|
|
知识路径: > 网络与信息安全知识 > 网络与信息安全知识 > 云计算 > 云计算基础知识 >
|
|
考试要求:掌握
相关知识点:57个
|
|
|
|
|
云计算作为一种新的计算方式和服务模式,以数据为中心,是一种数据密集型的超级计算,它运用了多种计算机技术,核心的关键技术有虚拟化技术、分布式数据存储、并行计算、运营支撑管理等。
|
|
|
|
|
|
虚拟化或虚拟技术(Virtualization)是一种资源管理技术,是将计算机的各种实体资源(CPU、内存、磁盘空间、网络适配器等)予以抽象、转换后呈现出来,并可供分割、组合为一个或多个电脑配置环境。云计算中的虚拟化往往指的是系统虚拟化。
|
|
|
|
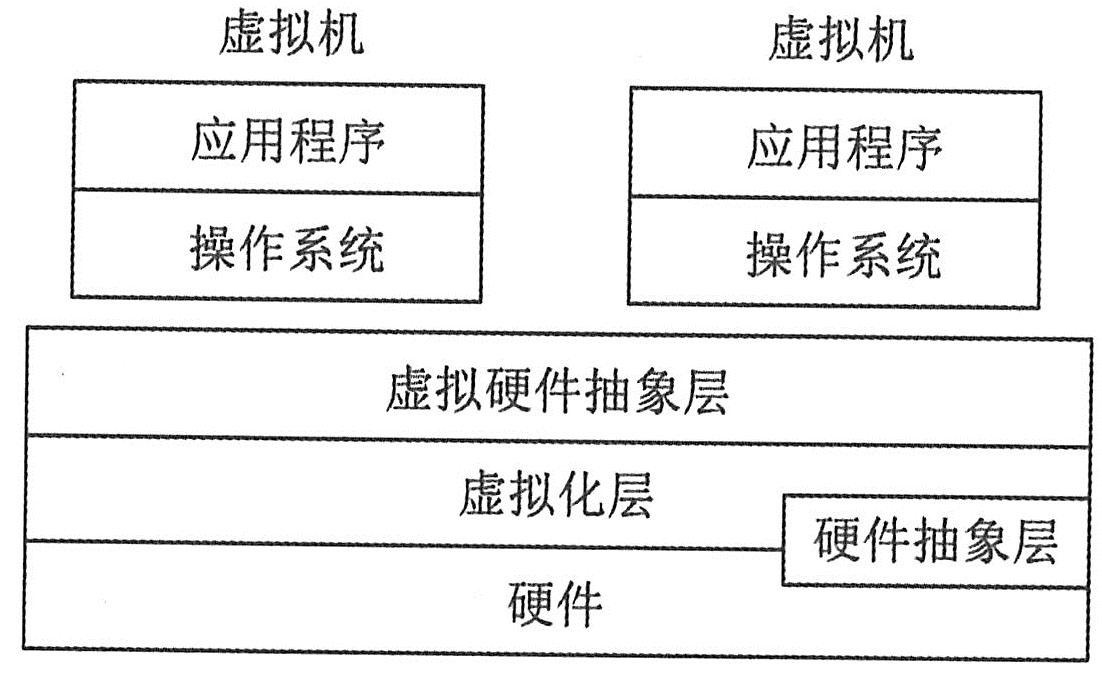
系统虚拟化是指将一台物理计算机系统虚拟化为一台或多台虚拟计算机系统。每个虚拟计算机系统(简称虚拟机)都拥有自己的虚拟硬件(如CPU、内存和设备等),来提供一个独立的虚拟机执行环境,被称为虚拟机监控器(Virtual Machine Monitor,VMM)。虚拟机基本结构如下图所示。
|
|
|
|
|
|
|
|
当前主流的虚拟化技术实现结构可以分为三类:Hypervisor模型、宿主模型和混合模型。在Hypervisor模型中,VMM可以看作是一个扩充了虚拟化功能的操作系统,对底层硬件提供物理资源的管理功能,对上层的客户机操作系统提供虚拟环境的创建和管理功能。宿主模型中,VMM作为宿主操作系统独立的内核模块。物理资源由宿主机操作系统管理,VMM提供虚拟化管理。宿主模型和Hypervisor模型的优缺点恰好相反。宿主模型的最大优点是可以充分利用现有操作系统的设备驱动程序以及其他功能,缺点是虚拟化效率较低,安全性取决于宿主操作系统。而Hypervisor模型虚拟化效率高、安全,但是需要自行开发设备驱动和其他一些功能。混合模型集成了上述两类模型的优点。混合模型中,VMM让出大部分I/O设备的控制权,将它们交由一个运行在特权虚拟机中的特权操作系统来控制。因此,混合模型下CPU和内存的虚拟化由VMM负责,而I/O虚拟化由VMM和特权操作系统共同合作完成。
|
|
|
|
|
|
分布式数据存储技术包含非结构化数据存储和结构化数据存储。其中,非结构化数据存储主要采用文件存储和对象存储技术,而结构化数据存储主要采用分布式数据库技术,特别是NoSQL数据库。
|
|
|
|
|
|
为了存储和管理云计算中的海量数据,Google提出分布式文件系统GFS(Google File System),Apache Hadoop项目的HDFS实现了GFS的开源版本。
|
|
|
|
Google GFS是一个大规模分布式文件存储系统,其设计的特点如下:
|
|
|
|
.利用多副本自动复制技术,用软件的可靠性来弥补硬件可靠性的不足。
|
|
|
|
.将元数据和用户数据分开,用单点或少量的元数据服务器进行元数据管理,大量的用户数据结点存储分块的用户数据,规模可以达到PB级。
|
|
|
|
.面向一次写多次读的数据处理应用,将存储与计算结合在一起,利用分布式文件系统中数据的位置相关性进行高效的并行计算。
|
|
|
|
GFS/HDFS非常适于进行以大文件形式存储的海量数据的并行处理。
|
|
|
|
|
|
对象存储系统是传统的块设备的延伸,具有更高的“智能”:上层通过对象ID来访问对象,而不需要了解对象的具体空间分布情况。相对于分布式文件系统,在支撑互联网服务时,对象存储系统具有如下优势:
|
|
|
|
.相对于文件系统的复杂API,分布式对象存储系统仅提供基于对象的创建、读取、更新、删除的简单接口,在使用时更方便而且语义没有歧义。
|
|
|
|
.对象分布在一个平坦的空间中,而非文件系统那样的名称空间之中,这提供了很大的管理灵活性:既可以在所有对象之上构建树状逻辑结构;也可以直接用平坦的空间;还可以只在部分对象之上构建树状逻辑结构;甚至可以在同一组对象之上构建多个名称空间。
|
|
|
|
Amazon的S3就属于对象存储服务。S3通过基于Http REST的接口进行数据访问,按照用量和流量进行计费,其他的云服务商也都提供了类似的接口服务。很多互联网服务商,如Facebook等也都构建了对象存储系统,用于存储图片、照片等小型文件。
|
|
|
|
|
|
云计算环境下,大部分应用不需要支持完整的SQL语义,而只需要Key-Value形式或略复杂的查询语义。在这样的背景下,进一步简化的各种NoSQL数据库成为云计算中的结构化数据存储的重要技术。
|
|
|
|
Google的BigTable是一个典型的分布式结构化数据存储系统。在表中,数据是以“列族”为单位组织的,列族用一个单一的键值作为索引,通过这个键值,数据和对数据的操作都可以被分布到多个结点上进行。
|
|
|
|
在开源社区中,Apache HBase使用了和BigTable类似的结构,基于Hadoop平台提供BigTable的数据模型,而Cassandra则采用了亚马逊Dynamo的基于DHT的完全分布式结构,实现更好的可扩展性。
|
|
|
|
|
|
云计算下把海量数据分布到多个结点上,将计算并行化,利用多机的计算资源,加快数据处理的速度。Google的MapReduce模型就是面向互联网数据密集型应用的并行编程模型。
|
|
|
|
云计算下的并行处理需要考虑以下关键问题,任务划分、任务调度和自动容错处理机制。
|
|
|
|
|
|
在MapReduce中,数据以块的形式存储在集群的各个结点上,每个计算任务只需处理一部分数据,这样自然地实现了海量数据的并行处理。这种简单的根据存储位置进行任务划分的方式,只适用于不存在数据依赖关系的计算。而对于存在依赖关系的计算,MapReduce将复杂的计算转化为一系列单一的Map/Reduce计算,串联起来完成多个Map/Reduce任务来实现复杂计算。
|
|
|
|
|
|
MapReduce将存储和计算资源部署在相同结点上,优先把计算任务调度到数据所在的结点或者就近的结点,这样在进行计算时,大部分的输入数据都能从本地读取,减少了网络带宽的消耗,提高了整个系统的吞吐量。另外,MapReduce对于由于各种原因(例如硬盘出错)造成执行非常慢的子任务采用了备用任务的机制,当MapReduce操作接近完成时,调度备用任务进程来执行剩下的执行非常慢的子任务。
|
|
|
|
|
|
常用恢复机制有两类:任务重做(Task Re-execute)和检查点(Checkpoint)回滚方式。这两种机制各有优缺点,前者实现非常简单,但是重做的代价比较大;后者实现较复杂,需要周期性地记录所有进程状态,但是恢复较快。MapReduce主要采用任务重做的方式来处理结点的失效。
|
|
|
|
|
|
为了支持规模巨大的云计算环境,需要成千上万台服务器来支撑。如何对数以万计的服务器进行稳定高效地运营管理,成为云服务被用户认可的关键因素之一。
|
|
|
|
|
|
云的负载管理和监控是一种大规模集群的负载管理和监控技术。在单个结点粒度,它需要能够实时地监控集群中每个结点的负载状态,报告负载的异常和结点故障,对出现过载或故障的结点采取既定的预案。在集群整体粒度,通过对单个结点、单个子系统的信息进行汇总和计算,近乎实时地得到集群的整体负载和监控信息,为运维、调度和成本提供决策。
|
|
|
|
与传统的集群负载管理和监控相比,云对负载管理和监控有新的要求:
|
|
|
|
.新增了应用粒度,即以应用为粒度来汇总和计算该应用的负载和监控信息,并以应用为粒度进行负载管理。
|
|
|
|
.监控信息的展示和查询现在要作为一项服务提供给用户,而不仅仅是少量的专业集群运维人员,这需要高性能的数据流分析处理平台的支持。
|
|
|
|
|
|
云的主要商业运营模式是采取按量计费的收费方式,即便对于私有云,其运营企业或组织也可能有按不同成本中心进行成本核算的需求。为了精确的度量“用了多少”,就需要准确地、及时地计算云上的每一个应用服务使用了多少资源,这称为服务计量。
|
|
|
|
服务计量是一个云的支撑子系统,它独立于具体的应用服务,像监控一样能够在后台自动地统计和计算每一个应用在一定时间点的资源使用情况。对于资源的衡量维度主要是:应用流量、外部请求响应次数、CPU时间、数据存储所占据的存储空间、内部服务API调用次数等。也可认为,任何应用使用或消耗的云的资源,只要可以被准确的量化,就可以作为一种维度来计量。
|
|
|
|
在计量的基础上,选取若干合适的维度组合,制定相应的计费策略,就能够进行计费。计费子系统还产生可供审计和查询的计费数据。
|
|
|