|
|
|
|
多粒度封锁协议采用这些锁(S、IS、X、IX和SIX)可以保证调度的可串行性。每个事务T,要求按如下规则对结点Q加锁:
|
|
|
|
|
|
(2)事务T必须首先封锁根结点,且可以加任意类型的锁。
|
|
|
|
(3)仅当T当前对结点Q的父结点持有IX和IS锁时,T对结点Q可加S锁或IS锁。
|
|
|
|
(4)仅当T当前对结点Q的父结点持有IX和SIX锁时,T对结点Q可加X锁、SIX锁或IX锁。
|
|
|
|
(5)仅当T未曾对任何结点解锁时,T可对结点加锁,即T是两阶段的。
|
|
|
|
(6)仅当T不持有Q的子节点的锁时,T可对结点Q解锁。
|
|
|
|
注意:多粒度封锁协议要求加锁按自顶向下(从根到叶)的顺序进行,而锁的释放则按自底向上(从叶到根)进行。
|
|
|
|
总之,并发控制的方法还有许多种。如基于时间戳协议、基于有效性检查协议、快照隔离等等,详细内容可参考相关书籍和资料,在此不做赘述。
|
|
|