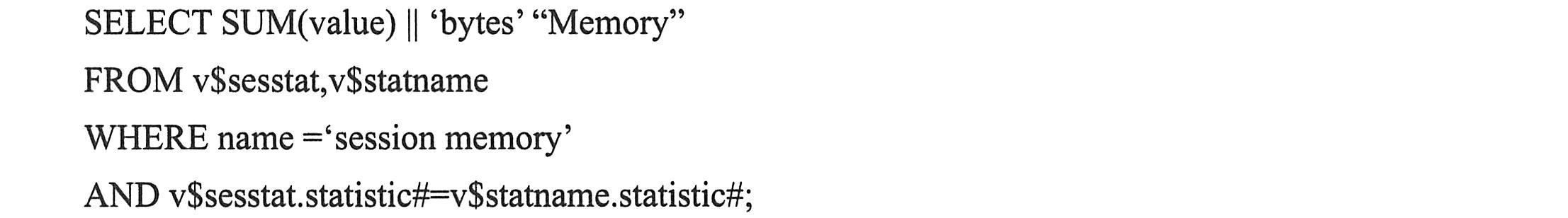|
|
知识路径: > 测试技术的分类 > 应用负载压力测试 > 负载压力测试实施 > 结果评估与测试报告 >
|
|
考试要求:掌握
相关知识点:21个
|
|
|
|
|
下面将以Oracle为例,讨论数据库优化的一些方法,对于其他的数据库,由于其实现的机制以及特性可能与Oracle不同,那么优化的方法也会有所不同,大家可以参照其手册,进行分析。
|
|
|
|
虽然这些方法属于数据库开发人员或者数据库管理人员优化系统的方法,但是如果测试人员了解这些方法,就可以更好地分析、定位数据库性能问题,制定有针对性的测试用例。
|
|
|
|
Oracle与提高性能有关的特性主要包括:索引、并行执行、簇与散列簇、分区、多线程服务器以及同时读取多块数据等。下面分别进行介绍。
|
|
|
|
这里列出了Oracle配置的关键参数以及其使用方法。
|
|
|
|
①max_dspatchers:指定了系统允许同时进行的调度进程的最大数量。
|
|
|
|
②max_shared_servers:指定了系统允许同时进行的共享服务器进程的最大数量。如果系统中出现的人为死锁过于频繁,那么管理员应该增大这个参数的值。
|
|
|
|
③parallel_adaptive_multi_user:当该参数的值为true时,系统将启动一个能提高使用并行执行的多用户系统性能的自适应算法。这个算法将根据查询开始时的系统负载自动降低查询请求的并行度。
|
|
|
|
④parallel_automatic_enabled:如果将该参数的值设置为true,那么Oracle将确定控制并行执行的参数的默认值。
|
|
|
|
⑤parllel_broadcast_enabled:该参数允许管理员提高散列连接和合并连接操作的性能,在这样的连接操作中,系统将一个大尺寸的结果集与一个小尺寸的结果集连接在一起(在合并操作中,数据的尺寸是根据字节数而不是记录数确定的)。
|
|
|
|
⑥parllel_execution_message_size:这个参数指定了系统并行执行时的消息尺寸(在Oracle的旧版本中,这个概念是指并行查询、PDML、并行恢复和并行复制数据等)。
|
|
|
|
⑦parllel_max_servers:指定了实例能同时运行的并行执行进程和并行恢复进程的最大数量。随着用户需求的增长,在创建实例时,为这个参数设置的值将不再能满足用户需求,所以应当增大这个参数的值。
|
|
|
|
⑧ parllel_min_percent:系统将联合使用parllel_max_servers、parllel_min_servers和该参数。这个参数允许指定并行执行进程(即参数parllel_max_servers之值)的最小百分比。
|
|
|
|
⑨parllel_min_servers:这个参数指定了实例并行执行进程的最小数量。其值就是实例启动时Oracle创建的并行执行进程数。
|
|
|
|
⑩parllel_threads_per_cpu:指定了实例默认的并行度和并行自适应以及负载平衡算法。它指明了并行执行过程中一个CPU能处理的进程或线程数。
|
|
|
|
?partition_view_enabled:指定了优化器是否使用分区视图。Oracle推荐用户使用分区表(这是在Oracle8之后引入的)而不是分区视图。分区视图只是为了提供Oracle的后向兼容性。
|
|
|
|
?revovery_parallelism:这个参数指定了恢复数据库系统时使用的进程数。
|
|
|
|
|
|
在数据库系统中,索引是一种可选结构,其目的是提高数据访问速度。利用索引可提高用户访问数据的速度,或直接从索引中独立检索数据。如果对索引的配置和使用进行了优化,那么索引能大大降低数据文件的I/O操作并提高系统性能。
|
|
|
|
但是在为一个表创建索引之后,Oracle将自动维护这个索引。当用户在表中插入、更新或删除记录时,系统将自动更新与该表相关的索引。一个表可以有任意数量的索引,但一个表的索引越多,用户在该表中插入、更新或删除记录时所造成的系统开销也越大。其原因是无论何时更新表,系统都必须更新与之相关的索引。
|
|
|
|
索引是建立在表的一个或多个字段之上的。索引的作用大小取决于该字段或字段集的选择性。所谓选择性,是指索引能降低数据集中的程度。如果表中与某个索引相关的字段值各不相同,那么该索引就有很好的选择性。一个选择性很差的索引的例子,是基于字段值仅为true/false的字段创建的索引,因为表中很多记录该字段的字段值都相同。一个索引可能只能帮助管理员降低检索的记录数,而不能惟一地确定一条记录。例如:如果为一个表的LastName字段创建了一个索引,现在用户需要搜索John Smith,那么这个索引将返回LastName字段值为Smith的所有记录,因而用户还不得不在返回的记录中搜索含John的记录。索引的选择性越好,就越有助于降低返回记录的数量,从而提高数据访问速度。下面介绍有效创建和使用索引的技巧和方法。
|
|
|
|
|
|
索引的主要作用之一就是降低系统处理的数据量。对CPU使用和等待完成I/O操作的时间上,I/O操作引起的系统开销都是非常昂贵的。降低I/O操作可提高系统性能和处理能力。如果不使用索引,那么为了找到特定的数据,系统将不得不扫描表中的所有数据。
|
|
|
|
|
|
|
|
如果不使用索引,系统必须扫描整个emp表并检查表中每条记录的employee_id字段的值。如果emp表很大,那么这个操作可能意味着数量巨大的I/O读写和很长的处理时间。
|
|
|
|
如果为emp表的employee_id字段创建了索引,那么系统将遍历该索引并找到用户所查询记录的ID。找到记录ID之后,只需一条额外的I/O操作就能检索到用户所需的数据。
|
|
|
|
用于说明这个问题的最好例子,是只需查找一条记录的情况。在表的每条记录中,类似employee_id这样的字段的值可能在整个表中都是惟一的。这意味着查询结果值返回一条记录,这种查询的效率是非常高的。
|
|
|
|
在某些情况下,索引必须返回大量数据。如下面的例子:
|
|
|
|
|
|
这个查询语句很可能返回大量数据,因为索引操作返回了大量记录的ID,并且系统必须独立访问这些记录的ID,所以这种情况下,不使用索引可能比使用索引的效率更高,直接进行表扫描可能效率更高。不同情况下,采用哪种查寻方法更好,很大程度上取决于表的数据量和组织形式。
|
|
|
|
对于不同的数据,在某些情况下位图索引可能非常有用,而在另外一些情况下,使用位图索引可能没有任何好处。
|
|
|
|
|
|
如果对表创建了索引,那么更新、插入和删除表中的记录都将导致额外的系统开销。在系统提交这些操作之前,系统将会更新所有与该表相关的索引。这可能需要花费很长时间,并额外增加一定的系统开销。
|
|
|
|
|
|
在某些情况下,表中的某些字段的选择性可能很低。开发人员没必要为所有表创建索引,实事上,在某些情况下索引引起的问题比解决的问题更多。在很多情况下,需要反复试验,才能确定一个索引是否有助于提高系统性能。
|
|
|
|
但是,位图索引能在字段选择性不高的情况下工作得很好。一个位图索引可以和其他位图索引联合使用,以降低系统检索的数据集。对于某些值为true/false、yes/no或其他小范围数据的字段,建立位图索引是非常合适的。请记住:位图索引所占用的空间,是随着与该索引相关的字段的不同值的数量的增加而增加的。
|
|
|
|
如果决定创建一个索引,那么确定为哪些字段创建索引是非常重要的。对于不同的表,可能会选择一个或多个字段创建索引。可使用如下方法来确定在哪些字段上创建索引:
|
|
|
|
①选择那些最常出现在where子句中的字段。经常被访问的字段最可能受益于索引。
|
|
|
|
|
|
③必须注意索引导致的查询语句性能的提高与更新数据时性能的降低之间的平衡。
|
|
|
|
④经常被修改的字段不适合创建索引,其原因是,更新索引将增加系统开销。
|
|
|
|
在某些情况下,使用复合索引的效率可能比使用简单索引的效率更高。下面的一些例子说明了应当在何种情况下使用复合索引。
|
|
|
|
①某两个字段单独来看都不具有惟一性,但结合在一起却有惟一性,那么这种情况下,复合索引将工作得很好。例如:A字段和B字段都几乎没有惟一性值,但绝大多数情况下,字段A和B的某个特定组合却具有惟一性特点。那么在检索数据时,可在where子句重视and操作符来将这两个字段连接在一起。
|
|
|
|
②如果select语句中的所有值都位于复合索引中,那么Oracle将不会检索表,而直接从索引中返回数据。
|
|
|
|
③如果多个查询语句的where子句中作为查询条件的字段都不相同,但返回的记录相同,那么应当考虑利用这些字段创建一个复合索引。
|
|
|
|
在创建索引之后,开发人员应当定期利用SQL TRACE工具或EXPLAIN PLAN来察看用户查询是否充分利用了索引。很有必要花费一定精力来试验使用索引和未使用索引在效率上的差别,以判断索引所耗费资源是否物有所值。
|
|
|
|
应该删除那些不经常使用的索引。可使用alter index monitoring usage语句来跟踪索引的使用情况。还可以从系统表all_indexes、user_indexes和dba_indexes中查询用户访问索引的频率。
|
|
|
|
如果为一个不适合创建索引的字段或表创建了索引,那么这可能会导致系统能力的下降。而如果创建的索引合理,那么这将降低系统的I/O操作并加快访问速度,从而大大提高系统性能。
|
|
|
|
|
|
Oracle9i的并行执行特性就是Oracle旧版本中读者熟知的并行查询选项。而在Oracle9i中,这个特性已内嵌在Oracle RDBMS中。
|
|
|
|
为什么要实现并行执行?RDBMS的绝大多数操作都可分为以下3类:
|
|
|
|
①被CPU限制的操作:这类操作的速度和单CPU运行速度一样。通过并行化操作,多个CPU可并行处理系统负载,因此可以更快完成该操作。
|
|
|
|
②被I/O限制的操作:这类操作花费了绝大部分时间等待系统完成I/O操作。当系统中同时出现多个I/O请求时,绝大多数raid控制器将很好地工作。另外,当一个线程需要等待完成I/O操作时,可充分利用CPU来处理另一线程的CPU部分。
|
|
|
|
③被竞争限制的操作:并行处理不能改善由资源竞争所限制的操作。
|
|
|
|
对表扫描而言,系统花费在等待数据从磁盘返回的时间常常比处理数据所花费的时间还长。通过并行机制,可用多个服务器进程处理查询操作,从而弥补了系统在这方面的问题。当一个进程在等待I/O操作时,CPU可执行另一个进程。如果数据库系统运行在对称多处理器(Symmetric Multiprocessor, SMP)计算机、计算机群集或大规模并行处理(Massive Parallel Processing, MMP)计算机上,那么开发人员可充分利用并行处理机制的优势。
|
|
|
|
并行执行使Oracle的某些功能由多个服务器进程协同处理成为可能。这些功能包括查询、创建索引、加载数据和恢复数据库。所有这些功能都遵循一个共同规则,即充分利用CPU资源。
|
|
|
|
|
|
并行查询处理允许多个服务器进程以并行方式处理某些Oracle语句。
|
|
|
|
并行查询操作将该查询分为几个不同的部分,每部分由不同的服务器进程进行处理。这些进程称为查询服务器。一个被称为“查询协调者”的进程负责调度这些查询服务器。系统将一个SQL语句和一个并行度提交给查询协调进程,而协调进程则负责将该查询分配给查询服务器,并将每个查询服务器返回的结果组合成一个整体。并行度是指分配给该查询的查询服务器数量。Oracle服务器能对连续、排序以及表扫描操作实现并行执行。
|
|
|
|
在多处理器或并行处理计算机上,并行查询操作是非常有效的;在单处理器计算机上,如果大部分时间都花在了等待系统完成I/O操作上,那么使用并行查询也是非常有效的。具有足够I/O带宽的系统,尤其是使用磁盘阵列的系统,都能够从并行查询操作中受益。
|
|
|
|
如果通常情况下系统CPU的使用率达到了100%,并且系统中只有少量磁盘驱动器,那么使用并行查询是没什么意义的。同样,如果系统的内存非常紧张,那么并行查询也没有多大意义。
|
|
|
|
在并行查询中,合理的I/O分布和并行度是最需要调整的两个方面。对并行度的调整一方面需要反复的试验,另一方面还需要一定的分析。应当首先根据如下一些因素考虑并行度。
|
|
|
|
①计算机的CPU能力:CPU的数量和能力将影响系统能运行的查询进程数量。
|
|
|
|
②系统处理大量进程的能力:一些操作系统能处理很多并发进程,而另一些操作系统则没有这方面的能力。
|
|
|
|
③系统负载:如果系统现在的运行已经达到了极限,那么对并行度的调整不会有太大效果。如果系统运行已达其能力极限的90%,那么太多的查询进程将使系统不堪重负。
|
|
|
|
④系统处理的查询数量:如果系统的大部分操作是更新操作,但仍有少量的重要查询存在,那么开发人员可能希望系统运行多个查询进程。
|
|
|
|
⑤系统的I/O能力:如果磁盘上的数据是分片或是使用磁盘阵列存储的,那么系统能够处理多个并行查询。
|
|
|
|
⑥操作类型:系统是否需要处理很多的全表扫描或排序?并行查询服务器非常有助于这类操作。
|
|
|
|
这些因素对系统采用的查询并行度有一定影响。下面是关于并行度的另一些建议。
|
|
|
|
①诸如排序之类的,需要大量CPU资源的操作应当采用较低的并行度。其原因是这类受限于CPU的操作已经充分利用了CPU,而不需等待系统的I/O操作。
|
|
|
|
②诸如全表扫描之类的,需要大量磁盘I/O的操作,应当采用较高的并行度。需要等待磁盘I/O的操作越多,系统就越能受益于并行操作。
|
|
|
|
③如果系统中有大量的并发进程,那么应当采用较低的并行度。因为太多的进程将使系统不堪重负。
|
|
|
|
在确定使用并行操作之后,读者可通过查询动态性能视图V$PQ_SYSSTAT来监控系统。
|
|
|
|
|
|
并行查询的另一个特征是以并行方式创建索引的能力。通过这个特性,系统用于创建索引的时间将大大减少。类似于并行查询操作,并行创建索引操作也有两组查询服务器。其中一组查询服务器的功能是扫描需要创建索引的表,以获得ROWID和与索引相关的字段值;另一组查询服务器则对第一组查询服务器所得到的值进行排序,并将排序后的结果传递给协调进程。而协调进程再根据这些排序之后的条目创建B树索引。
|
|
|
|
|
|
通过使用多个并发会话同时往同一个表中写数据,可实现数据加载的并行化。对于不同的系统配置,通过并行方式加载数据,可以提高数据加载性能。因为加载数据不仅需要大量的CPU资源而且还需要大量的I/O操作,所以并行化数据加载将提高数据加载的性能。并行化数据加载将通过多个直接加载器进程实现。
|
|
|
|
并行加载数据是非常有用的,特别是在数据加载时间很紧张的环境中尤其如此。通过将每个输入文件放置在不同的卷上,可提高并行加载数据的性能。并行查询操作中所有的通用调整原则都是用于并行加载数据操作的。
|
|
|
|
|
|
并行恢复是并行查询选项的一个非常重要的特性。在评估Oracle和测试软硬件时,需要有意地使系统崩溃,以检验系统的可恢复性。通过使用并行恢复选项,恢复数据库和实例的时间将大大缩短。当被恢复的系统有很多磁盘并支持异步I/O操作时,系统恢复所用的时间将会大大缩短。对于只有很少磁盘的小系统或不支持异步I/O的系统,采用并行方式恢复系统是不明智的。在并行恢复方式中,一个进程负责从重做日志中读取和调度重做入口,并将这些入口传递给恢复进程。而恢复进程则负责将用户对数据库所作的修改写进数据库中。
|
|
|
|
总之,在平衡操作负载方面并行查询选项是非常有用的,当其他进程在等待系统完成I/O操作时,并行查询可使CPU转而处理其他进程,从而充分利用系统的CPU资源。对于多处理器计算机,使用并行查询是非常有用的,但这并不是说并行查询不能用于单处理器计算机。
|
|
|
|
|
|
簇(cluster),有时被称为索引簇,是Oracle数据库中用于存储表的一种方法。在一个簇中,系统将多个相关的表存储在一起,以缩短用户访问相关记录的时间。只有当这些相关表经常被同时访问时,才适合使用簇。对用户和应用程序而言,簇的存在是透明的,簇只影响数据的存储方式。
|
|
|
|
在某些情况下使用簇是非常有利的,而在另外一些情况下,使用簇却可能非常不利。应当仔细考虑簇是否有助于提高系统性能。一般而言,如果集中存放的数据主要用于连接表中,那么使用簇是很好的。如果两个表存放了相关数据,并且这两个表经常被同时访问,那么通过使用簇可将相关数据预装入SGA中,从而提高用户访问数据的性能。因为开发人员经常同时使用这两个表,所以在用户访问其中一个表时,将另一个表的数据也放入SGA中,可大大缩短用户访问数据的时间。如果一般情况下开发人员不会同时使用这些信息,那么簇将不能提高系统性能,并且这种情况下,簇实际上会导致系统性能的轻微下降,其原因是额外的表信息将占据更多的SGA空间。簇的另一个不足之处在于,当用户执行insert语句时将降低系统性能。引起性能下降的原因是簇在使用存储空间上采用的方法更加复杂,并且系统需要将多个表存储在同一个数据块中。簇表比单个表占用了更多的存储空间,这将导致系统扫描更多的数据。另外如果系统经常对这些表中的某一个表作全表扫描,那么不应当为这些表创建簇。因为如果创建了簇,那么额外数据将占用SGA的部分空间并导致额外的I/O操作,这两方面的原因都会降低系统性能。
|
|
|
|
|
|
散列簇和簇非常相似,但散列簇采用散列函数而不是索引访问簇键。散列簇根据散列函数的计算结果保存数据。散列函数是一个数学函数,这个函数根据散列键的值来确定簇中的数据块。
|
|
|
|
尽管可以以类似于索引簇的方式创建散列簇,但不必为所有表创建散列簇。实际上,更经常做的是为一个单独的表创建散列簇,以利用散列簇的特性。通过使用散列索引,系统只需一次I/O操作,系统就能检索到用户所需数据,如果使用B索引,系统需要多次I/O操作才能检索到需要的数据。适合创建散列簇的表应具有以下特征:
|
|
|
|
|
|
|
|
|
|
|
|
一个适合于创建散列簇的典型例子是一个用于存储零件信息的表。通过建立一个关于零件号的散列键值,用户对该表的访问将非常有效而且非常快。任何时候,如果系统中有一个静态的表,其中的一个或多个字段的值具有惟一性特征,那么可考虑为这样的表创建散列簇。
|
|
|
|
和索引簇一样,使用散列簇既有优点也有不足。当用户使用关于簇键的等式查询检索数据时,散列簇具有很高的效率。如果用户不是根据簇键值检索数据,那么这个查询就不能被散列化。这就像在索引簇中见到的那样,当在散列簇表中使用insert语句时,将降低系统性能。
|
|
|
|
|
|
当系统执行表扫描时,Oracle具备同时读取多个数据块的能力,这种能力提高了系统的I/O速度。通过同时读取多块数据,Oracle能够从磁盘上读取更大的数据块,从而避免了对磁盘上数据进行搜索的操作。通过降低磁盘搜索和读取更大的数据块,可以降低系统的I/O开销和CPU开销。
|
|
|
|
Oracle的这个特性被称为多块读取。只有对于连续数据块,多块读取特性才有助于提高系统性能。通常情况下,一个盘区内的数据块都是连续的。如果数据存放在多个小盘区上,那么多块读取的性能将会降低。
|
|
|
|
Oracle初始化参数db-file-multiblock-read-count指定了一次多块读取能读取的数据量。因为这个参数几乎不会导致系统性能的下降,所以一般情况下,都将这个参数的值设置得很高。I/O的尺寸取决于初始化参数db-file-multiblock-read-count和db-block-size的值。
|
|
|
|
为了充分发挥多块读取数据的优势,应当尽量配置自己的系统以使数据库的块尽可能都是连续的。为了做到这一点,应当使用优化尺寸的盘区来创建数据库。盘区的尺寸应当远大于一次多块读取操作所读取的数据的尺寸。
|
|
|
|
|
|
分区(partition)这一特性的目的是允许大尺寸表或索引分解成小的更容易管理的部分,即分区。与原来的表或索引相比,因为分区变小了,所以系统访问分区的速度更快、效率也更高,可将分区想象成表或索引被分解之后的多个小尺寸的表或索引。系统可单独访问这些小尺寸的表或索引,也可以以组或整体方式访问之。
|
|
|
|
可使用多种分区方案来创建分区。这些方案确定了如何将数据分解成分区。可使用如下一些方案。
|
|
|
|
. Range Partitioning:这种方案根据数据的范围,比如月、年等对表中的数据进行分区。
|
|
|
|
. List Partitioning:这种方案和Range Partitioning分区方案很类似,但这种方案是按照数据的值,而不是数据的范围来进行划分的。
|
|
|
|
. Hash Partitioning:这种分区方案使用散列函数来实现对数据的自动分区。
|
|
|
|
. Sub-Partitioning:这种方法就是开发人员熟悉的复合分区方法。这种方法允许开发人员同时使用多种分区方案。
|
|
|
|
|
|
. 对能被分区的大尺寸表进行扫描时,分区可降低I/O操作和CPU的使用率。
|
|
|
|
|
|
. 能以删除分区的方式删除数据,而不必使用select语句来删除大量数据。
|
|
|
|
|
|
|
|
|
|
|
|
用户可通过专用服务器进程连接到Oracle实例,也可以通过多线程服务器进程连接到Oracle实例。因为每一个专用服务器进程都将占用大量内存资源和系统资源,所以有必要对多用户连接采用多线程服务器进程。
|
|
|
|
多线程服务器进程允许多个用户使用一定数量的共享服务器进程。所有对共享服务器的请求都必须经过调度进程,这个过程对SGA大缓冲池中的用户对共享服务器进程的请求进行排队。当系统处理完用户请求后,系统通过SGA中的大缓冲池将请求结果返回给调度进程。
|
|
|
|
因为共享服务器进程使用共享缓冲池对用户请求进行排队并返回数据,从而大大减少CPU和内存的使用。然而,正如读者所猜想的那样,多线程服务器也会增加系统开销。这就是为什么执行需要很长时间的批处理作业时,使用专用服务器的原因。
|
|
|
|
对配置和调整多线程服务器,需要调整参数文件中的参数。还应当小心监控系统的大缓冲池,以确保系统的运行没有超出分配给它的内存空间。
|
|
|
|
应当尽量监控只有少量用户的共享会话所使用的内存。监控结果将会告知共享会话使用了多少内存。利用这些数据,就能估算所有会话总共需要多少内存。可通过下面的SQL语句获得这些信息:
|
|
|
|
|
|
上面语句的输出结果告诉开发人员使用了多少内存。将使用的总内存量除以连接数,就可确定每个会话使用的内存数量。然后就可从每个会话使用的内存量来推算为了支持系统的所有会话,需要为系统的大缓冲池分配多大内存空间。
|
|
|
|
如果认为大缓冲池的内存太少,那么可通过调整初始化参数large_pool-size来增加大缓冲池的内存空间。请记住:除多线程服务器之外,系统还使用大缓冲池来执行并行查询操作。
|
|
|
|
初始化参数mts_dispatchers决定了每个网络协议使用的调度进程的数量。通过提高这个参数的值,可能会看到用户会话的性能得到了提高,其原因是用户会话不再需要等待可用调度进程。
|
|
|
|
除前面讨论的参数之外,还有如下一些参数与多线程服务器有关。
|
|
|
|
. mts_max-dispatcher:实例能创建的调度进程的最大数量。这里的调度进程包括所有网络协议的调度进程。
|
|
|
|
. mts_servers:实例刚启动时的共享服务器进程数。如果将这个参数设置为0,那么Oracle将不会是用共享服务器进程。为了满足系统需要,共享服务器进程的数量将会动态增长。
|
|
|
|
. mtx_max_servers:这个参数指定了实例中允许运行的共享服务器进程的最大数量。
|
|
|
|
如果应用程序能利用簇和索引的优势,那么簇和索引将有助于提高系统性能。如果应用程序使用了索引而又需要频繁更新数据,那么这样的索引将会降低系统性能,其原因是在数据更新的同时,系统也需要更新索引。同样地,如果用户的数据访问模式使用了簇,那么簇将会有助于提高系统性能;反之,簇将会成为系统的负担。
|
|
|
|
Oracle并行查询选项和并行服务器选项能极大地提高系统性能。通过将查询分配成多个服务器进程,并行查询选项提供了一种提高系统CPU使用率的机制。并行服务器为开发人员提供了一个健壮的可升级的服务器群集功能,这个特性不仅能提高系统性能,还为系统提供了立即排除错误的能力。应用程序和需求将决定这些特性是否有助于提高系统性能。在调整系统时,非常重要的一点是需要注意调整系统所冒的风险。在前面的内容介绍中,我们讨论了不同的系统调整主体,例如共享内存池的尺寸和数据块缓冲区等。提高共享内存池和数据库缓冲区的尺寸将会提高缓冲区的命中率,但这样的调整也存在着损害系统性能的风险。然而,如果读者对某些系统特性配置得不正确,那么它们对系统性能造成的负面影响会更大。任何时候调整系统,都应当预先估计该调整所面临的风险,特别是在没经过详细测试就对生产系统进行调整时更是如此。
|
|
|
|
如果对系统需要调整的方面和该调整所影响的方面进行了仔细考虑,并对应用程序的数据访问模式有深入的了解,那么可以将调整面临的风险降到最小。应当仔细考虑对系统所作的修改将会对系统造成的影响,并尽量了解系统修改对应用程序的影响。只有这样,才能在优化系统性能的同时,将系统调整的风险降到最低。
|
|
|