|
|
|
初等数学基础知识主要涉及数据的简单统计、常用的统计图表和常用的统计函数,是历年考试的必考部分。根据历年考试该部分的试题分值基本在4~6分之间,为了保证科目成绩过关,考生应该重视这部分内容的学习。
|
|
|
|
|
|
随着社会、经济和科学技术的飞速发展,统计在现代化国家管理、企业管理和社会生活中的地位越来越重要,在人们的日常生活和社会生活中都离不开统计。例如,公司的营销情况、员工的业绩与薪资情况、学生的成绩情况都需要用统计知识来解决。
|
|
|
|
统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进一步进行推断和预测,为相关决策提供依据和参考。它被广泛地应用在各门学科中,从物理和社会科学到人文科学,甚至被用于工商业以及政府的情报决策之中。
|
|
|
|
|
|
总体是指考查对象的全体,通常也称为母体。个体是总体中的每一个考查对象。样本是总体中所抽取的一部分个体。样本容量是指样本中个体的数目。样本容量又称为“样本数”,指一个样本的必要抽样单位数目。在组织抽样调查时,抽样误差的大小直接影响样本指标代表性的大小,而必要的样本单位数目是保证抽样误差不超过某一给定范围的重要因素之一。
|
|
|
|
|
|
平均数是指在一组数据中所有数据之和再除以数据的个数。平均数是表示一组数据集中趋势的量数,它是反映数据集中趋势的一项指标。解答平均数应用题的关键在于确定“总数量”以及和总数量对应的总份数。常用的平均数指标有位置平均数和数值平均数。
|
|
|
|
|
|
位置平均数是指按数据的大小顺序或出现频数的多少确定的集中趋势的代表值,主要有众数、中位数等。
|
|
|
|
众数是一组数据中出现次数最多的数值,有时众数在一组数中有好几个,用M表示。简单地说,就是一组数据中占比例最多的那个数。用众数代表一组数据。可靠性较差,不过众数不受极端数据的影响,并且求法简便。
|
|
|
|
中位数是一组数据按从小到大的顺序依次排列,处在中间位置的一个数,或最中间两个数据的平均数。注意,和众数不同,中位数不一定在这组数据中。中位数是样本数据所占频率的等分线,它不受少数几个极端值的影响,因此有时也会成为其优点。在一组数据中,如果个别数据有很大的变动,选择中位数表示这组数据的“集中趋势”是更为适合的。
|
|
|
|
|
|
数值平均数是以统计数列的所有各项数据来计算平均数,用以反映统计数列的所有各项数值的平均水平。这类平均数的特点是统计数列中任何一项数据的变动,或大或小都会在一定程度上影响到数值平均数的计算结果。数值平均数又由于计算方法不同,分为算术平均数、调和平均数和几何平均数。
|
|
|
|
①算术平均数。把n个数的总和除以n所得的商叫做这n个数的平均数,它是反映数据集中趋势的一项指标。
|
|
|
|
②几何平均数。把n个观察值连乘积的n次方根就是几何平均数。根据资料的条件不同,几何平均数有加权和不加权之分。
|
|
|
|
|
|
③调和平均数。平均数的一种,对于统计调和平均数与数学调和平均数不同。数学调和平均数定义为:数值倒数的平均数的倒数。统计加权调和平均数是加权算术平均数的变形,主要是用来解决在无法掌握总体单位数(频数)的情况下,只有每组的变量值和相应的标志总量,而需要求得平均数的情况下使用的一种数据方法。
|
|
|
|
|
|
调和平均数与算术平均数的区别是变量与权数不同。对于算术平均数的变量是x,调和平均数的变量是1/x。算术平均数的权数是f或n,代表次数(单位数);调和平均数是xf或M,代表标志总量。
|
|
|
|
调和平均数与算术平均数的联系是调和平均数可以作为算术平均数的变形使用。
|
|
|
因为
|
|
|
所以
|
|
|
令M=xf则
|
|
|
|
|
|
统计图表是统计描述的重要工具,是实际工作中一种常用的方法。它可以取代冗长的文字叙述,以直观形象地反映事物之间的关系。
|
|
|
|
|
|
统计表(statistical table)是从整理表中选出需要的资料,经过统计加工为各种指标后,列成便于对比分析的表格。统计表由标题、标目及数据组成,其结构要简洁,最好一事一表,避免臃肿庞杂。常用的统计表有4种:简单表、分组表、复合表和列联表。
|
|
|
|
|
|
简单表用于比较互相独立的统计指标,主辞未经任何分组。例如,某学校要检查2011年各教学班级《计算机应用基础》课程的过关率情况,统计结果如下表所示。
|
|
|
|
|
|
|
|
标题:要求简练、用词确切,能表达中心内容,左侧有表号以备查考。
|
|
|
|
标目:有横标目和纵标目。横标目又称为主辞,是研究事物的,通常位于表内左侧;纵标目是研究事物的,又称为宾辞,列在表内上方,其表达结果与主辞呼应,读起来就是一个完整句子。例如第一行可读成“1101班60人,有5人不及格,过关率91.67%”。
|
|
|
|
数据:位置上下对齐、准确、小数点后所取位数也应上下一致。数据一般按大小顺序排列,对比鲜明,重点突出。
|
|
|
|
|
|
主辞按一个标志分组,结构形式与简单表基本相似。通常设有合计栏,以利于说明综合水平。如下表所示。
|
|
|
|
|
|
|
|
|
|
主辞按两个以上标志分组。在安排上可将部分主辞放在表的上方,与宾辞配合起来,如下表所示。对于复合表是否需要合计应从合计是否有意义来决定。
|
|
|
|
|
|
|
|
|
|
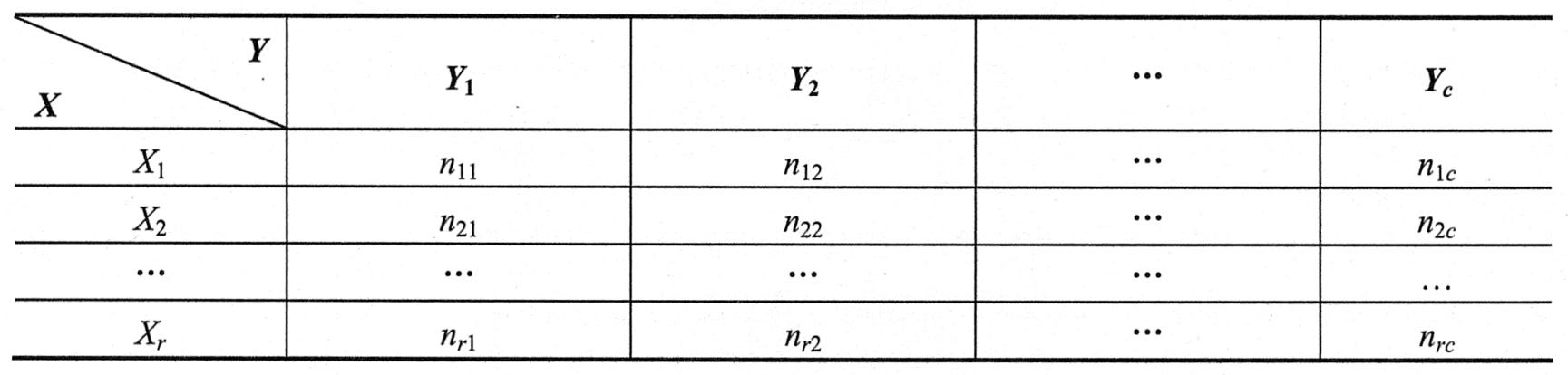
列联表可以用列表方式表示两个(或多个)变量(或属性)分类时所列出的频数。若总体中的个体可按两个变量X与Y分类,Xi(i=1,2,3,…,r)表示行变量X的第i个类别,Yj(j=1,2,3,…,c)表示列变量Y的第j个类别,设nij为每种组合的频次,将r×c个nij排列为一个r行c列的二维列联表,简称r×c列联表。其结构如下表所示。
|
|
|
|
|
|
|
|
|
|
统计图(statistical diagram)一般是根据统计表的资料,用点、线、面或立体图像鲜明地表达其数量或变化动态。常用统计图的类型有线图、直方图、直条图和饼形图等。
|
|
|
|
线图(line diagram)适用于连续变量资料。说明某事物因时间、条件推移而变迁的趋势。横轴常用以表示某事物的连续变量,纵轴多表示率、频率或均数。
|
|
|
|
直方图(histogram)是以面积表示数量,适用于表达连续性资料的频数或频率分布。横轴表示变量,尺度可以从0或其他值开始。但同一轴上的尺度必须相等。
|
|
|
|
直条图(bar chart)是用等宽直条和长短来表示各统计量的大小,适用于彼此独立的资料互相比较,有单式和复式两种。作图时,一般是以横轴为直条图的基线,纵轴表示频数或频度,从0开始。直条间的距离一般以条宽的1/2为宜。排列顺序若非自然顺序资料,则按由高到低的次序排列,便于比较。
|
|
|
|
复式直条图的制图要求与单式相同,但每组的直条最好不要过多,同组直条间不留空隙,组内各直条排列次序要前后一致。
|
|
|
|
百分条图(percentchart)用以表达构成比的图形,绘制简便,而且可将多条并列作比较,以阐明比较对象的变化情况。
|
|
|
|
饼形图(circulargraph)的用途同百分条图,是以圆的半径将圆面分割成多个大小不等的扇形来表达构成比。作图法是先将各个百分比乘以3.60,获得圆心角度数,按其大小排列从0开始,且量角器顺时针方向划分为一系列扇形。
|
|
|
|
点图(scatterdiagram)表示两种事物变量的相关性和趋势。绘制方法是先绘出合适的坐标,一般以两轴正交点为0点,但也可按两变量的全距中最小值起点加以调整。x变量定在横轴,y变量定在纵轴。然后测得两变量值,找出P(x,y)所在的方位,并绘出各自的坐标点。最后根据点的分布情况进行分析。
|
|
|
|
|
|
常用的统计函数包括求总和、平均值、最大值、最小值、标准差等。Excel常用的统计函数如下。
|
|
|
|
|
|
用途:计算平均值。语法:AVERAGE(number1,number2,…)。参数:number1,number2,…是要计算平均值的参数。例如,AVERAGE(A1:A15)是计算A1~A15单元格的平均数。
|
|
|
|
|
|
用途:返回数字参数的个数。它可以统计数组或单元格区域中含有数字的单元格个数。语法:COUNT(value1,value2,…)。参数:value1,value2,…是包含或引用各种类型数据的参数,其中只有数字类型的数据才能被统计。例如,A1=20、A2=刘明、A3=18、A4=54、A5="",则公式“=COUNT(A1:A5)”的结果为3。
|
|
|
|
|
|
用途:返回参数组中非空值的数目。利用函数COUNTA可以计算数组或单元格区域中数据项的个数。语法:COUNTA(value1,value2,…)。说明:value1,value2,…是所要计数的参数,在这种情况下的参数可以是任何类型,它们包括空格,但不包括空白单元格。例如,A1=566、A2=800.114,其余单元格为空,则公式“=COUNTA(A1:A7)”的计算结果等于2。
|
|
|
|
|
|
用途:计算某个单元格区域中空白单元格的数目。语法:COUNTBLANK(range)。参数:range为需要计算其中空白单元格数目的区域。例如,A1=33、A2=66、A3=""、A4=99、A5="",则公式“=COUNTBLANK(A1:A5)”的计算结果等于2。
|
|
|
|
|
|
用途:计算区域中满足给定条件的单元格个数。语法:COUNTIF(range,criteria)。参数:range为需要计算其中满足条件的单元格数目的单元格区域。criteria为确定哪些单元格将被计算在内的条件,其形式可以为数字、表达式或文本。
|
|
|
|
|
|
用途:返回某一数据集中的某个最大值。可以使用LARGE函数查询考试分数集中第一、第二、第三等的得分。语法:LARGE(array,k)。参数:Array为需要从中查询第k个最大值的数组或数据区域,k为返回值在数组或数据单元格区域里的位置(即名次)。例如,B1=66、B2=30、B3=68、B4=86、B5=78、B6=84、B7=88,则公式“=LARGE(B1,B7,2)”返回86。
|
|
|
|
|
|
用途:返回数据集中的最大数值。语法:MAX(number1,number2,…)。参数:Number1,number2,…是需要找出最大数值的参数。例如,B1=66、B2=30、B3=68、B4=86、B5=78、B6=84、B7=88,则公式“=MAX(B1:B7)”返回88。
|
|
|
|
|
|
用途:返回数据集中的最大数值。它与MAX的区别在于文本值和逻辑值(如TRUE和FALSE)作为数字参与计算。语法:MAXA(value1,value2,…)。参数:value1,value2,…为需要从中查找最大数值的参数。例如,A1:A5包含0、0.2、0.5、0.4和TRUE,因为TRUE=1,FALSE=0,所以MAXA(A1:A5)返回1。
|
|
|
|
|
|
用途:返回给定参数表中的最小值。语法:MIN(number1,number2,…)。参数:number1,number2,…是要从中找出最小值的数字参数。例如,A1=71、A2=83、A3=76、A4=49、A5=92、A6=88、A7=96,则公式“=MIN(A1:A7)”返回49,而“=MIN(A1:A5,0,-8)”返回-8。
|
|
|
|
|
|
用途:返回参数清单中的最小数值。它与MIN函数的区别在于文本值和逻辑值(如TRUE和FALSE)也作为数字参与计算。语法:MINA(value1,value2,…)。参数:value1,value2,…为需要从中查找最小数值的参数。例如,A1=71、A2=83、A3=76、A4=49、A5=92、A6=88、A7=FALSE,则公式“=MINA(A1:A7)”返回0。
|
|
|
|
|
|
用途:返回在某一数组或数据区域中的众数。语法:MODE(number1,number2,…)。参数:number1,number2,…是用于众数计算的1到30个参数。例如,A1=71、A2=83、A3=71、A4=49、A5=92、A6=88,则公式“=MODE(A1:A6)”返回71。
|
|
|
|
|
|
用途:返回一个数值在一组数值中的排位(如果数据清单已经排过序了,则数值的排位就是它当前的位置)。语法:RANK(number,ref,order)。参数:number是需要计算其排位的一个数字;ref是包含一组数字的数组或引用(其中的非数值型参数将被忽略);order为一数字,指明排位的方式。如果order为0或省略,则按降序排列的数据清单进行排位。如果order不为0,ref当作按升序排列的数据清单进行排位。注意,函数RANK对重复数值的排位相同。但重复数的存在将影响后续数值的排位。如在一列整数中,若整数60出现两次,其排位为5,则61的排位为7(没有排位为6的数值)。例如,A1=80、A2=36、A3=92、A4=18、A5=88,则公式“=RANK(A1,$A$1:$A$5)”返回3、“=RANK(A2,$A$1:$A$5)”返回4、“=RANK(A3,$A$1:$A$5)”返回1、“=RANK(A4,$A$1:$A$5)”返回5、“=RANK(A5,$A$1:$A$5)”返回2。
|
|
|
|
|
|
用途:返回数据集中第k个最小值,从而得到数据集中特定位置上的数值。语法:SMALL(array,k)。参数:array是需要找到第k个最小值的数组或数字型数据区域,k为返回的数据在数组或数据区域里的位置(从小到大)。例如,A1=80、A2=36、A3=92、A4=18、A5=88,则公式“=SMALL(A1:A5,2)”返回88。
|
|
|